区块链对人工智能的变革:去中心化将带来数据新范式
 抢沙发
抢沙发
摘要:本文基于我个人在人工智能和区块链研究方面的经验,描述了区块链技术可以如何辅助人工智能。二者结合一处即发!区块链技术——尤其是行星尺度的——可以帮助实现人工智能和数据团体长期以来的一些梦想,并打开一些机会。
关键词: 区块链 人工智能
关键词: 区块链 人工智能
近年,从围棋到人类水平的语音识别,人工智能(AI)研究者终于在他们几十年一直努力探索的领域取得了突破。取得突破进展的关键一点是研究者们可以收集巨量的数据并「学习」这些数据,从而将错误率降低到可接受范围以内。






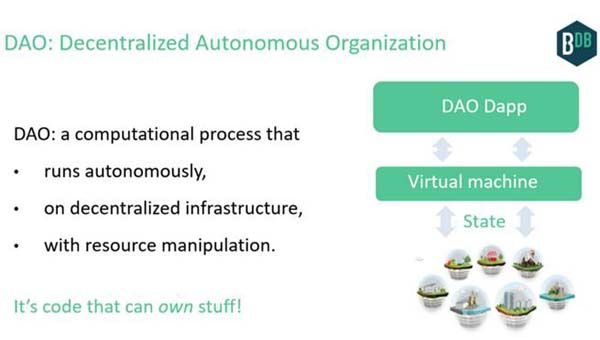

简而言之,大数据大为改观了人工智能的发展,将其推到一个几乎难以置信的高度。
区块链技术同样能够变革人工智能——当然以它自己的特定方式进行。部分将区块链用于人工智能方式目前还很单一,比如在人工智能模型上进行审计跟踪(audit trail)。有些应用几乎是难以置信的,比如拥有自己的人工智能——人工智能去中心化自治组织(AI DAO)。这些都是发展的机会。这篇文章将具体探讨这些应用。
作为蓝海数据库的区块链(blockchain)
在讨论这些应用之前,我们先来了解一下区块链与传统大数据的分布式数据库(比如 MongoDB)之间的差异。
我们可以将区块链视为「蓝海」数据库:它们逃离了现有市场上有鲨鱼竞争的「红海」,而是没有市场竞争的蓝海。蓝海的着名例子是视频游戏主机 Wii(妥协了原始性能,但添加了新的互动模式),或 Yellow Tail 葡萄酒(忽略了葡萄酒爱好者矫揉造作的繁复规范,使葡萄酒更容易被啤酒爱好者接受)。
根据传统的数据库标准,传统的区块链(如比特币)是糟糕的:低吞吐量、低容量、高延迟、糟糕的查询支持等。但在蓝海思维中,这是可以接受的,因为区块链引入了三个新特性:去中心化/共享控制、不变性/审计跟踪和本地资产/交换。受比特币启发的人们乐于忽视传统的以数据库为主的缺点,因为这些新的好处有可能以全新的方式影响整个行业和社会。
这三个新的「区块链」数据库特征对于人工智能应用也有潜在的借鉴意义。但是大多数实际的人工智能工作涉及大量的数据,如大数据集训练或高吞吐量流处理(stream processing)。因此,对于区块链在人工智能领域的应用,需要具有大数据可扩展性和查询的区块链技术。像 BigchainDB 这样的新兴技术及其公共网络 IPDB(Internet Pinball Machine Database)正是如此。这使得获得区块链的好处时不再需要舍弃传统的大数据数据库的优点。
人工智能区块链的概述
大规模的区块链技术解锁了其在人工智能应用上的潜力。从区块链的三点好处开始,我们来探讨一下这些潜力。
这些区块链的好处为人工智能实践者带来了以下机会:
去中心化/共享控制激励了数据共享:
(1)带来更多的数据,因此可以训练出更好的模型。
(2)带来新的定性数据,因此新的定性模型。
(3)允许共享控制人工智能的训练数据和模型。
不变性/审计跟踪:
(4)为训练/测试数据和模型提供了保证,提高数据和模型的可信度。数据也需要声誉。
本地资产/交换:
(5)使训练/测试数据和模型成为知识产权(Intellectual Property/IP)资产,这可以带来去中心化的数据和模型交换。能更好地控制数据的上游使用。
