操作系统内存管理
内存是计算机中须要我们认真管理的重要资源。程序大小的增长速度比内存容量的增长要快得多。帕金森定律指出:“无论存储器有多大,程序都能够把它填满”。
人们提出一个非常重要的概念就是“分层存储体系”,这个体系包含:快速缓存(cache),内存。磁盘。可移动存储装置。
操作系统的工作就是将这个存储体系抽象为一个实用的模型并管理这个抽象模型。
一:无存储器抽象
在这样的情况下,要想在内存中同一时候执行两个程序是不可能的。比方:第一个程序在5位置写入一个值,将会擦掉第二个程序存放在同样位置上的全部内容,所以同一时候执行这两个程序就会出错或立马崩溃。
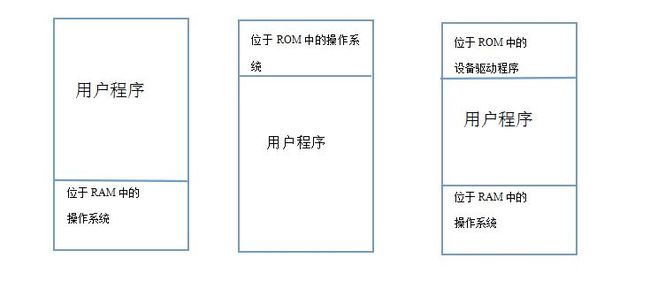
在不使用内存抽象的情况下执行多道程序

(与讨论无关的没有画 出来)。当两个程序连续地装载到内存中从0開始的地址时,内存中的状态就如同最右边所看到的。
(我们如果系统在高地址处。图中没有画出来),如今。让我们来执行这两个程序:
当第一个程序開始执行时。它执行了JMP 24。然后结果也是我们想要看到的,可是。当第一个程序执行一段时间后,操作系统可能会决定開始执行第二个程序。即装载在第一个程序上的地址16384处的程序。这个程序第一条指令为JMP 28。则这条指令会跳到ADD指令那里去而不是事先设定好的跳转到CMP指令。因为对内存的不对訪问。这个程序非常可能在1秒之内就崩溃了。
这些设备之所以可以正常工作,是由于全部执行的程序都是可以事先确定的,用户可不能再洗衣机或者烤面包机上自由执行自己的软件吧。
二:有存储器抽象
总之把物理地址暴漏给进程会带来以下几个严重问题。
1:假设用户程序能够寻址内存每一个字节,他们就能够轻松地破坏操作系统。(除非有特殊的硬件保护。比如上面提到的IBM360锁键模式)
2:这样的模型,假设想要同一时候执行多个程序(假设仅仅有一个CPU轮转)是非常困难的。
1:地址空间的概念
再说地址空间之前,我们聊一聊。要保证计算机同一时候执行多个程序而不互相影响。必须解决两个问题:保护和重定位。
还是用上面的样例IBM360来说:它给内存块标记上一个保护键,而且比較执行进程的键和其訪问的每一个内存字的保护键。然而这样的方法在解决重定位时用的是:用过程序被装载时重定位来解决,但这是一个缓慢而复杂的解决的方法。
接下来我们来讲这个更好的办法:地址空间。
地址空间是一个进程可用于寻址的一套地址集合。每一个程序都有一个自己的地址空间。而且这个地址空间独立于其它进程的地址空间(除了一些特殊情况下进程须要共享它们的地址空间外)。这和进程的概念创在一类抽象CPU以执行程序思想基本一样。我们能够想一想,我们怎么做能够使得一个程序中的地址28所相应的物理地址与还有一个程序中的地址28相应的物理地址不同
解决的方法是使用一种简单的动态重定位,就是简单地把每一个进程的地址空间映射到物理内存的不同部分。
从CDC6600到Intel8088,使用的就是给每一个CPU配置两个特殊的硬件寄存器,各自是基址寄存器和界限寄存器。所以使用程序装载到内存中连续的空暇位置且装载期间无须重定位。举个样例:当一个程序执行时。程序的起始物理地址装载到基址寄存器,程序的长度装载到界限寄存器。所以在上图中,第一个程序执行时,寄存器值分别为0和16384。第二个程序执行时。为16384和32768。每一次进程訪问内存。取一条指令,读或写一个数据字,CPU硬件会把地址发送到内存总线前。自己主动把基址值加到进程发出的地址值上,同一时候检查提供的地址是否=或>界限寄存器里的值。
