内容简述:
一:数据存储-MySQL|Redis
二:分布式爬虫Scrapy-Redis
三:分布式爬虫源码解读
四:分布式爬虫部署
一:数据存储-MySql
【案例】-读书项目
from scrapy.utils.project importget_project_settings
settings = get_project_settings()
二:分布式爬虫-Scrapy-Redis
概述:是实现Scrapy分布式爬取而提供了一些以redis为基础的组件。
组件包含:
Scheduler –调度器
Duplication Filter –指纹去重
Item Pipeline-管道
Base Spider- 基础Spider
组件作用:
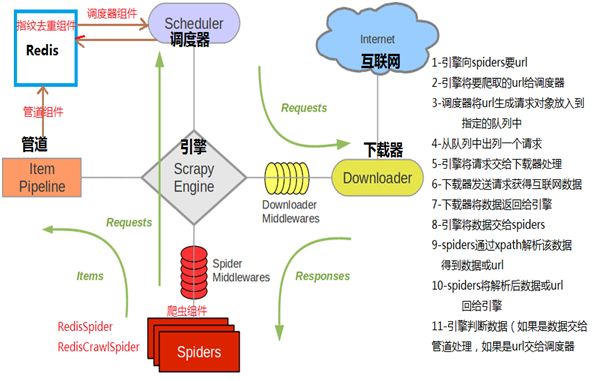
a-调度器:
负责对新的request进行入列操作以及取出要出列的request
管理维护待爬取字典队列结构,使用Scrapy-redis的scheduler组件
原来Scheduler已经无法使用
补充说明:
Scrapy改造了python原来的双向队列形成了自己的Scrapy queue但Scrapy多个spider不能共享待爬取队列Scrapy queue.即Scrapy本身不支持分布式爬虫。 Scrapy-redis 解决把Scrapy queue换成redis数据库(redis队列),从同一个redis-server存放要待爬取的request,方便多个spider去同一个数据库里读取。
b-指纹去重(过滤器):
Scrapy-redis去重依赖于Duplication Filter组件。其底层利用redis的set不重复特性
具体底层去重细节:
1-scrapy-redis调度器从引擎接受request,将reques的指纹存入redis的set检查是否重复,并将不重复的request push写入redis的 request queue。 2-引擎请求request时,调度器从redis的request queue里根据优先级弹出一个request 返回给引擎,引擎将此request发给spider处理。
c-管道:
引擎将Spider返回的爬取到的Item给Item Pipeline。scrapy-redis的Item Pipeline将爬取到的Item存入redis的items queue。ItemPipeline可根据key从items queue提取item从而实现items processes集群
Scrap-Redis原理:
三:官方例子源码解读
https://github.com/rmax/scrapy-redis
三个爬虫样本
dmoz.py 传统的CrawlSpider,目的是让数据保存到redis中。运行: scrapy crawl dmoz
myspider_redis.py 继承RedisSpider,start_urls被redis_key替代,allow_domains不变
【提示】官方用__init__方法来替换allow_domains不支持目前的版本
mycrawler_redis.py 继承RedisCrawlSpider,其它的和myspider_redis.py一样
【温馨提示】后两种爬虫的运行方式为:
scrapy runspider myspider_redis.py
scrapy runspider mycrawler_redis.py
【温馨提示】
from scrapy_redis.spidersimport RedisSpider
from scrapy_redis.spiders importRedisCrawlSpider
是scrapy_redis新增加的两个组件,都是继承自官方的Spider、CrawlSpider
四:使用redis存储
pip install scrapy-redis
【温馨提示】
在爬取网站的时候,将settings 中的DOWNLOAD_DELAY选项打开。
DOWNLOAD_DELAY = 1
五:分布式爬虫部署
执行说明:
现在有5台电脑c1 c2 c3 c4 c5,computer3上面安装的是redis服务器,master端(主节点) c1|c2|c4|c5都从c3的redis上面获取请求或将请求添加到c3的redis服务器中, slave端(从节点)首先启动,页面会停止在那里等待指令,此时master通过lpush向队列中添加一个起始url。其中一个slave端获取到这个url开始爬取,此slave端会将解析之后的很多url再次的添加到redis服务中,然后redis服务再从请求队列中向每个slave端分发请求,最终直到所有请求爬取完毕为止。
文件中配置内容:
scrapy_redis指纹去重类
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
调度器是scrapy_redis的调度器
SCHEDULER ="scrapy_redis.scheduler.Scheduler"
爬取的过程中是否允许暂停
SCHEDULER_PERSIST = True
配置存储的redis服务器
REDIS_HOST = '10.0.112.191'
REDIS_PORT = 6379
运行操作说明:
scrapy runspider mycrawler_redis.py
master端向队列中添加起始url。key就是代码中的redis_key
lpush fen:start_urls 'http://www.dytt8.net/html/gndy/dyzz/index.html'