2018 年,AI 的发展脚步会加快,这一年将是 AI 技术重生和数据科学得以重新定义的一年。对于雄心勃勃的数据科学家来说,他们如何在与数据科学相关的工作市场中脱颖而出?2018 年会有足够多的数据科学相关工作吗?还是说有可能出现萎缩?接下来,让我们来分析一下数据科学的趋势,并一探如何在未来的大数据和机器学习 /AI 领域获得一份不错的工作。”

这里还是要推荐下小编的大数据学习QQ裙:532218147,不管你是小白还是大牛,小编我都欢迎,不定期分享干货,包括小编自己整理的一份2018最新的大数据资料和0基础入门教程,欢迎初学和进阶中的小伙伴。在不忙的时间我会给解答
1、你需要牢固掌握概率统计学,并学习和掌握一些算法,比如朴素贝叶斯、高斯混合模型、隐马尔可夫模型、混淆矩阵、ROC 曲线、P-Value 等。
不但要理解这些算法,还要知道它们的工作原理。你需要牢固掌握梯度下降、凸优化、拉各朗日方法论、二次规划、偏微分方程、求积法等相关算法。
如果你想找一份高薪的工作,还需要掌握机器学习技术和算法,比如 k-NN、朴素贝叶斯、SVM 和决策森林等。

2、
现在大部分机器学习都需要海量数据,所以你无法在单台机器上进行机器学习。所以,你需要用到集群,需要掌握 Apache Hadoop 和一些云服务,如 Rackspace、Amazon EC2、Google Cloud Platform、OpenStack 和 Microsoft Azure 等。
你还需要掌握各种 Unix 工具,如 cat、grep、find、awk、sed、sort、cut、tr 等。因为机器学习基本上都是在 Unix 系统上运行的,所以需要掌握这些工具,知道它们的作用以及如何使用它们。
3、在掌握编程语言和算法的同时,不要忽略了数据可视化的作用。如果无法让你自己或别人理解数据,那么它们就变得毫无意义。数据可视化就是指如何在正确的时间向正确的人展示数据,以便让他们从中获得价值。主要的数据可视化工具包括:Tableau、QlikView、Someka Heat Maps、FusionCharts、Sisense、Plotly、Highcharts、Datawrapper、D3.js、ggplot 等。
4、要成为数据科学家,不一定非要拿到数据科学方面的学位。事实上,你完全不需要这么做,这样做反而不是个好主意。如果你能拿到计算机学位、工程学学位、经济学学位、数学学位、统计学学位、精算师学位、金融学学位或者自然科学学位(物理、化学或生物)都是可以的。甚至是人文科学(包括社会科学)也是可以的。
2018年跳槽指南:如何找到一份人工智能相关的工作?
AI前线 • 7小时前 • 技能Get
大数据把 AI 推向了技术炒作的舞台正中央,数据科学和机器学习在各行各业开始崭露头角
本文由 【AI前线】原创,原文链接:http://t.cn/RHqaB5p
作者|Tanmoy Ray,译者|薛命灯,编辑|Emily
AI 前线导读:“2017 年,大数据把 AI 推向了技术炒作的舞台正中央,数据科学和机器学习在各行各业开始崭露头角。机器学习开始被应用于解决数据分析问题。机器学习、AI 和预测分析成为 2017 年的热门话题。我们见证了基于数据的价值创新,包括数据科学平台、深度学习和主要几个厂商提供的机器学习云服务,还有机器智能、规范性分析、行为分析和物联网。
2018 年,AI 的发展脚步会加快,这一年将是 AI 技术重生和数据科学得以重新定义的一年。对于雄心勃勃的数据科学家来说,他们如何在与数据科学相关的工作市场中脱颖而出?2018 年会有足够多的数据科学相关工作吗?还是说有可能出现萎缩?接下来,让我们来分析一下数据科学的趋势,并一探如何在未来的大数据和机器学习 /AI 领域获得一份不错的工作。”