假设越界就会产生错误并终止訪问。
比方运行 JMP 28指令,可是硬件就会解释成为JMP 16412,所以程序如我们所愿的跳转到了CMP指令。在上图中第二个程序运行过程中。基址寄存器和界限寄存器的设置例如以下图:

在CDC6600(世界上最早的超级计算机)中就提供了对这些寄存器的保护。但在Intel8088中则没有,甚至连界限寄存器都没有,但却提供了多个基址寄存器,是程序的代码和数据,是程序的代码和数据能够被独立地重定位。可是没有提供引用的地址越界的预防机制。
使用基址寄存器和界限寄存器重定位的缺点是:每次訪问内存都须要进行加法和比較运算。比較能够做的非常快。可是加法因为进位传递时间问题,在没有使用特殊电路的情况下会显得非常慢。
2:交换技术和虚拟内存
还有其它后台进程还会查看所收到的邮件和进来的网络连接,以及其它非常多诸如此类的任务。而且,这一切发生都在第一个用户程序启动之前。当前重要的应用程序能轻易地占领50~200MB甚至很多其它的空间。
所以。把全部进程一直保存在内存中须要巨大的内存。
1)交换技术

上图d)显示A被交换到磁盘。
然后d)被调入。B被调出,最后A再被调入。能够看到A的位置生变化,所以在它换入的时候通过软件或者在程序执行期间通过硬件对其它地址进行重定位。比如,在这里就能够非常好地使用基址寄存器和界限寄存器。
为了降低因内存区域不够而引起的进程交换和移动所产生的开销,一种可用方法是:当换入或移动时为他们分配额外的内存。
然而。当进程被换出到磁盘上时。应该仅仅交换进程实际上使用的内存中的内容。讲额外内存交换出去是一种浪费。
下图读者能够看到一中已经为两个进程分配了增长空间的内存配置。

a)图是为可能增长的数据段预留空间,b)图为可能增长的数据段和堆栈预留空间。
进程有两个可增长的段,比如,一个是变量动态分配和释放的作为堆使用的一个数据段,还有一个是存放普通局部变量与返回地址的一个堆栈段,则如图b)所看到的,在图中能够看到所看到的进程的堆栈段在进程所占内存的顶端并向下增长。紧接着在程序段后面的数据段向上增长。
在这两者之间的内存可供两个段使用,用完了。则进程必须移动到足够大的空暇区中(它能够被交换出内存直到内存中有足够的空间),或者结束该进程。
空间内存管理
在动态分配内存时,操作系统必须对其进行管理。一般而言,有两种方式跟踪内存使用情况:位图和链表。
以下就来介绍
one:使用位图进行管理
首先内存被划分成小到几千字或大到几千字节的分配单元。每一个分配单元相应于位图中的一位。0表示空暇,1表示占用(自定义的)。
举个样例例如以下图所看到的:
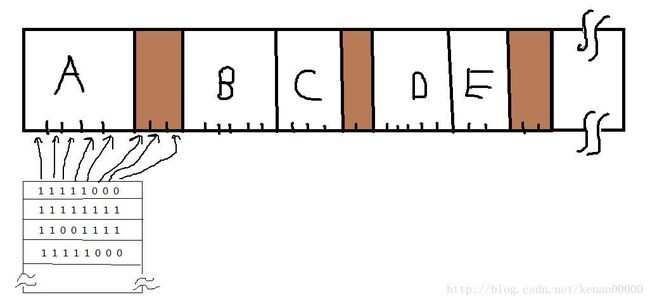
上图是一段有5个进程和3个空暇区的内存,刻度表示内存分配的单元。阴影区域表示空暇(为图中用0表示),分配单元大小是一个重要的设计因素。分配单元越小。位图越大。
然而即使仅仅有4个字节大小的分配单元,32位内存也仅仅须要位图中的1位。32n位的内存须要n位的位图,所以位图仅仅占用了1/33的内存。若选择比較大的分配单元,则位图更小。但若进程的大小不是分配单元的整数倍,那么最后一个单元就会有一定数量的内存被浪费了。内存单元大小+分配单元的大小 决定了-> 位图的大小,所以这是一个提供一块固定大小的内存就能对内存使用情况进行记录的方法。
位图的缺点是:在一个站K个分配单元的进程调入内存时,存储器管理器必须搜索位图。在位图中找出有K个连续的0的串,这是非常耗时的!
