Azure机器学习——Azure机器学习介绍
Azure机器学习介绍
- 一、什么是Azure机器学习?
- 二、Azure 机器学习的几个重要概念
- 工作区(Workspace)
- 数据存储(Datastore)
- 计算目标(Compute Targets)
- 本地资源
- Azure Machine Learning compute cluster
- 远程虚拟机
- 其他计算目标
- 模型训练(Model training)的几种方式
- 1. 适用于 python 的 Azure 机器学习 SDK
- 2. 设计器
- 3. CLI
- 模型管理和部署(Model management and deployment)
- 自动化机器学习(Automated machine learning)
- 机器学习管道(ML pipelines)
- 三、使用Azure 机器学习的6个好处
- 1. 安全方便地访问数据
- 2. 减少训练模型开销
- 3. 训练日志可视化
- 4. 加速模型迭代和调优
- 5. 快速部署和缩放
- 6. 支持多种框架
- 四、总结
Azure 机器学习是微软公有云Azure上一款基于Web页面的机器学习功能组件应用,不仅支持TensorFlow、PyTorch等主流的ML框架,同时支持Jupyter、VS Code等开发工具。
因为一些原因,Azure在中国由 世纪互联运营,称为Mooncake。与Azure Global相比, Mooncake上可用的Azure服务要少一些。随着国内公有云市场的快速发展,越来越多Azure Global服务落地到Mooncake中。比如 Azure 机器学习就在2020年1月落地中国。笔者经常在工作中用到Azure 机器学习这个服务,因此借着这个机会总结使用心得,通过理论和实战来给大家介绍这个服务。
**注意:本系列文章使用的Azure机器学习服务位于AzureChinaCloud。**Azure Global中的Azure机器学习服务和AzureChinaCloud中的使用方法几乎完全相同。细微不同之处将会在后续的使用中指明。
一、什么是Azure机器学习?
- Azure 机器学习是一种云服务,你可以使用它来训练、部署、自动化执行、管理和跟踪 ML 模型;
- 可用于任何类型的机器学习,从传统 ML到深度学习、监督式和非监督式学习;
- 支持Python和R语言进行ML开发,如果使用设计器,可以实现低代码量甚至无代码开发 ;
- 既支持在本地计算机上训练,也支持在云上训练;
- 安装SDK即可使用,支持常用的开源工具(如 PyTorch、TensorFlow 和 scikit-learn)。
二、Azure 机器学习的几个重要概念
Azure 机器学习是一个平台服务,功能非常强大,但也有很多专门定义的术语。提前理解其中的一些概念,对使用来说事半功倍。
工作区(Workspace)
要使用Azure 机器学习首先要创建一个工作区。
工作区是 Azure 机器学习的顶级资源,提供了一个集中的位置来处理使用 Azure 机器学习时创建的所有项目。
工作区保存所有定型运行的历史记录,包括日志、指标、输出和脚本的快照。 使用此信息可以确定哪个训练运行产生最佳模型。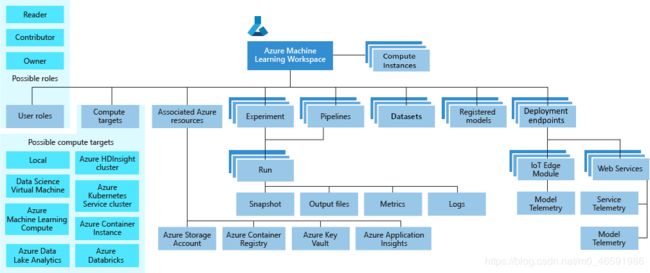
图1 工作区及其组件(图片来自官网)
图1显示了工作区的以下组件:
- 工作区包含Azure 机器学习计算实例、使用运行 Azure 机器学习所需的 Python 环境配置的云资源。
- 用户角色(User roles):对同一账户下的用户设置角色(所有者、参与者等),不同的角色拥有不同的权限,从而限制某些用户、团队或者项目对工作区资源的访问和修改。
- 试验(Experiment):用于构建模型,训练、部署模型都需要在某个试验下进行。
- 计算目标(Compute targets):用于运行试验。
- 管道(ML pipeline):可重复使用的工作流,可实现ML开发中的多人协作环境。