增强技术实力
编程语言和开发工具
365 Data Science 收集了来自 LinkedIn 的 1001 数据科学家的信息,发现需求量最大的编程语言为 R 语言、Python 和 SQL。另外,还要求具备 MATLAB、Java、Scala 和 C/C++ 方面的知识。为了能够脱颖而出,需要熟练掌握 Weka 和 NumPy 这类工具。
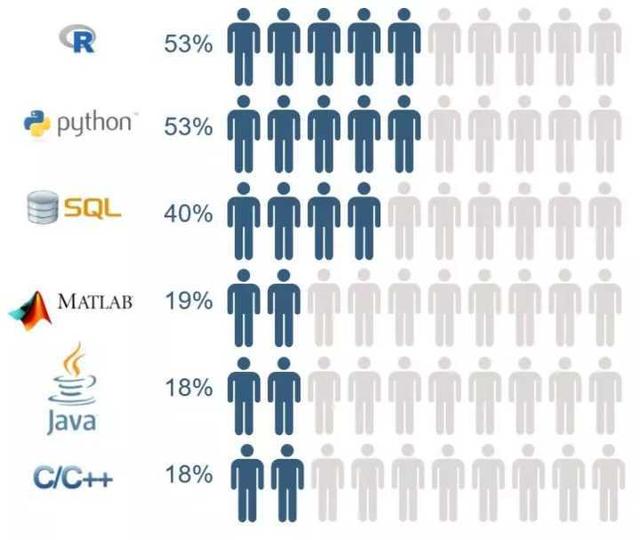
概率统计学、应用数学和机器学习算法
你需要牢固掌握概率统计学,并学习和掌握一些算法,比如朴素贝叶斯、高斯混合模型、隐马尔可夫模型、混淆矩阵、ROC 曲线、P-Value 等。
不但要理解这些算法,还要知道它们的工作原理。你需要牢固掌握梯度下降、凸优化、拉各朗日方法论、二次规划、偏微分方程、求积法等相关算法。
如果你想找一份高薪的工作,还需要掌握机器学习技术和算法,比如 k-NN、朴素贝叶斯、SVM 和决策森林等。
分布式计算和 Unix 工具
现在大部分机器学习都需要海量数据,所以你无法在单台机器上进行机器学习。所以,你需要用到集群,需要掌握 Apache Hadoop 和一些云服务,如 Rackspace、Amazon EC2、Google Cloud Platform、OpenStack 和 Microsoft Azure 等。
你还需要掌握各种 Unix 工具,如 cat、grep、find、awk、sed、sort、cut、tr 等。因为机器学习基本上都是在 Unix 系统上运行的,所以需要掌握这些工具,知道它们的作用以及如何使用它们。
查询语言和 NoSQL 数据库
传统关系型数据库已经老去。除了 Hadoop 之外,你还需要掌握 SQL、Hive 和 Pig,以及 NoSQL 数据库,如 MongoDB、Casssandra、HBase。
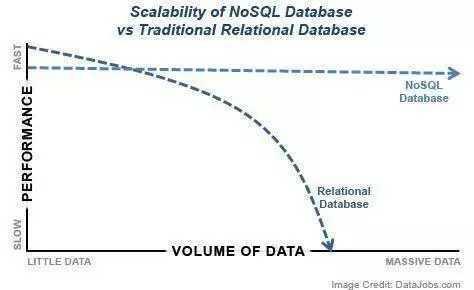
基于 NoSQL 分布式数据库的基础设施已经成为大数据仓库的基础。原先在一个中心关系型数据库上需要 20 个小时才能处理完的任务,在一个大型的 Hadoop 集群上可能只需要 3 分钟时间。当然,你也可以使用 MapReduce、Cloudera、Tarn、PaaS、Chef、Flume 和 ABAP 这些工具。
数据可视化工具
在掌握编程语言和算法的同时,不要忽略了数据可视化的作用。如果无法让你自己或别人理解数据,那么它们就变得毫无意义。数据可视化就是指如何在正确的时间向正确的人展示数据,以便让他们从中获得价值。主要的数据可视化工具包括:Tableau、QlikView、Someka Heat Maps、FusionCharts、Sisense、Plotly、Highcharts、Datawrapper、D3.js、ggplot 等。
正确选择教育背景和专业
要成为数据科学家,不一定非要拿到数据科学方面的学位。事实上,你完全不需要这么做,这样做反而不是个好主意。如果你能拿到计算机学位、工程学学位、经济学学位、数学学位、统计学学位、精算师学位、金融学学位或者自然科学学位(物理、化学或生物)都是可以的。甚至是人文科学(包括社会科学)也是可以的。
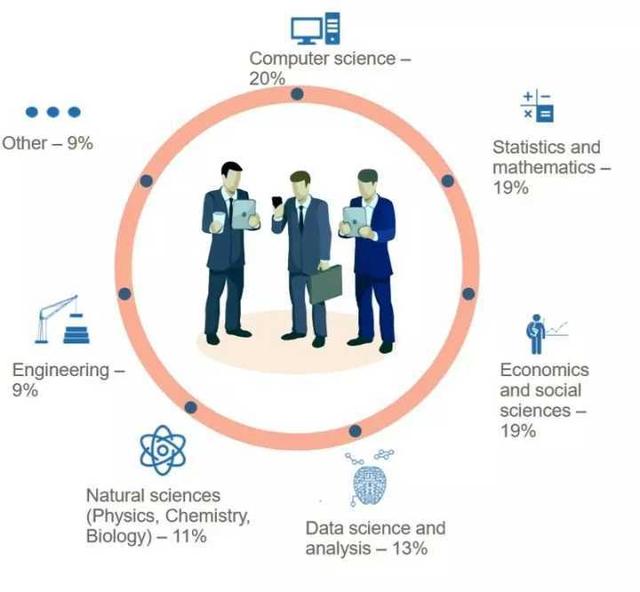
但或许你会在其他领域得到更好的发展,比如经济、应用数学或工程领域。首先要确定数据科学这条路是不是适合自己。2018 年绝对不会让那些有志在数据科学领域一展身手的人失望。不过还是那句话,一个具备分析能力的大脑、熟练的编程技能、诚挚的热情和持续自我提升的毅力将决定你的数据科学家之路会走多远。