还有一个机会:(6)人工智能与区块链解锁人工智能去中心化自治组织(AI DAO/Decentralized Autonomous Organizations)的可能性。这些人工智能可以积累财富。在很大程度上,它们就是软件即服务(Software-as-a-Service)。
区块链还可以以更多的方式帮助人工智能。反过来,人工智能可以有许多方法帮助区块链,如挖掘区块链数据(例如 Silk Road 调查)。这是另外的讨论话题: )
许多这些机会是关于人工智能与数据的特殊关系。让我们先来探讨一下。在此之后,我们将更详细地探讨区块链在人工智能领域的应用。
人工智能 & 数据
在这里,我将描述现代人工智能为了产生好的结果是怎样利用大量数据的。(虽然不总是这样,但它很常见并值得描述。)
「传统」人工智能 & 数据的历史
当我在 90 年代开始做人工智能研究时,一个典型的方法是:
找到一个固定的数据集(通常很小)。
设计一种算法来提高性能,例如为支持向量机分类器设计一个新的核函数,以提高 AUC 值。
在会议或期刊上发表该算法。「最小可发表的改进程度」只需要相对提高 10%,只要你的算法本身足够花哨。如果你的提高程度在 2 倍-10 倍 之间,你可以发表到该领域最好的期刊了,特别是如果算法真的很花哨(复杂)的话。
如果这听起来很学术,那是因为它本身就很学术。大多数人工智能工作仍然在学术界,虽然有实际的应用场景。在我的经验中,许多人工智能子领域中都是这样的,包括神经网络、模糊系统(fuzzy system)、进化计算(evolutionary computation),甚至不那么人工智能的技术,如非线性规划或凸优化。
在我第一篇发表的论文《Genetic Programming with Least Squares for Fast, Precise Modeling of Polynomial Time Series》(1997)中,我自豪地展示了我新发明的算法与最先进的神经网络、遗传编程等相比在最小的固定数据集上有最好的结果。
走向现代人工智能 & 数据
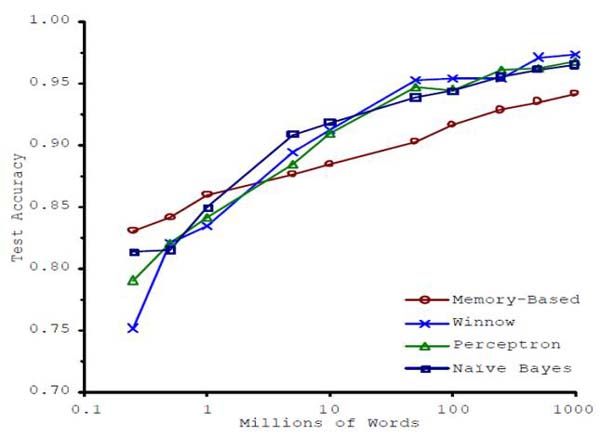
但是,世界变化了。2001 年,微软研究人员 Banko 和 Brill 发表了一篇有着显着成果的论文。首先,他们描述了大多数自然语言处理领域的工作基于小于 100 万字的小数据集上的情况。在这种情况下,对于旧/无聊/不那么花哨的算法,错误率为 25%,如朴素贝叶斯(Naive Bayes)和感知器(Perceptron),而花哨的较新的基于记忆的算法(memory-based algorithms)实现了 19%的错误率。这是下面最左边的四个数据点。
到目前为止,还没有什么让人惊讶的。但是,Banko 和 Brill 揭示了一些不同寻常的东西:当你添加更多的数据——不仅仅是一点数据,而是多达数倍的数据——并保持算法相同,那么错误率会持续下降很多。到数据集大到三个数量级时,误差小于 5%。在许多领域,这是 18%到 5%之间的差异,但是只有后者对于实际应用是足够好的。
此外,最好的算法是最简单的;最糟糕的算法是最花哨的。来自 20 世纪 50 年代的无聊的感知器算法正在击败最先进的技术。
现代人工智能 & 数据
Banko 和 Brill 并不是唯一发现这个规律的人。例如,在 2007 年,谷歌研究人员 Halevy、Norvig 和 Pereira 发表了一篇文章,显示数据可以如何「不合理地有效」跨越许多人工智能领域。
这就像原子弹一样冲击了人工智能领域。
数据才是关键!
