sklearn回归 预测下一期双色球
sklearn回归 预测下一期双色球
最近接到预测双色球的任务,因为随机性过大,尝试搭建DNN RNN LSTM 都有较大的LOSS(随机性太强)。故用SK里自带的回归来预测。
首先我们爬取数据
import requests
from bs4 import BeautifulSoup
from collections import Counter
# 获取内容
res = requests.get('http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html', timeout=30)
res.encoding = 'utf-8'
htm = res.text
# BeautifulSoup 解析内容
soup = BeautifulSoup(htm, 'html.parser')
# 获得url前缀
prefix_url = 'http://kaijiang.zhcw.com/zhcw/html/ssq/list'
# 获得总页数
total = int(soup.find('p', attrs={"class": "pg"}).find_all('strong')[0].text)
# 写入shuangseqiu.txt
local_file = open('shuangseqiu.txt', 'w')
red_num = [] # 所有红球
blue_num = [] # 所有蓝球
# 获取每页的开奖信息
for page_num in range(1, total + 1):
t_url = prefix_url + '_' + str(page_num) + '.html'
print(t_url)
res2 = requests.get(t_url, timeout=30)
res2.encoding = 'utf-8'
page_context = res2.text
page_soup = BeautifulSoup(page_context, 'html.parser')
if page_soup.table is None:
continue
elif page_soup.table:
table_rows = page_soup.table.find_all('tr')
for row_num in range(2, len(table_rows) - 1):
row_tds = table_rows[row_num].find_all('td')
ems = row_tds[2].find_all('em')
result = row_tds[0].string +','+ems[0].string+',' + ems[1].string + ',' + \
ems[2].string + ',' + ems[3].string + ',' + ems[4].string + ',' + ems[5].string + ',' + ems[
6].string
#格式为 日期,红球1,红球2,红球3,红球4,红球5,红球6,蓝球
local_file.write(result + '\n')
#print(result)
else:
continue
获取完后生成的shuangseqiu.txt 内容格式应为
2018-10-23,09,13,14,19,22,25,02
之后读取TXT数据 开始进行回归预测
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import datasets, linear_model
from sklearn.linear_model import LogisticRegression
# 读取上面获取的shuangseqiu.txt地址,指定分割符为逗号
df = pd.read_table('D:/untitled1/shuangseqiu.txt', header=None, sep=',')
# 第一列读取日期
tdate = sorted(df.loc[:, 0])
# 将每列球号码读出,写入到csv文件中,一共2229行数据,对应2229期数据
def readcsv(h_num, num, csv_name):
h_num = df.loc[:, num:num].values
h_num = h_num[2229::-1]
renum2 = pd.DataFrame(h_num)
renum2.to_csv(csv_name, header=None)