two:使用链表进行管理链表管理例如以下图,就不在过多赘述了。
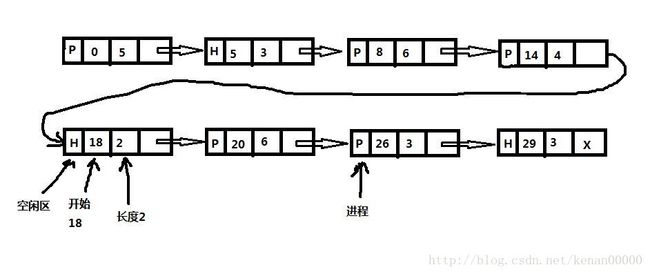
当进程终止被换出时链表的更新很直接,例如以下图四种情况所看到的:

对于链表管理很多其它的能够自己上网百度,这里仅仅是简单的介绍下。
2)虚拟内存
基址寄存器和界限寄存器能够用于创建地址空间的抽象,可是。还有一个问题来了须要解决,就是管理软件的膨胀。尽管存储器容量增长高速。可是软件增长更快!发展到后面结果是,须要执行的程序往往达到内存无法容纳。并且必定须要系统能够支出多个程序同一时候执行,尽管也许内存能够满足一个程序的须要。可是整体看来,他们仍然超出了内存大小,所以交换技术不是已经不是一个好的选择了。
原因是,一个典型的SATA磁盘的峰值最高达到100MB/S。这意味着至少须要10秒才干换出一个1GB的程序,并须要还有一个10秒才干将一个1GB的程序换入。
所以我们用到了一个方法称为虚拟内存(virtual memory)。其基本思想是:每一个程序拥有自己的地址空间,这个空间被切割成多个块,每一块称为一页或页面。
每一页有连续的地址范围。这些页被映射到物理内存,并非全部的页必须在内存中才干运行程序。当程序引用到一部分在物理内存中的地址空间时,由硬件立马运行必要的映射。当不在时,有操作系统负责将缺失的部分装入物理内存并又一次运行失败的指令。
从某个角度讲,虚拟内存是对基址寄存器和界限寄存器的一种综合。
比如,8088为正文和数据分离出专门的基址寄存器(上面提到过8088不包含界限寄存器)。而虚拟地址使得整个地址空间能够用相对较小的单元映射到物理内存,而不是为正文段和数据段分别进行重定位。虚拟内存适合在多道程序中使用,很多片段同一时候保存在内存中。
当一个程序等待它的一部分读入内存时,能够把CPU交给还有一个进程使用。以下我们来介绍分页吧:
分页:
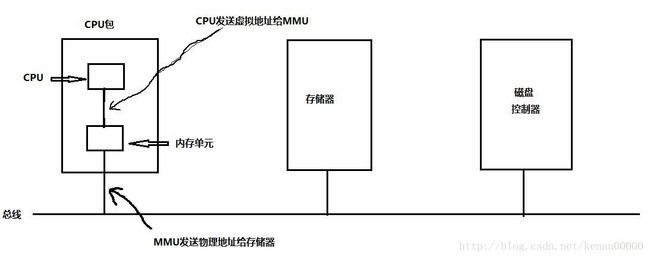
大部分虚拟内存都是用的一种称为分页的技术。程序指令比方:MOV REG, 1000,他把地址1000的内存单元的内容拷贝到REG中。
由程序产生的地址称为虚拟地址,他们构成了虚拟地址空间。在有虚拟内存的情况下,虚拟地址不是被直接送到内存总线上的,而是被送到内存管理单元(Memory Management Unit, MMU),MMU把虚拟地址映射为物理内存地址,例如以下图所看到的:
详细分页过程请看下图。
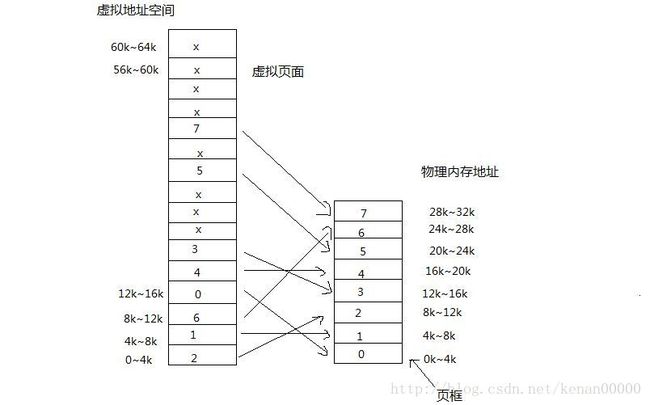
在这个图中,有一台能够产生16位地址的计算机,地址范围从0K到64K。且这些地址是虚拟地址。然而。能够看到这台计算机仅仅有32KB的物理内存,因此,尽管能够编写64KB的程序。但它们却不能被全然调入内存执行,在磁盘上必须有一个能够大到64KB的程序核心的完整副本,以保证程序片段在须要时能被调入内存。虚拟地址空间依照固定大小划分成称为页面(page)的若干单元。在物理内存中相应的单元称为页框(page frame)。页面和页框一般大小一样,本例,我们将其设为4KB(所以当中12位来表示偏移量,这里不懂没关系。后面会有解释)。相应于64KB的虚拟地址空间和32KB的物理内存,我们得到16个虚拟页面和8个页框。
RAM和磁盘之间的交换总是以整个页面为单元进行的。
我们举个样例吧: MOV REG, 8192
由于虚拟地址8192虚拟页面2中,即8k到12k的页面(页面从0開始计数),它被映射到了物理页框6中(即24576~28671)。所以上述指令就为:MOV REG, 24576
通过恰当的设置MMU。能够把虚拟页面映射到8个页框中的不论什么一个。
可是这并没有解决虚拟地址空间比物理内存大的问题。当我们訪问一个未映射的页面, MOV REG, 32780将会发生什么呢?
首先虚拟页面8(他的范围是32768~36863)的第12个字节相应物理地址时什么呢?MMU注意到该页面没有被映射(图中用X表示),于是CPU陷入到操作系统,这个陷阱被称为缺页中断(page fault)。
他的处理分为3步:1)假设操作系统决定放弃页框1,那么它将把虚拟页面8装入物理地址8192,并对MMU映射做两处改动。2)首先他要标记虚拟页面1表项为未映射。3)随后把虚拟页面8的表项的叉号改为1。所以在引起陷阱的指令又一次启动时,它将把虚拟地址32780映射为物理地址4108(4096+12)。
接下来我们看一下MMU内部结构吧。看看它是怎样工作的,了解为什么我们选用的页面大小都是2的整数次幂。看下图:

上图能够看到一个虚拟地址的样例,虚拟地址8196(二进制为001000000000100)用上图所看到的的MMU进行映射,输入为16位虚拟地址被分为4位的页面号和12位的偏移量。4位页号能够表示16个页面,12位偏移量能够为一页的所有4096个字节编址。
可用页号作为页表的索引,从而得出相应于虚拟页面的页框号。假设在/不在位是0。则将引起一个操作系统陷阱。假设是1,则将在页表中查到页框号拷贝到输出寄存器的高3位,再加上输入虚拟地址中的低12位偏移量。如此就构成了15位的物理地址。输出寄存器的内容随即被作为物理地址送到内存总线。
总结:虚拟地址被分成虚拟页号(高位部分)和偏移量(低位部分)两部分。
比如,对于16位地址和4KB的页面大小,高4位能够指定16个虚拟页面中的一页。而低12位接着确定了所选页面中的字节偏移量(0~4095)。
使用3或5或其它位数拆分虚拟地址也是可行的。不同划分相应不同的页面大小。
对于页表本身他还有非常多位的标志,比方有改动位,訪问位。快速缓存禁止位,保护位。

不同计算机的页表大小可能不一样,但32位是一个经常使用的大小。
页框号:映射的目的就是找到这个值。
在/不在位:1是有效,0则表示该表项相应的虚拟页面不在内存中,訪问该页面会引起一个缺页中断。
保护位:支出一个页同意什么类型的訪问。比方:0->读/写, 1->仅仅读。
改动位:它是用来记录页面使用情况的。
在写入一页时有硬件自己主动设置改动位。假设一个页面被改动过,那么就是“脏”的,则必须把它写回磁盘。
反之就是“干净”的,简单地丢弃就能够了。这一位有时也被称为脏位。
訪问位:系统会在该页面被訪问时设置訪问位。
他的作用是帮助操作系统在发生缺页中断时选择要淘汰的页面。
不再使用的页面要比正在使用的更适合淘汰。这一位在页面置换算法中非常重要。
快速缓存禁止位:对那些映射到设备寄存器而不是常规内存的页面而言,这个特性是很重要的。
比如:操作系统正在紧张地循环等待某个I/O设备对它刚发出的命令做出对应,保证硬件是不断地从设备中读取数据而不是訪问一个旧的被快速缓存的副本是很重要的。通过这一位能够禁止快速缓存。具有独立I/O空间而不使用内存映射I/O的机器不须要这一位。
加速分页的过程
运行速度通常被CPU从内存中取指令和数据的速度所限制。所以每次内存訪问必须进行两次页表訪问会减少一半的性能,这样没人会使用分页机制。
所以这个方法是为计算机设置一个小型的硬件设备,将虚拟地址直接映射到物理地址。而不是再訪问页表,这样的设备称为转换检測缓冲区(Translation Lookaside Buffer, TLB)。有时又称为相联存储器。
当中每一个表项都记录一个页面相关信息。包含虚拟页号,改动位,保护位,物理页框。另一位用来记录这个表项是否有效。
当一个表现被清除出TLB时,将改动位拷贝到内存中的页表项,除了訪问位。其它值不变。当页表项中从页表装入TLB中时,全部的值都来自内存。
针对大内存的页表

由于偏移量为12。所以页面长度是4KB。共同拥有2的20次方个页面。
索引顶级页表得到的表项中含有二级页表的地址或页框号。顶级页表的表项0指向程序正文的页表,表项1指向数据的页表。表项1023指向堆栈的页表。其它的表项未用。如今把PT2作为訪问选定的二级页表的索引。也变找到相应的页框号。
假设不存在内存则缺页中断,否则从二级页表中得到页框号和偏移量结合成物理地址。
其它都被设为0(不在)。
因此64位分页虚拟地址空间的系统须要一个不同的解决方式。例如以下
倒排页表
比如64位虚拟地址,4KB的页,1GB的RAM,一个倒排页表仅须要262144个表项。
尽管节省了大量空间,可是它从虚拟地址到物理地址的转换会变得非常困难。走出这样局面的办法是使用TLB。
假设TLB可以记录全部频繁使用的页面,地址转换就可能变得像通常的页表一样快。倒排页表在64位机器中非经常见,由于在64位机器中即使使用了大页面。页表项的数量是非常庞大的。比如对于4MB页面和64位虚拟地址,须要2的42次方个页表项。