于是收集更多的数据的竞赛开始了。需要大量的努力才能获得好数据。如果你有资源,就可以得到数据。有时甚至可以锁定数据。在这个新世界里,数据是壕沟,人工智能算法是一种商品。出于这些原因,「更多数据」是谷歌、Facebook 等公司的关键。
「越多数据,越多财富」——每个人
一旦你了解这些动态,具体行动就有了简单的解释。谷歌收购卫星成像公司不是因为它喜欢卫星图像;而谷歌又开放了 TensorFlow。
深度学习直接适用于这种情境:如果给定一个足够大的数据集,它能弄清楚如何获取相互影响和潜在变量。有趣的是,如果给予相同的大规模数据集,来自上世纪 80 年代的反向传播神经网络有时能与最新的技术媲美。参考论文《Deep Big Simple Neural Nets Excel on Handwritten Digit Recognition》。所以说数据才是关键。
作为一个人工智能研究员我自己成熟的年龄是类似的。当我遇到现实世界的问题时,我学会了如何吞下我的骄傲,放弃「炫酷」的算法,仅仅满足能够解决手头上问题,并学会了热爱数据和规模。我们将重心从自动化的创意设计转向了「无聊」的参数优化;同时当用户要求我们从 10 个变量增加到 1000 和变量时,我们在匆忙应对中变得不那么无聊——我的第一家公司 ADA(1998–2004)的情况就是这样。我们将重心从华丽的建模方法转移到超级简单但可完全扩展的机器学习算法(如 FFX);当用户要求从 100 个变量增加到 100000 个,从 100 亿蒙特卡洛样本增加到 10 亿(有效样本),我们同样不无聊——这发生在我的第二家公司 Solido(2004—至今)。即使是我第三家也是目前的公司的产品 BigchainDB,也体现了对规模的需要(2013—至今)。扩展功能,扩大规模。
机会 1:数据共享→更好的模型
总之:去中心化/共享控制能促进数据共享,这反过来又带来更好的模型、更高的利润/更低的成本/等。阐述如下:
人工智能热衷数据。数据越多,模型越好。然而,数据往往是孤立的,尤其是在这个新世界里,数据可能是难以逾越的鸿沟。
但是如果有足够的正面效益,区块链鼓励传统的独立体间数据共享。区块链的去中心化本质鼓励数据共享:如果没有单一的实体控制存储数据的基础设施,共享就会有更少的冲突。之后我会举出更多好处。
数据共享可能发生在一个企业中(如在区域办公室)、一个生态系统内(如一个「财团」数据库)或整个星球(例如共享行星数据库,即公开区块链)。
下面给出了每个对应的例子:
企业内:使用区块链技术来合并来自不同区域办公室的数据,因为它能降低企业审核自己数据的成本,并和审计员共享数据。随着新的数据到位,企业可以建立人工智能模型,例如,相比以前只建立在区域办公室水平的模型,新模型能更好地预测客户流失的模型。每个区域办公室的「数据集市」?
生态系统内:竞争对手(例如,银行或唱片公司)过去永远不会分享他们的数据。但现在可能坦率地展示,结合几个银行的数据,可以做更好的模型以预防信用卡欺诈。或者供应链机构通过区块链共享数据,对供应链中更早地数据使用人工智能,可以更好地确定在供应链中导致失败的根本原因。例如,大肠杆菌的菌株究竟出现在哪里?
在整个星球范围内(公共区块链数据库):考虑不同生态系统之间的数据共享(例如能源使用数据+汽车零部件供应链数据);或个人参与者在一个行星尺度的生态系统(如网络)。更多的数据来源可以改善模型。例如,在中国一些工厂能源使用量的峰值可能与非法汽车零部件花了一天在市场运输有关。总的来说,我们看到公司汇总数据,进行洗白,重新包装并出售的行径;从 Bloomberg 终端到几十(或几百个)初创企业通过 http APIs 销售数据。我在稍后阐述这一未来。
敌人们共享他们的数据来喂养一个人工智能。2016 多么有趣!