fp = open(csv_name)
s = fp.read()
fp.close()
a = s.split('\n')
a.insert(0, 'numid,number')
s = '\n'.join(a)
fp = open(csv_name, 'w')
fp.write(s)
fp.close()
# 调用取号码函数
readcsv('red1', 1, 'rednum1.csv')
readcsv('red2', 2, 'rednum2.csv')
readcsv('red3', 3, 'rednum3.csv')
readcsv('red4', 4, 'rednum4.csv')
readcsv('red5', 5, 'rednum5.csv')
readcsv('red6', 6, 'rednum6.csv')
readcsv('blue1', 7, 'bluenum.csv')
# 获取数据,X_parameter为numid数据,Y_parameter为number数据
def get_data(file_name):
data = pd.read_csv(file_name)
X_parameter = []
Y_parameter = []
for single_square_feet, single_price_value in zip(data['numid'], data['number']):
X_parameter.append([int(single_square_feet)])
Y_parameter.append(int(single_price_value))
return X_parameter, Y_parameter
# 用Sklearn自带的LinearRegression回归,并将结果取整
def linearmodel(X_parameters, Y_parameters, predict_value):
# Create linear regression object
lml = linear_model.LinearRegression()
lml.fit(X_parameters, Y_parameters)
predict_outcome = int(lml.predict(predict_value)+0.5)
predictions = {}
predictions['截距'] = lml.intercept_
predictions['斜率'] = lml.coef_
predictions['预测值'] = predict_outcome
return predictions
# 获取预测结果函数
def predicted_num(inputfile, num):
X, Y = get_data(inputfile)
predictvalue = 2229
result = linearmodel(X, Y, predictvalue)
print(str(num)+'号球' + " 截距为:", result['截距'])
print(str(num)+'号球' + " 斜率为:", result['斜率'])
print(str(num)+'号球' + " 下期号码为: ", result['预测值'])
# 调用函数分别预测红球、蓝球
predicted_num('rednum1.csv', 1)
predicted_num('rednum2.csv', 2)
predicted_num('rednum3.csv', 3)
predicted_num('rednum4.csv', 4)
predicted_num('rednum5.csv', 5)
predicted_num('rednum6.csv', 6)
predicted_num('bluenum.csv', 7)
运行结果如下图
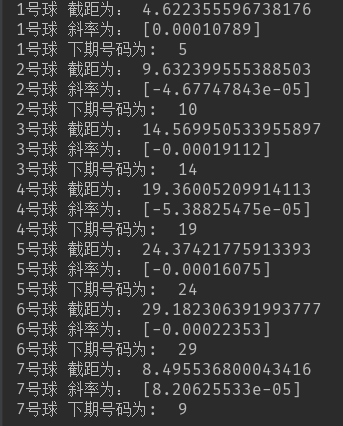
可以看出在2000+期的数据下进行回归 因为球的数据是按照从小到大的顺序 所以在大数据下回归结果分布近似为等间隔(5 10 15 20 25.。。这样 33个球所以近似6等分)。
红球一的回归线
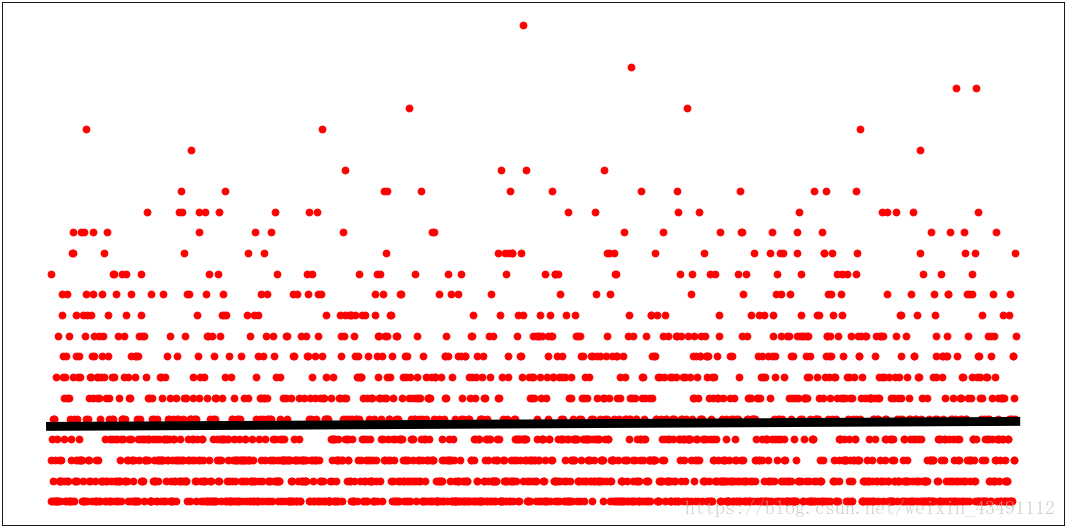
黑线为回归线 红球1-6从小到大排列,球1数小,均值小,所以回归偏下 最后为5
为了直观对比 下图选用红球6的回归图,可见其数据偏大,均值大,回归偏上

综上可看出预测数据接近各段均值 也从侧面证明了随机性很强, 所以想预测赚到钱还是算了><