计算机的工作原理(基于机器指令的分析)
计算机是怎么样工作的
实验环境:IA32体系结构,Ubuntu 12.04操作系统
一 单任务计算机的工作
1.1.宏观上的工作原理
1.11冯·诺依曼结构
要想知道计算机是怎样工作的,那么首先对于计算机的结构的了解是必不可少,冯·诺依曼结构奠定了现代计算机的基本结构。如图1所示。

图1冯·诺依曼结构
1.12基本工作原理
按照冯·诺依曼存储程序的原理,计算机在执行程序时须先将要执行的相关程序和数据放入内存储器中,在执行程序时CPU根据当前程序指针寄存器的内容取出指令并执行指令,然后再取出下一条指令并执行,如此循环下去直到程序结束指令时才停止执行。那么我们就可以将计算机的工作过程简化成如下图2所示。

图2 计算机基本工作原理
程序计数器,在IA32中通常称PC,linux中寄存器eip存储将要执行的下一条指令在存储器中的地址,通过图2可知,计算机通过这样不断的取指令并且去执行。
1.2基于指令的分析
由上述分析可知,计算机是通过执行机器指令来维持整个计算机的工作,IA32的机器代码与原始C代码相差很大,一些通常对C语言程序员隐藏的处理器状态是可见的,比如程序计数器、整数寄存器等。下面我就通过分析机器指令来了解计算机的工作过程。
当我们用高级语言编程的时候,机器屏蔽了程序的细节即机器级的实现,GCC C编译器可以以汇编代码的形式产生输出,汇编代码是机器代码的文本表示,非常接近于机器代码,所以我们可以通过研究汇编代码来分析计算机的工作过程。
分析的C代码示例如下所示:
int g(int x)
{
return x+3;
}
int f(int x)
{
return g(x);
}
int main(void)
{
return f(8)+1;
}1.21 GCC的工作过程
在分析汇编代码之前,首先来了解一下GCC的工作过程,从高级C程序文件到可执行目标文件的过程如图3所示。

图3 GCC工作过程
总共分为四个步骤,分别是:
(1)预处理阶段
gcc -E -o example.cpp example.c
(2)编译阶段
从预处理阶段开始:gcc -x cpp-output -S -o example.s example.cpp
从源文件开始:gcc -S –o example.s example.c
(3)汇编阶段
从编译后文件开始:gcc -x assembler –c –o example.o example.s
从源代码开始:gcc -c –o example.o example.c
(4)链接阶段
从汇编后文件开始:gcc -o example example.o
从源代码开始:gcc -o example example.c
为实现方面可以直接编写Makefile同时生成example.cpp、example.s、example.o、example,Makefile以及生成文件如下所示:

图4 Makefile
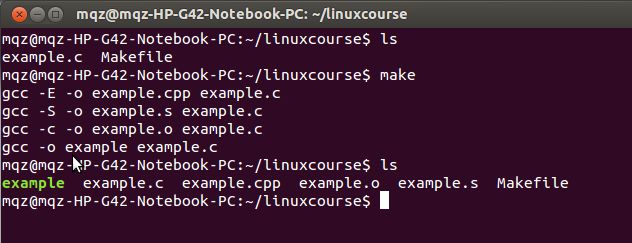
图5 文件的生成
1.22汇编代码分析
下面就到了关键的地方,就是通过分析汇编代码来了解计算机机器指令的执行过程,这里我们用objdump –d反汇编来生成易读的汇编代码,汇编代码如下所示:

图6 example.c的汇编代码
1.222首先介绍一下所用到的寄存器
eax为32的累加器寄存器,esp为栈顶指针寄存器,ebp为栈基地址指针寄存器。
1.223其次介绍一下用到的汇编命令
(1)push:push就是压栈操作,首先将栈顶指针减4,然后将内容压栈,比如push %ebp相当于sub $4 %esp, mov %ebp (%esp)两条指令。
(2)pop:pop操作与push正好相反,首先弹栈,然后将栈顶指针加4,比如pop %ebp相当于mov (%esp) %ebp, add $4 %esp两条指令。
(3)call:call指令是一个函数调用指令,它会跳转到其后接的内存地址处的函数进行执行。比如这里的call 80483b4
(4)leave:leave指令是函数返回是需要执行的指令,它会重置当前的栈顶指针和栈基地指针,相当于mov %ebp %esp,pop %ebp,简单来说就是函数要返回了,刚才所用到的栈空间需要清理掉,同时要恢复原来的栈基地址和返回地址。
(5)ret:ret指令是函数返回的最后一步,相当于将pop %eip,就是将栈中存放的返回地址放到eip中,返回到之前的地址去执行。
1.224具体分析
首先从main函数开始分析
| push %ebp |
保存函数执行前的原来的栈的基地址 |
| mov %esp, %ebp |
将当前栈顶指针赋值给ebp,表示现在函数的新的栈基地址 |
| sub $0x4,%esp |
将栈顶指针减4,指向可供存储参数的位置 |
| mov $0x8,(%esp) |
因为要调用函数f(8),所以将8压栈将为函数调用准备参数 |
| call 80483bf |
跳转到内存地址为80483bf处开始执行函数f |
| add $0x1,%eax |
f(8)返回后存储在eax中,此时将eax内容加一,相当于执行f(8)+1 |
| leave |
函数执行结束后清理栈空间,并将old ebp弹栈,记录原来栈的基地址 |
| ret |
执行pop %eip,返回 |
在main函数中我们会看到调用的函数f,函数f的入口地址是0x80483bf,下面我们先分析一下函数f的汇编代码
| push %ebp |
保存函数执行前的原来的栈的基地址,也就是main函数的栈的基地址 |
| mov %esp, %ebp |
将当前栈顶指针赋值给ebp,表示函数f的新的栈基地址 |
| sub $0x4,%esp |
将栈顶指针减4,指向栈顶第一个可以存储的位置 |
| mov 0x8(%ebp),%eax |
main函数中已经参数8压栈,现在可以用0x8(%ebp)来取得参数8,然后将参数8放到寄存器eax中,为函数g准备参数 |
| mov %eax,(%esp) |
将参数8压栈,参数8也是即将调用的函数g的参数 |
| call 80483b4 |
跳转到内存地址为80483b4处开始执行函数g |
| leave |
f函数执行结束后清理栈空间,并将old ebp(即main函数的栈的基址)弹栈,为返回main函数做准备 |
| ret |
执行pop %eip,返回到main函数中调用后的地方继续执行 |
我们可以看到在函数f的执行过程中我们又调用了函数g,函数g的入口地址是0x80483b4,下面来分析一下函数g的执行过程
| push %ebp |
保存函数执行前的原来的栈的基地址,也就是f函数的栈的基地址 |
| mov %esp, %ebp |
将当前栈顶指针赋值给ebp,表示函数g的新的栈基地址 |
| mov 0x8(%ebp),%eax |
在函数f中我们已将用到的参数8压入到栈中,这里我们可以通过0x8(%ebp)来获取参数8,供函数g使用 |
| add $0x3,%eax |
这是执行x+3,x就是传进来的参数8,将计算结果放到eax中,由此我们可以知道返回结果是通过eax在函数间传递的 |
| pop %ebp |
这里直接将函数f的基栈指针弹出即可,因为这里栈顶指针esp根本没有变化,所以就不用清理栈了 |
| ret |
执行pop %eip,返回到f函数中调用后的地方继续执行 |
上面通过简单的分析每条汇编指令来了解了程序的执行过程,下面通过分析栈空间的变化情况来更形象的了解程序在机器级的执行流程。
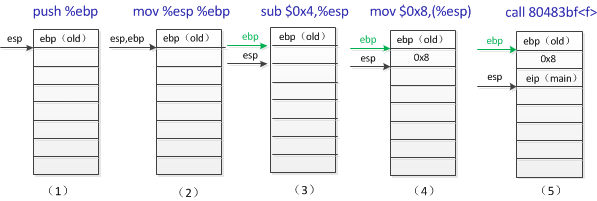
上面是main函数中的前四条指令执行时相应的栈中的变化,我想通过最初对指令的讲解和此时利用栈图更形象的讲解,不难理解这几条汇编指令的执行过程,这里的最后一条call 80483bf
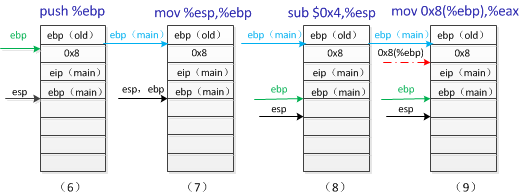

上面是从函数main进入到函数f的执行过程,首先push%ebp和mov %esp, %ebp是保存main函数的基地址指针和函数f的栈基址指针,接着是sub $0x4,%esp,mov 0x8(%ebp),%eax,从栈(9)中可以看到,0x8(%ebp)就是main函数中压入的参数8的位置,所以eax中现在存放的是参数8,所以mov %eax,(%esp)其实就是将参数8压栈,因为下一条指令call 80483b4
这样我们就进入到函数g中去执行,下面看看在g函数中执行的栈的情况。
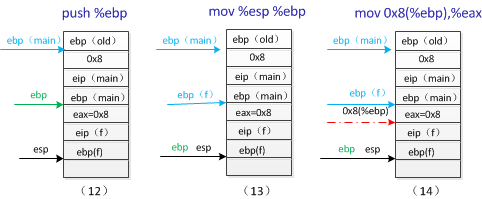
这是g函数执行的前三条指令,push%ebp是保存函数f的栈的基地址,mov %esp, %ebp是重置栈的基地址,即ebp存放的是函数g的基地址。mov 0x8(%ebp),%eax,我们可以看到0x8(%ebp)就是指参数8,因为函数g同样用到了参数8,所以将参数存放到eax中。
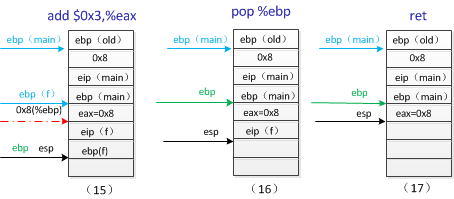
上面为函数g中最后的三条指令,我们可以知道add $0x3,%eax栈并没有改变,此时eax中存放的是参数8,这里其实是执行x+3操作,x即为参数8,返回结果11存放在寄存器eax中,pop %ebp是为返回到函数f做准备,在栈(15)中我们可以看到栈顶存放的是ebp(f),即函数f的栈的基址,这条指令执行完成后ebp重新指向函数f的栈的基址。ret操作将(16)中的eip(f)即函数f的返回地址存放到eip寄存器中,返回函数f继续执行。
我们知道在函数f中是执行call80483b4

如上图所示,栈(18)是指令leave执行后的结果,leave操作首先mov %ebp%esp,这是一个栈的清理过程,因为函数f已经执行完成,然后pop %ebp,我们可知此时栈顶存放的是main函数的栈的基址即ebp(main),所以pop %ebp后ebp存放的是main函数的栈的基址。ret操作就是pop %eip,从栈(18)我们可以看到栈顶存放的是main函数的返回地址eip(main),当执行完ret后我就可以返回到main函数继续执行。
main函数是从call80483bf
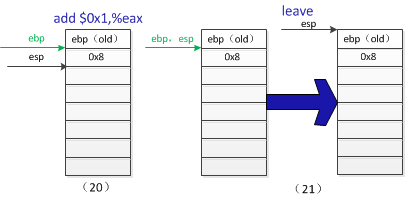
返回到main函数中,首先执行的add$0x1,%eax的操作,因为从函数f返回的结果f(8)存放在eax中,所以这条指令相当于f(8)+1,结果还是存放在寄存器eax中。同样,leave操作也是分两步进行的,如栈(22)所示,首先是mov %ebp,%esp,清理main函数的栈空间,然后是pop %ebp,将main函数执行前的old ebp弹栈。至于ret操作,跟前面一样,就是返回到main函数执行之前的地方继续执行。
1.3总结
上面主要通过宏观上和基于机器指令的分析来解析了计算机的基本工作原理,宏观上主要是基于冯·诺依曼结构来分析计算机是通过不断的取指令来进行工作的。基于指令的分析,主要是通过example.c程序的汇编代码来解析的,这里主要通过分析每条指令所执行的功能以及相应的栈和寄存器的变化来说明计算机基于机器指令的工作原理,相信通过上面的分析从宏观上和底层都会对计算机的工作原理有个清晰的认识。
二 多任务计算机的工作
现在的计算机基本上都是多任务计算机,多任务计算机的基本原理与单任务计算机基本相同,不同的是多任务运行需要CPU有自己的调度原理,可以将CPU时间分成时间片,每个任务会有自己的相应的时间片去运行,这就需要CPU支持在不同的任务间进行切换。对此只进行简单的介绍。

在多任务计算机中,寄存器CS为代码段寄存器,我们知道在单任务计算机中是以eip存放下一条指令地址的寄存器,在多任务计算机中我们是通过cs:eip来确定将要执行的指令的地址,如上图所示,如果想要从任务1切换到任务2,那么首先将要确定代码段cs,然后通过cs:eip来决定下一条将要执行的指令。
多任务计算机的运行肯定是需要中断的支持,至于中断的具体细节在这里不加赘述。