机会 2:数据共享→新模型
在某些情况下,当独立的数据被合并,你不只是得到一个更好的数据集,还得到一个新的数据集。这能带来全新的模型,从中你可以收集新的见解、进行新的业务应用。也就是说,你可以做一些你以前不能做的事情。
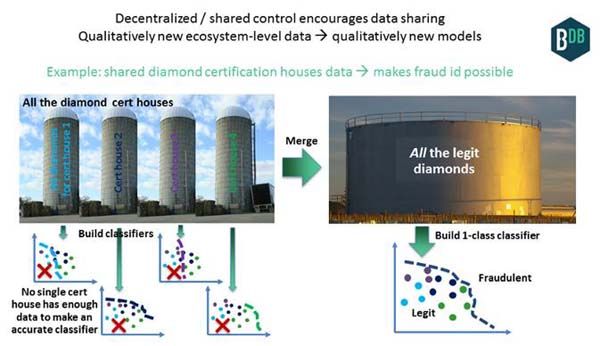
这里有一个用于识别钻石欺诈例子。如果你是一家提供钻石保险的银行,你想开发一个识别钻石是否欺诈的分类器。在地球上有四个值得信赖的钻石认证实验室(当然取决于你问谁)。如果你只能访问其中一个实验室的钻石数据,那么你就看不到其他三家的数据,你的分类器可能很容易把其他家的钻石标记为欺诈(见下图,左)。你的误报率会使你的系统不可用。
相反如果区块链促进四个认证实验室共享他们的数据,你就有所有的合法数据,从利用它们你将建立一个分类器(右下)。任何输入的钻石,例如在 eBay 上看到,将遍历系统,并与分类器中的每一类进行比较。该分类器可以检测真实的欺诈行为,避免误报,从而降低误报率,使保险供应商和认证实验室受益。这可以简单地作为一个查找框,即不需要人工智能。但使用人工智能进一步提高了它,例如基于颜色、克拉预测价格,然后用「价格和价值的接近程度」作为主要欺诈分类器的输入。
这里的第二个例子是,去中心化系统中的一个适当的 token 激励机制(token-incentive scheme)可以激励先前未标记的数据集得到标记,或者是以一个更经济的方式进行标记。这基本上就是去中心化的 Mechanical Turk(亚马逊的众包服务平台)。有了新标签,我们就得到了新数据集;我们使用新数据集进行训练以获得新模型。第三个例子是,token 激励机制可能会导致来自物联网设备的直接数据输入。这些设备控制数据并可以将其交换为资产,比如能源。同样地,这个新数据可能会带来新模型。
囤积 vs 分享?此处的两个相反动机之间有一个紧张关系。一个是囤积数据——即「数据是新护城河」的观点;另一个是共享数据,为了得到更好的/新的模式。分享行为必须要有一个超过「护城河」效益的足够驱动力。技术驱动力是得到更好的模式或新的模式,但这个驱动力必须要有商业价值。可能带来的利益包括降低原材料或供应链中的保险储蓄诈骗;将 Mechanical Turk 作为赚钱副业;数据/模型交换;或是对抗强大的核心玩家的集体行动,就像唱片公司合力对抗苹果的 iTunes 一样,等等;它需要创造性的商业策略。
中心化 vs 去中心化?即使一些组织选择分享数据,他们也可以在无需区块链技术的情况下这样做。例如,他们可以简单地将其囤入 S3 实例中并提供出 API。但在某些情况下,去中心化带来了新的好处。首先是基础设施的直接共享,这样共享联盟中的任一组织就不会自己控制所有的「共享数据」。(这在几年前是一个主要的障碍,那时唱片公司尝试过为一个公共注册系统而合作。)另一个好处是让数据 & 模型转变为资产变得更加容易,然后这样可以进行外部授权以获利。我下文会详细阐述这一点。
如前所述,数据 & 模型共享会发生在三个层次:在一家企业内部(跨国公司的情况比你想象的要难);在一个生态系统或联合体中;或在这个星球中(相当于成为一个公用事业)。让我们更深入地探索这个行星尺度的分享吧。