- 数据集(Datasets):管理用于模型定型和创建管道所需的数据。
- 模型注册(Registered models):如果有要部署的模型,则需创建一个已注册的模型。注册后的模型和数据集可以供工作区内的用户反复使用。
- 部署终结点(Deployment endpoints):使用已注册的模型和评分脚本来创建部署终结点。
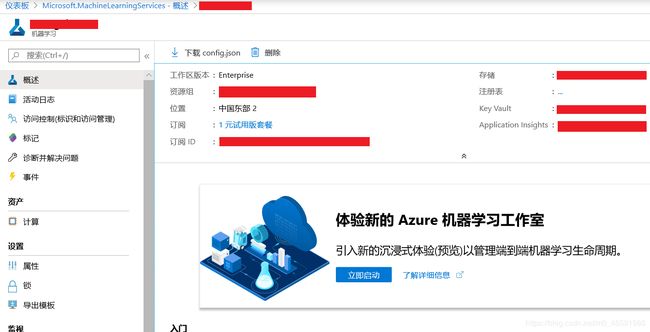
图2 工作区(portal)
图2是一个新创建的工作区,从上面可以看出,创建新工作区时,它会自动创建工作区使用的几个 Azure 资源:
- Azure 容器注册表:注册在 训练和部署模型时使用的docker 容器。 Azure机器学习在训练和部署中使用了容器化技术,对需要运行的每个 Python 环境创建一个docker镜像,镜像会被上传到工作区。对于后续运行,只要不更改脚本依赖项,将重复使用已上传的镜像。 由于容器启动的速度很快,因此训练可在更短的时间内获得更好的结果。
- 存储帐户:用作工作区的默认数据存储,工作区可以直接使用该账户内的数据进行训练。
- Azure 应用程序 Insights:存储有关模型的监视信息。
- Azure Key Vault:存储工作区所需的计算目标和其他敏感信息所使用的密钥。
数据存储(Datastore)
Azure Blob 存储是 Microsoft 提供的适用于云的对象存储解决方案。 Blob 存储最适合存储巨量的非结构化数据。你可以将海量数据、图片和文本存储在Azure Blob存储中。
在创建Workspace的过程中,会自动为该Workspace创建一个默认的Blob存储。
Workspace通过以下方式来获取该默认Blob存储中的数据:
ws = Workspace.get(name,subscription_id,resource_group)
datastore = ws.get_default_datastore()
本地和该默认Blob存储之间可通过下面代码进行数据交换:
datastore.upload_files() #将本地数据上传到Blob存储
datastore.download_files() #将Blob存储数据下载到本地
如果数据已经在其他的Blob存储(非默认)中,可以用以下方法将该Blob存储注册到该工作区:
blob_datastore = Datastore.register_azure_blob_container(container_name=‘Blob存储name’,datastore_name='...')
注册到工作区的Blob存储可以后续可以通过下面的代码进行访问:
datastore = Datastore.get(ws, datastore_name='...')
下图展示了Azure机器学习中本地、Blob存储和远程计算资源之间的数据存储和访问方式:
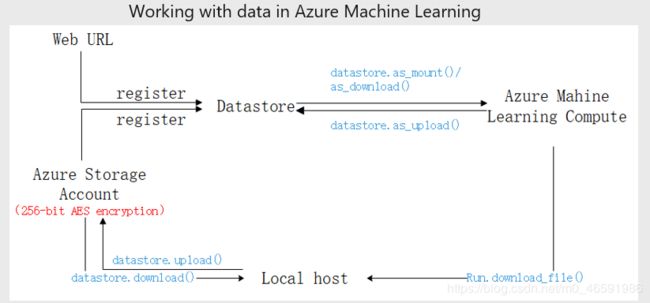
图3 数据在Azure机器学习中的存储和访问方式
计算目标(Compute Targets)
计算目标是训练和部署模型所需的计算资源,包括本地计算资源和云计算资源。
本地资源
由于安装SDK是使用Azure机器学习的一种方法,因此你可以在联网条件下在本地机器上训练和部署ML模型,充分利用本地计算资源。此时Azure机器学习起到了一种资源整合平台的作用。
出于某些原因,本地训练时Azure机器学习的某些功能会收到限制,比如不支持超参数优化,以及在运行自动化机器学习试验时,某些现成的算法在本地限制使用。

图4 本地运行Azure机器学习试验
Azure Machine Learning compute cluster
Azure 机器学习计算是一个托管的计算基础结构,可让用户轻松创建单节点或多节点计算实例。 该计算是在工作区区域内部创建的,是可与工作区中的其他用户共享的资源。
以下代码创建了一个Azure 机器学习计算:
aml_compute_target = "cpu-cluster-fcfn"
provisioning_config = AmlCompute.provisioning_configuration(
vm_size ="STANDARD_D2_V2",min_nodes = 0, max_nodes = 4)
aml_compute = ComputeTarget.create(ws, aml_compute_target, provisioning_config)
上面代码中:
- “aml_compute_target”是计算集群的名字
- “vm_size”是集群中虚拟机的规格,可以根据具体需求(vCPU核数、内存大小、GPU大小和数目)选择虚拟机的规格。
- “min_nodes”和“max_nodes”表示集群中节点的最小和最大数目。
当没有计算任务时,计算集群的运行节点数为“min_nodes”,如果“min_nodes”=0,那么集群中没有节点在运行。当提交了计算任务后,计算集群会根据任务自动缩放节点数,最多可自动缩放的节点数为“max_nodes”。

图5 计算节点准备中
自动缩放的节点的功能使得Azure 机器学习计算可以支持并行计算任务,并且可以在没有任务时自动关闭所有计算节点,某些情况下可以大大节省计算开销。
远程虚拟机
Azure 机器学习还支持将自己的计算资源附加到工作区。 这种类型的资源类型是任意远程 VM,只要可从 Azure 机器学习访问。 该资源可以是 Azure VM,也可以是组织内部或本地的远程服务器。 具体而言,在指定 IP 地址和凭据(用户名和密码,或 SSH 密钥)的情况下,可以使用任何可访问的 VM 进行远程运行。
其他计算目标
Azure 机器学习支持的训练计算目标还包括:Azure Databricks, Azure HDInsight, Azure Data Lake Analytics, Azure Batch等。
Azure 机器学习支持的部署目标包括:Local web service、 Azure Machine Learning compute instance web service、Azure Kubernetes Service (AKS), Azure Container Instances, Azure Machine Learning compute clusters, Azure IoT Edge, Azure Data Box Edge等。
模型训练(Model training)的几种方式
Azure 机器学习提供多种方法来训练模型,从使用 SDK 的代码优先解决方案到低代码解决方案(例如自动化机器学习和可视化设计器)。

图7 Azure机器学习常用使用方式
下面介绍使用Azure 机器学习训练模型的3种方式:
1. 适用于 python 的 Azure 机器学习 SDK
Python SDK是构建和运行Azure机器学习工作流的一种常用方法。你可以在 Jupyter Notebooks、Visual Studio Code 或你偏爱的 Python IDE 中使用它。更多关于Azure机器学习Python SDK的介绍请查看【什么是适用于 Python 的 Azure 机器学习 SDK?】。
Python SDK提供多种方法来训练模型,每个方法都具有不同的功能:
1.1 运行配置(Run configuration):训练模型的一般方法,使用训练脚本并运行配置。需要自己在训练脚本中加上Azure机器学习配置信息,适合于小型任务,如下图所示。
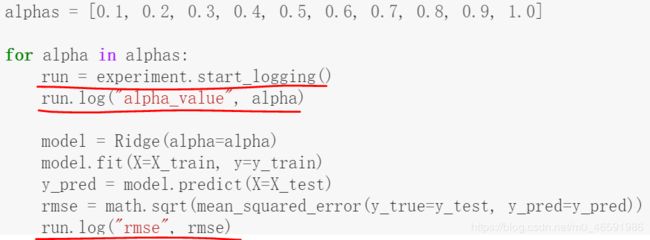
图7 手动在代码中添加运行配置
训练完成后,run记录的一些日志比如运行时间、超参数历史记录以及模型性能指标等结果便可以显示到Azure的portal上。
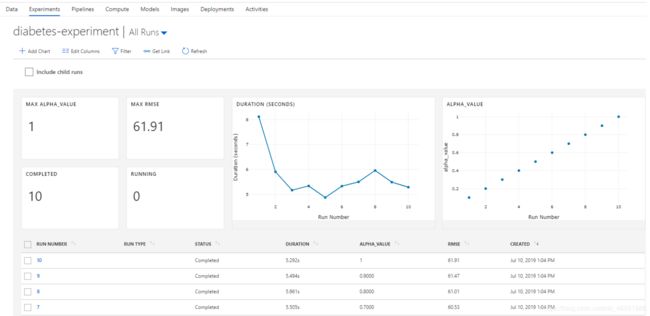
图8 运行记录示例(图片来自GitHub)
1.2 估计器(Estimators):利用估计器类,可以轻松地根据常用机器学习框架来训练模型,支持Scikit-learn、 PyTorch、 TensorFlow和Chainer等估计器类。无需在代码中输入配置信息,可如下直接提交脚本计算。
from azureml.train.sklearn import SKLearn
script_params = {'--data-folder': ds.path('mnist').as_mount(),'--regularization': 0.5}
#将SKLearn替换为其他框架,便可以支持其他框架构建的模型
est = SKLearn(source_directory=script_folder,script_params=script_params,
compute_target=compute_target, #指定计算目标
entry_script='train.py' #需要运行的脚本,和本地运行下代码一样
)
1.3 自动化机器学习(Automated ML): 可通过自动化特征工程、算法选择和超参数优化来节省时间和资源。 使用自动化机器学习时,无需担心手动修改运行配置。

图9 自动化特征工程和算法选择
1.4 机器学习管道(ML pipeline):管道将一个工作流分成多个 ML 阶段(数据准备、训练、批量评分、部署),保存每个阶段的输出,管道中的每个阶段可以利用其他阶段上一步运行的输出单独运行,从而实现多人协作环境。
2. 设计器
Azure 机器学习设计器(预览)提供了一个简单的入口点,可用于构建概念证明,适合几乎无代码经验的用户。 它允许你使用拖放基于 web 的 UI 来训练模型。 你可以使用 Python 代码作为设计的一部分,或在不编写任何代码的情况下定型模型。
图10 设计器(图片来自官网)
3. CLI
Azure 命令行接口 (Azure CLI) 是一个用来创建和管理 Azure 资源的环境。 Azure CLI 可用于各种 Azure 服务,可用来快速地操作 Azure,尤其是用于实现自动化操作。
机器学习 CLI 为使用 Azure 机器学习的常见任务提供命令,通常用于脚本和自动化任务。 例如,在创建训练脚本或管道后,你可以使用 CLI 按计划启动定型运行,或在用于定型的数据文件更新时启动。 对于定型模型,它提供了用于提交训练作业的命令。 它可以使用运行配置或管道提交作业。
另外如果你使用R语言开发ML模型,Azure机器学习还提供了适用于 R 的 SDK。如果你想将Azure机器学习封装到自己的机器学习平台中,可以参考机器学习 REST API。
由于使用Python SDK比较灵活,功能丰富。所以后续的章节我主要使用Python SDK+Jupyter Notebook的方式来介绍Azure机器学习。
模型管理和部署(Model management and deployment)
Azure 机器学习使用机器学习操作(MLOps)方法来管理模型的生命周期。机器学习操作(MLOps)基于DevOps原则和提高工作流效率的实践。 例如,持续集成、交付和部署。
MLOps 将这些主体应用到机器学习过程中,目的是:1)更快地试验和开发模型2)更快地将模型部署到生产环境3)质量保证。
Azure 机器学习提供以下 MLOps 功能:
- 创建可重复的 ML 管道。 机器学习管道使你可以为数据准备、定型和评分过程定义可重复和可重复使用的步骤。
- 为定型和部署模型创建可重用的软件环境。
- 从任何位置注册、打包和部署模型。 您还可以跟踪使用该模型所需的关联元数据。
- 捕获用于端到端 ML 生命周期的管理数据。 记录的信息可能包括发布模型的人员、发生更改的原因以及在生产环境中部署或使用模型的时间。
- 通知和警报 ML 生命周期中的事件。 例如,试验完成,模型注册,模型部署和数据偏移检测。
- 监视 ml 应用程序的操作和 ml 相关的问题。 比较定型与推理之间的模型输入,探索特定于模型的指标,并提供有关 ML 基础结构的监视和警报。
- 通过 Azure 机器学习和 Azure Pipelines自动化端到端 ML 生命周期。 使用管道,可以频繁地更新模型、测试新模型,并随其他应用程序和服务一起不断推出新的 ML 模型。
自动化机器学习(Automated machine learning)
自动化机器学习,也称为自动 ML,是自动执行机器学习模型开发、迭代任务的过程。
在训练过程中,Azure 机器学习会创建多个并行管道,尝试使用不同的算法和参数。 一旦到达试验中定义的退出条件,它就会停止。
- 自动化机器学习支持分类、回归和时间序列分析这三种任务。
- 对每种任务,自动化机器学习都提供了10种以上算法供训练选择。
- 支持自动数据前处理(缺失值、标准化、归一化)和自动特征工程
- 提供多种交叉验证方式和模型度量指标。

图11 自动化机器学习(图片来自官网)
机器学习管道(ML pipelines)
Azure 机器学习管道是完整的机器学习任务的可独立执行的工作流。 子任务封装为管道中的一系列步骤。
一个机器学习任务可以分为数据准备、训练配置、多次重复训练和验证、模型部署等子任务。这些子任务可以有机地封装到机器学习管道中,成为管道中的一系列步骤,并且这些步骤之间保持独立性。
独立步骤允许多人同时在同一管道上操作,而无需过多的计算资源。 单独的步骤还可以简化每个步骤使用不同的计算类型/大小。
管道设计好以后,通常还会对管道中的某些步骤进行循环优化。 重新运行管道时,运行将跳转到需要重新运行的步骤,如更新的训练脚本。 将跳过不需要重新运行的步骤。 对于管道中某个步骤, 如果运行配置未更改并且上次运行的结果设置为可重复使用,那么管道运行到此步骤直接使用之前运行的结果,这种重复使用功能可以在管道优化过程中跳过运行成本高昂且耗时较高的步骤,如数据引入和转换。
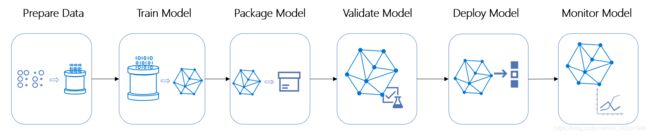
图12 机器学习管道(图片来自官网)
三、使用Azure 机器学习的6个好处
Azure 机器学习时一个功能强大的机器学习平台。机器学习工作区是这个平台的顶级资源中心。通过将数据、计算资源和模型注册到机器学习工作区,使得反复使用这些资源变得更加方便和安全。此外,Azure 机器学习提供的自动化机器学习方法、机器学习管道以及与主流训练框架的结合,加速了在Azure 机器学习进行机器学习开发的速度。
综上,Azure 机器学习的优势总结如下:
1. 安全方便地访问数据
保存在AzureBlob存储中的数据通过256位AES加密。通过Datastore Azure 机器学习可以轻松访问到AzureBlob存储中的数据,并且在数据在传输过程中也是受到保护的。
2. 减少训练模型开销
云上各种规格的CPU和GPU的虚拟机及其集群大大加速了模型训练过程。计算集群的自动缩放节点的功能自动实现了计算资源即用即开、用完关闭,在一定程度上减少了开销。
3. 训练日志可视化
不管使用何种训练框架,Azure 机器学习都能够将模型训练过程中的日志(迭代次数、超参数、运行时间、模型度量值等)记录下来,并且自动在网页中进行展示。
4. 加速模型迭代和调优
自带的超参数调优和自动化机器学习可以加速模型的迭代和优化,减小模型训练时间。
5. 快速部署和缩放
提供了Azure Container Instance, Azure Kubernetes Service, FPGA, IoT Edge devices等多种部署方式,针对不同的使用需求,提供了自动缩放功能。
6. 支持多种框架
SDK内在结合了主流的ML、DL开发框架,包括Scikit-learn、 PyTorch、 TensorFlow、Chainer,也支持ONNX runtime进行部署。
四、总结
- 介绍了Azure机器学习服务,该服务给机器学习开发者提供了一个使用便捷、功能丰富的平台。
- 介绍了Azure机器学习服务的几个重要概念。Azure机器学习工作区是该服务的顶级资源中心。
- 总结了使用Azure机器学习服务进行开发的几个好处。