思考
对视频进行描述,其描述子必须:
1.具有普遍性以适应各种场景;
2.必须短小紧凑
3.必须利于计算
4.必须易于实现
图像识别中,特征提取的很完备和优秀,但不适用于视频。本文致力于利用3D CNN提取时空特征。我们只用线性分类器来分类它们,以验证特征好坏。并且这些特征可以被拿来做各种视频分析任务,无需针对任务再调整模型(就笔者知道的,包括video caption, temporal action detection等任务都有许多人使用C3D来提取特征)。
本文的发现
1.用实验验证了3D卷积深度模型很适合同时提取外貌和时空特征;
2.发现3×3×3的卷积核表现最好
3.在4个任务,6个不同的benchmark上,仅仅用我们提取的特征加上线性分类器已经超过或接近当今最好模型了。
我们的方法输入的就是完整的帧,无需依赖于任何预处理。当然,有些部分和AK那篇和双流那篇有些相似。AK那篇除了Slow Fusion都是2D卷积,而本文将在卷积和池化层都使用3D操作。并且还将展示,建立更深的网络以及在时间空间上逐步池化能保证取得最好的效果。
3D卷积网络
接下来的一节,我们介绍基础的3D卷积操作,以及设计不同的3D卷积网络。
对一张灰度图进行2D卷积,得到一张图片(一个feature map),哪怕是彩色图有三个通道,也是一样,最终得到的还是一张图(一个feature map),它们本质上都是2D卷积,不包含任何时间信息。AK那篇中Slow Fusion,虽然表现比同文中其它模型好,但是在第3层之后运动信息还是丢失掉了。
本文的思路也是empirically地通过对比找到一个好的结构。
卷积核尺寸的确定:受2D CNN的启发,我们固定地将空间维度定为3×3,仅尝试不同时间维度的信息。
网络的输入输出
输入:一个clip
输出:类别
clip的记法:c×l×h×w,分别为通道,clip中帧的数量,每帧的高和宽。
....................帧分辨率h×w:128×171(大约UCF101分辨率的一半)
....................clip长度l;16.视频被分成一个个16帧的clip,且无重叠
故clip尺寸为3×16×128×171
网络结构
一共包含5个卷积层,每层的卷积核数量为64,128,256,256,256。在时间和空间上都进行合适的padding操作,并且步长选为一,这样就能够保证卷积前后clip的尺寸不变。
pooling层:第一层上的pooling操作采用1×2×2的kernel size,1代表深度。意图是想尽量保留运动信息不要过早融合。之后的pooling操作均采用2×2×2的kernel size。
超参探索
其实本文的目的之一也是研究如何融合运动信息。但是本文只探索卷积核时间维度的最佳大小,而保持其它设置不变。这里从两个方向进行尝试:1. 均匀时间深度,即所有卷积层都用同样尺寸卷积核;2. 变化时间深度,即对于第一种,我们尝试四个网络,分别用depth值为1,3,5,7的卷积核,深度为d的网络成为depth-d网络。对第二种,尝试两个网络,第一种卷积核increasing,各层卷积核深度为3,3,5,5,,7,第二种卷积核decreasing,为7,5,5,3,3。
所有这些网络在经过最后一个池化层后输出信息尺寸一样(因为有padding)。由实验结果(下图)发现3×3×3的卷积核效果最佳,并且好于2D卷积(depth=1就是2D卷积)

网络整体描述
当面对大型数据集的时候,可以加深网络深度,但卷积核依旧使用3×3×3。从现在开始,正式叫这个网络为C3D。整体介绍一下这个网络的配置:

- 8 convolution layers,
- 5 pooling layers,
- two fully connected layers,
- a softmax output layer.
- 所有卷积核均为3×3×3
- 第一个pooling层1×2×2,Stride=1×2×2,之后都是2×2×2,stride=2×2×2
- 两个全连接层都是4096
训练
在 Sports-1M数据集上训练。从每个视频中抽取5个clip,每个clip占2秒,每个clip被resize为128×127.训练时又把crop成为16×112×112 的crop。
除了在Sports-1M上重头训练C3D网络,我们还训练了一个已经在I380k上预训练过的模型。

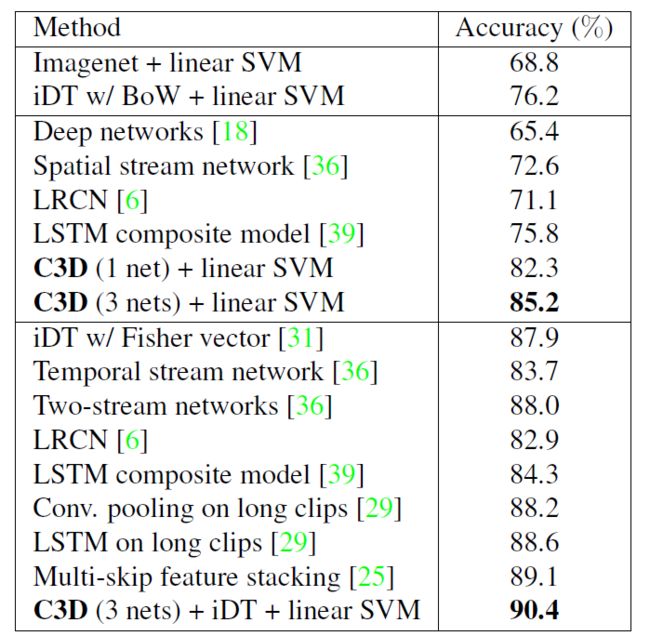
显然,C3D在各个测试上表现都不错,但仅次于Convolution pooling on 120-frame clips。它使用的是长clip,速度必然极其慢。而且clip level 的对比上肯定是120-frame clip的表现好。我们主要对比video层面的表现。
C3D视频描述子
C3D网络也可以用来抽取并描述视频特征,即可以认为第一个全连接层的输出作为对这个clip的描述。对于视频,连续抽取16帧作为一个clip,两个clip之间存在8帧的重合。然后把每个clip输入C3D网络,每个clip对应输出一个4096维的激活向量。把它们做平均之后通过L2-Normalization就可以得到这个视频的描述子。
将这个描述子用在视频动作识别上试试:
在UCF101上测试。方法是,用C3D提取的特征描述子输入SVM进行分类,检验描述子的好坏。这里尝试了不同C3D提取的描述子,包括:
C3D trained on I380K
C3D trained on Sports-1M
C3D trained on I380K
fine-tuned on Sports-1M
下文略