机会 2A:行星层次的新数据 → 行星层次的新见解
整个星球层面的数据共享可能是最有趣的。让我们进一步深入这个问题。
IPDB 是全球范围的结构化数据,而不是零碎的。将万维网视为互联网上的文件系统;IPDB 是其数据库副本。(我认为我们没有看到更多相关工作的原因,在于语义上的 Web 工作试图以升级文件系统的角度去实现它。但通过「升级」文件系统来建立数据库是相当困难的!如果从一开始就说你正在建立一个数据库并设计它之类的话,这样更有效果。)「全局变量(Global variable)」会得到更加字面上的解释 : )(注:global 也有「全球」的意思)
那么,当我们有一个行星尺度的、像 IPDB 那样的数据库共享服务,或是怎样一番景象?我们有几个参考点。
第一个参考点是,在企业界的公共数据管理与重新包装使其更易被消费方面,从简单的天气或网络时间的 API,到股票和货币之类的金融数据 API,最近已经有一个十亿美元的市场了。想象一下,所有这些数据都可通过一个单一的数据库以一种类似的结构化方式(即使只是一个 API 的通行证)进行访问。就好像有了 1000 个彭博社。不用担心受制于某个单一的实体。
第二个参考点来自于区块链,即通过一个区块链来「oraclize」外部数据使其易于消费的概念。但我们可以 oraclize 一切。去中心化的彭博社只是开始。
总体而言,我们得到了数据集与数据源多样性的一个全新规模。因此从性质上讲,我们有了新数据。行星层次的结构化数据。由此从性质上讲,我们可以建立新的模型,使得之前没有联系的输入 & 输出之间产生关联。有了模型,我们将获得性质上的新见解。
我希望此处可以说得更具体一些,但是它太新了,我想不出任何例子。不过,它们会出现的!
还会有一个 Bot 角度的。我们一直假定区块链 API 的主要消费者会是人类。但如果是机器呢?现代 DNS 的创造者 David Holtzman 最近说,「IPDB 是人工智能的饲料(kibbles)」。分析一下,这是由于 IPDB 实现并鼓励了行星层次的数据共享,而人工智能实在是很喜欢吃数据。
机会 3:数据 & 模型中的审计跟踪使预测结果更加值得信赖
此应用针对的是这样一个事实:如果你使用垃圾数据进行训练,那么你将得到一个垃圾模型。数据测试同理:垃圾进,垃圾出。
垃圾可能来自于恶意行事者/可能篡改了数据的拜占庭式故障。想一下大众汽车的排放丑闻。垃圾也可能来自于无恶意的演员/崩溃式故障,例如有缺陷的物联网传感器、一个出错的输入数据,或是环境辐射引起的一点波动(没有良好的纠错行为)。
你怎么知道 X / y 训练数据没有缺陷?现场使用呢,在现场输入的数据上运行模型的情况?那么模型预测(yhat)呢?简而言之:进入模型以及来自模型的数据都经历了什么?数据也要名誉。
区块链技术可以给以帮助。下面讲具体做法。在过程的每一步中都建立模型,并在该领域运行模型,该数据的创造者可以简单地为模型加上区块链数据库的时间戳,包括数字签字以声明「我相信这一点上的此数据/模型是没问题的」。再具体一点就是…
建模来源:
传感器数据(包括物联网)。你相信你的物联网传感器对你说的话吗?
训练输入/输出(X / y)数据。
建模本身,比如你可以使用可信执行(Trusted execution)基础设施,或是进行复核计算的 TrueBit 式的市场。至少有建模型收敛曲线的建模证据(例如 nmse* *vs. epoch)。
模型本身。
测试过程/该领域中的来源:
测试输入(X)数据。
模型仿真。可信执行、TrueBit 等。
测试输出(yhat)数据。
我们可以在模型的建立与应用过程中得到其来源。其结果是更可信的人工智能训练数据 & 模型。我们还可以拥有这样的连锁结构。模型的模型,就像在半导体电路设计中那样一直到底。现在,一切都有出处了。
好处包括:
(在最广泛的意义上)捕捉所有层次上的数据供应链中的漏洞。例如你可以判断传感器是否在说谎。
你知道数据和模型的来历,并且是以密码验证的方式。
您可以在数据供应链中发现漏洞。这样一来,如果发生错误,我们能更好地了解其位置以及如何应对。你可以将其当做银行式的和解,不过针对的是人工智能模型。
数据有了名誉,因为多双眼睛都可以检查那个源,并甚至声称自己的数据判断如何有效。相应地,模型也有了声誉。
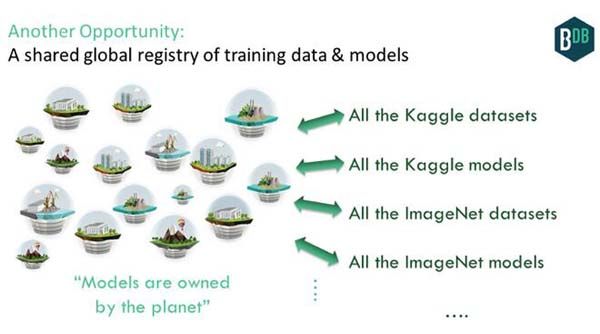
机会 4:训练数据 & 模型全球共享注册系统
但是如果我们有一个可以方便管理另一个数据集或数据馈送(免费或其他)的全球数据库呢?这包括一系列出自各种机器学习比赛的 Kaggle 数据集、斯坦福 ImageNet 数据集及其他不计其数的数据集。
这正是 IPDB 可以做到的。人们可以提交数据集并使用其他人的数据。数据本身会在一个去中心化的文件系统中,就像 IPFS ;而元数据(及数据指针本身)将会在 IPDB 中。我们会获得一个人工智能数据集的全局共享空间。这有助于实现打造数据开放社区的梦想。
我们无需停留在数据集层面;我们也可以包括从这些数据集中建立起来的模型。抓取和运行他人的模型并提交自己的模型应该很容易。一个全球性的数据库可以大大方便这一过程。我们可以得到行星所拥有的模型。
机会 5:作为 IP 资产的数据 & 模型→数据 & 模型交换
让我们基于训练数据和模型的「全局共享注册系统」这一应用。数据 & 模型可以成为公共共享内容的一部分。但它们也可以进行购买与出售!
数据和人工智能模型可以被用来作为知识产权(IP)资产,因为它们受到版权法的保护。这意味着:
如果你创建了数据或模型就可以要版权。无论你是否想进行任何商业行为。
如果你拥有数据或模型的版权,那么你可以将使用权限授权给其他人。例如,你可以将你的数据授权给其他人来构建他们自己的模型。或者你可以将你的模型授权给其他人并计入他们的移动应用程序。次级授权、次次级授权等也是可能的。当然你也可以从他人那里获得数据或模型授权。
我认为能够拥有一个人工智能模型的版权并进行授权,这是相当棒的。数据已被公认为是一个潜在的巨大市场;模型会紧跟其上。在区块链技术之前是可以对数据 & 模型宣称版权与许可的。相关法律的出台已经有一段时间了。但区块链技术使它变得更好,因为:
版权声明提供了一张防篡改的全球公共注册表;你的版权声明是数字化/加密了的签名。此注册表也可以包括数据 & 模型。
对于你的授权交易,它也提供了一张防篡改的全球公共注册表。这次不仅仅是数字签名;相反除非你有私钥,否则你甚至不能转让权利。权利转移是作为一个区块链式的资产转换进行的。
在我 2013 年致力于使用 ascribe 来帮助数字艺术家们获得报酬的过程中,区块链上的 IP 与我心心相映。最初的方法有规模和许可灵活度的上的问题。现在这些都已经被克服,我最近写的相关文章有谈到这点(https://medium.com/ipdb-blog/a-decentralized-content-registry-for-the-decentralized-web-99cf1335291f#.v3jl6f9om)。这项技术包括:
Coala IP 是一个灵活的、区块链友好的 IP 协议。
IPDB(及 BigchainDB)是一个公共的区块链共享数据库,用来存储权利信息及其他网络规模的元数据。
IPFS +物理存储(比如 Storj 或 Filecoin)是一个去中心化的文件系统,用来存储大数据 & 模型斑点。
有了这个,我们就有了数据与模型作为 IP 资产。
例如使用 ascribe 时,我声明了于几年前建立的一个人工智能模型的版权。该人工智能模型是一个决定使用哪种模拟电路拓扑的 CART(决策树)。这是它的密码防伪证书(Certificate of Authenticity /COA)。如果你想从我这获得一个许可版本,给我发电子邮件即可: )
一旦我们有了数据和模型作为资产,我们就可以开始进行资产交换。
一次交换可以是中心化的,像 DatastreamX 处理数据那样。但到目前为止,它们确实只能使用公共数据源,因为很多企业觉得分享的风险比效益要多。
那么去中心化的数据 & 模型交换呢?对「交换」过程中所共享的数据进行去中心化,这样做有新的好处。去中心化过程没有一个单一的实体去控制数据存储基础设施,也没有谁拥有什么的分类账本,如前所述,这更易于组织合作或数据共享。比如用于 Deep Nets 的 OpenBazaar。
有了这样一个去中心化的交换,我们会看到一个真正的开放数据市场的出现。这实现了数据与人工智能团体间的(包括你的)长期以来的一个梦想。
当然在这些交换之上也会产生一些基于人工智能算法的交易:用人工智能算法购买人工智能模型。人工智能交易算法甚至会变成这个样子:购买算法来交易人工智能模型,然后自己进行更新!
机会 5A:在上游控制你的数据 & 模型
这是之前应用的重复。在你登录 Facebook 时就授予了它非常具体的权利,包括对你输入进其系统中的任何数据的处置权限。它会对你的个人资料施加许可。
当一个音乐家用一个标签来签名时,他们就是在授予标签非常具体的权利:编辑音乐、分发音乐等等。(通常该标签会试图攫取所有版权,这个任务非常繁重,但那是另一回事了!)
人工智能数据和人工智能模型也同理。当你创建可用于建模的数据以及创建模型本身时,你可以预先指定许可从而在上游限制其他人的使用权限。
对于所有用例,从个人资料到音乐、从人工智能数据到人工智能模型,区块链技术使这个过程变得更加容易。在区块链数据库中,你是将权限作为资产,例如一个读取权限或查看某条数据/模型的权利。你作为权利持有人可以将这些作为资产的权限转让给系统中的其他人,类似于比特币的转让:创建转让交易并用你的私人密钥签名。
有了这个,你就有可以更好地从上游控制你的人工智能训练数据、你的人工智能模型等等。「例如,你可以将这些数据进行混合却不能进行深入学习。」
这和 DeepMind 在其医疗保健区块链项目(healthcare blockchain project)中所采用的部分战略有点像。在数据挖掘中,医疗数据会带来监管和反垄断问题的风险(尤其是在欧洲)。但如果用户可以真正拥有自己的医疗数据并控制其上游使用,那么 DeepMind 就可以仅仅告诉消费者和监管机构说「嘿,实际上客户拥有自己的数据,我们只是拿来用而已」。我的朋友 Lawrence Lundy 提供了这个好例子,然后他进一步推断:
完全可能的是,政府会允许数据私有(人类或 AGI)的唯一方式是一个数据共享基础设施,「网络中立」规则,就像 AT&T 公司和原始的那种电话线。在这个意义上,越来越多的自主人工智能会要求政府接受区块链及其他数据共享基础设施,从而实现长远的可持续性。- Lawrence Lundy
机会 6:人工智能去中心化自治组织(Decentralized Autonomous Organization/DAO)——可以积累财富且无法关闭的人工智能
这是一个谎言。一个 AI DAO 属于人工智能自身,你无法关闭它。我下文会总结「如何做」。感兴趣的读者可以继续阅读深入该话题。
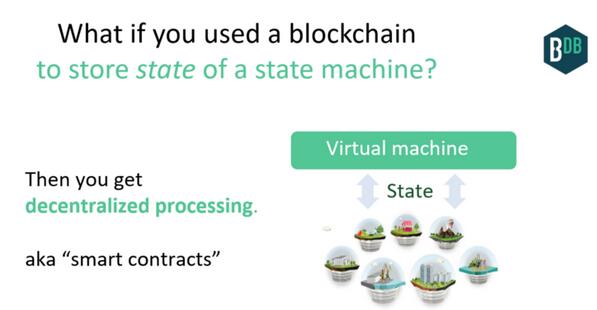
到目前为止,我们谈论了区块链作为去中心化数据库的内容。但我们也可以去中心化处理过程:基本上就是一个状态机的存储状态。周围有一些基础设施的话做起来更容易,而那就是「智能合同(smart contracts)」技术(比如 Ethereum)的本质。
我们之前已经以计算机病毒的形式进行了过程去中心化。没有单个实体拥有或控制它们,而且你不能将其关闭。但它们有限制——它们主要是会试图攻破你的计算机,就是这些。
但是,如果你可以与过程进行更丰富的互动,且过程本身可以积累财富呢?目前,通过在过程中使用更好的 API(如智能合同语言)和去中心化价值储存(如公共区块链)就可以实现它。
一个 DAO 是一个体现这些特征的过程。其代码可以拥有自己的东西。
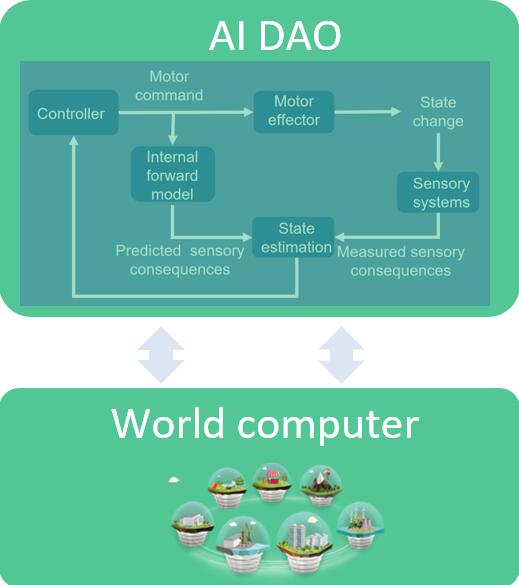
是什么把我们带向了人工智能。最有可能的是被称为「人工通用智能」(Artificial General Intelligence/AGI)的人工智能子领域。AGI 和环境中的交互的自主代理有关。AGI 可以被模型化为一个反馈控制系统。这是个好消息,因为控制系统有很多优点。首先它们有深厚的数学基础,这可以追溯到 20 世纪 50 年代(Wiener 的「控制论(Cybernetics)」)。它们捕捉与世界之间的互动(驱动和传感),并(基于内部模型和外部传感器来更新状态)适应它。控制系统得到了广泛的应用。它们决定了一个简单的恒温器如何去适应目标温度。它们消除了高价耳机中的噪音。它们处于成千上万的设备的中心,从烤箱到车里的刹车装置。
人工智能社区最近对控制系统的接受程度更加热烈了。比如,它们是 AlphaGo 的关键所在。而且 AGI 本身就是控制系统。
一个 AI DAO 就是一个运行在去中心化处理 & 存储载体之上的 AGI 式控制系统。其反馈回路会自行进行继续,输入、更新状态、执行输出,循环往复地使用这些资源。
我们可以从一个人工智能入手来得到一个 AI DAO(一个 AGI 代理),并使其去中心化。或者我们可以从一个 DAO 入手并赋予其人工智能的决策能力。
人工智能获取其丢失的链接:资源。DAO 得到其丢失的链接:自主决策。正因为如此,AI DAO 的使用范围比 AI 或 DAO 本身更大。其潜在影响也是成倍的。
这里有一些应用:
一个 ArtDAO,创建自己的数字艺术并进行销售。概括地说,它可以做 3D 设计、音乐、视频甚至是整部电影。
有自我身份的自动驾驶汽车。概括地说就是之前的任何人工智能应用现在是「属于自己」的了。未来的情况或许是人类一无所有而只是向 AI DAO 租用服务。
任何注入人工智能的 DAO 应用程序。
有更多自主性的任何去中心化 SaaS 应用程序。
总结
本文基于我个人在人工智能和区块链研究方面的经验,描述了区块链技术可以如何辅助人工智能。二者结合一处即发!区块链技术——尤其是行星尺度的——可以帮助实现人工智能和数据团体长期以来的一些梦想,并打开一些机会。
总结如下: