堆
文章目录
- 二叉堆
- 二叉堆的自我调整
- 插入节点
- 删除节点
- 构建二叉堆
- 二叉堆的代码实现
- 为什么快速排序要比堆排序性能好?
堆排序是一种原地的、时间复杂度为 O(nlogn) 的排序算法。
二叉堆
二叉堆本质上是一种完全二叉树,它分为两个类型。二叉树的根节点叫作堆顶。
1:最大堆
什么是最大堆呢?最大堆的任何一个父节点的值,都大于或等于它左、右孩子节点
的值。
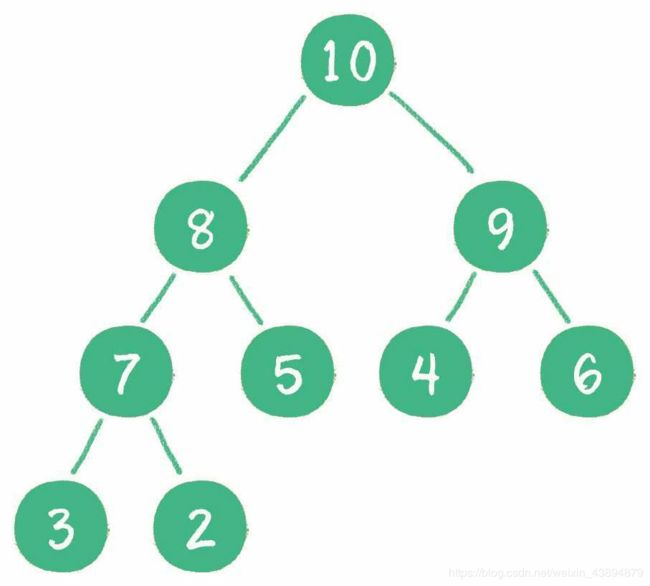
2:最小堆
什么是最小堆呢?最小堆的任何一个父节点的值,都小于或等于它左、右孩子节点的值。

最大堆和最小堆的特点决定了:最大堆的堆顶是整个堆中的最大元素;最小堆的堆顶是整个堆中的最小元素。
二叉堆的自我调整
所谓堆的自我调整,就是把一个不符合堆性质的完全二叉树,调整成一个堆。
插入节点
当二叉堆插入节点时,插入位置是完全二叉树的最后一个位置。例如插入一个新节
点,值是 0。这时,新节点的父节点5比0大,显然不符合最小堆的性质。于是让新节点“上浮”,和父节点交换位置。

如此反复“上浮”,最终新节点0“上浮”到了堆顶位置。
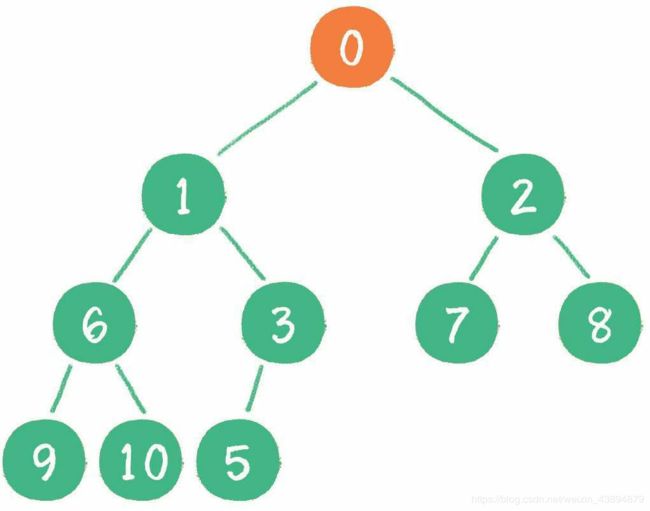
删除节点
二叉堆删除节点的过程和插入节点的过程正好相反,所删除的是处于堆顶的节点。例如删除最小堆的堆顶节点1。
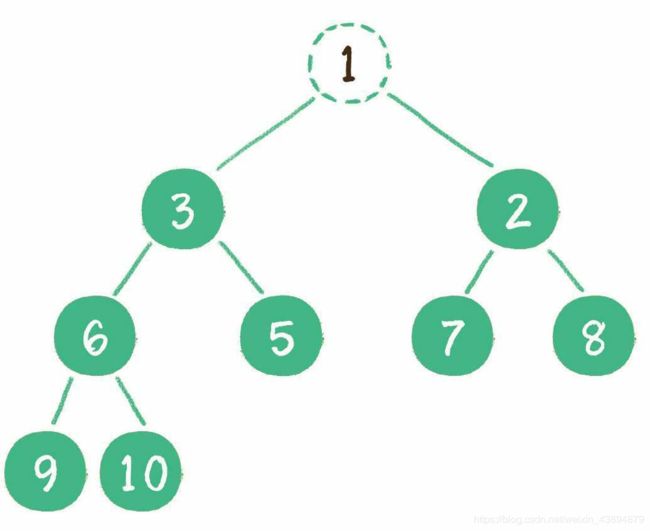
这时,为了继续维持完全二叉树的结构,我们把堆的最后一个节点10临时补到原本堆顶的位置。
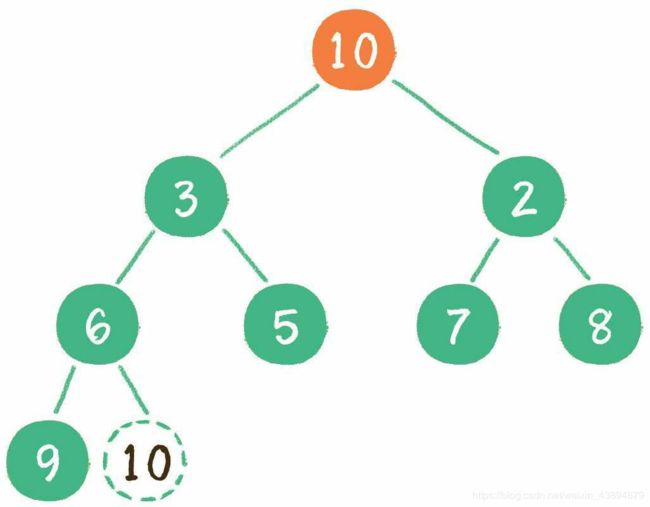
接下来,让暂处堆顶位置的节点10和它的左、右孩子进行比较,如果左、右孩子节点中最小的一个(显然是节点2)比节点10小,那么让节点10“下沉”。如此反复,节点10“下沉”至叶子节点。

构建二叉堆
构建二叉堆,也就是把一个无序的完全二叉树调整为二叉堆,本质就是让所有非叶
子节点依次“下沉”。
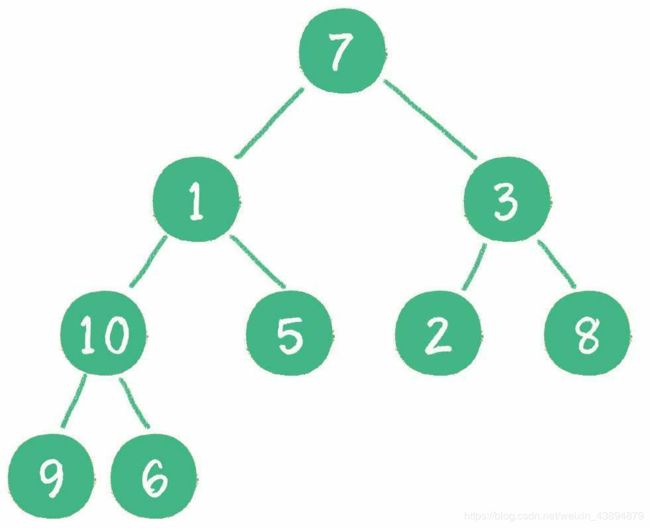
首先,从最后一个非叶子节点开始,也就是从节点10开始。如果节点10大于它左、右孩子节点中最小的一个,则节点10“下沉”。
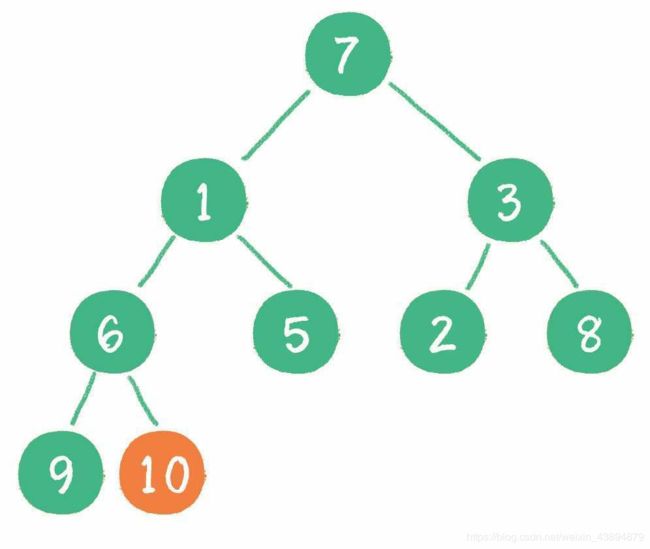
接下来轮到节点3,如果节点3大于它左、右孩子节点中最小的一个,则节点3“下
沉”。
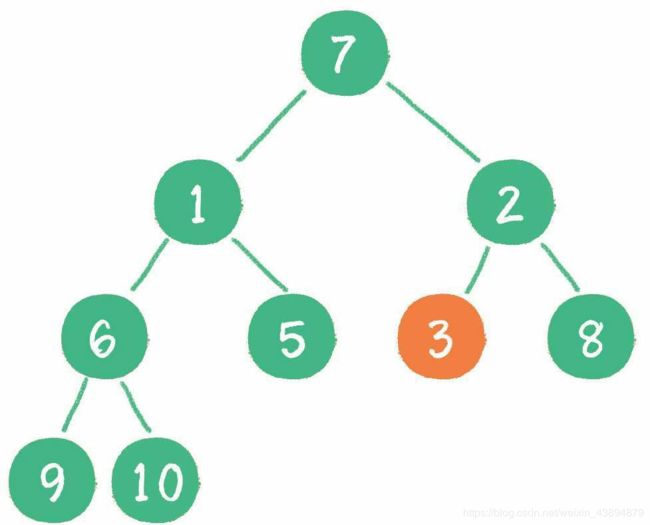
然后轮到节点1,如果节点1大于它左、右孩子节点中最小的一个,则节点1“下沉”。
事实上节点1小于它的左、右孩子,所以不用改变。
接下来轮到节点7,如果节点7大于它左、右孩子节点中最小的一个,则节点7“下
沉”。

节点7继续比较,继续“下沉”。

堆的插入操作是单一节点的“上浮”,堆的删除操作是单一节点的“下沉”,这两个操作的平均交换次数都是堆高度的一半,所以插入和删除时间复杂度是O(logn)。但构建堆的时间复杂度却并不是O(nlogn),而是O(n)。
二叉堆的代码实现
二叉堆虽然是一个完全二叉树,但它的存储方式并不是链式存储,而是顺序存储。换句话说,二叉堆的所有节点都存储在数组中。没有左、右指针的情况下,如何定位一个父节点的左孩子和右孩子呢? 假设父节点的下标是parent,那么它的左孩子下标就是 2×parent+1;右孩子下标就是2×parent+2。
package 堆;
import java.util.Arrays;
/**
* 二叉堆的代码实现
* @author 15447
*
*/
public class Heap {
/**
* “上浮”操作
* @param array
*/
public static void upAdjust(int[] array) {
// 最后一个节点的下标
int childIndex = array.length - 1;
// 最后一个节点的父节点的下标
int parentIndex = (childIndex - 1) / 2;
// temp用于保存插入的叶子结点的值,用于最后的赋值
int temp = array[childIndex];
while(childIndex > 0 && temp < array[parentIndex]) {
// 无需真正交换,单向赋值
array[childIndex] = array[parentIndex];
childIndex = parentIndex;
parentIndex = (parentIndex - 1) / 2;
}
array[childIndex] = temp;
}
/**
* “下沉”操作
* @param array
* @param parentIndex 要下沉的父节点
* @param length 堆的大小
*/
public static void downAdjust(int[] array, int parentIndex, int length) {
// 保存父节点
int temp = array[parentIndex];
int childIndex = (parentIndex * 2) + 1;
while(childIndex < length) {
// 如果有右孩子并且右孩子的值小于左孩子,定位到右孩子
if (childIndex + 1 < length && array[childIndex + 1] < array[childIndex]) {
childIndex++;
}
// 如果父节点小于所有的子节点就跳出
if (temp <= array[childIndex]) {
break;
}
// 无需真正的交换,单向赋值
array[parentIndex] = array[childIndex];
parentIndex = childIndex;
childIndex = childIndex * 2 + 1;
}
array[parentIndex] = temp;
}
/**
* 构建堆
* @param array 待调整的堆
*/
public static void buildHeap(int[] array) {
// 从最后一个非叶子节点开始
for (int i=(array.length-2)/2; i>=0; i--) {
downAdjust(array, i, array.length);
}
}
public static void main(String[] args) {
int[] array = new int[] {1,3,2,6,5,7,8,9,10,0};
upAdjust(array);
System.out.println(Arrays.toString(array));
array = new int[] {7,1,3,10,5,2,8,9,6};
buildHeap(array);
System.out.println(Arrays.toString(array));
}
}
为什么快速排序要比堆排序性能好?
第一点:堆排序数据访问的方式没有快速排序友好。
对于快速排序来说,数据是顺序访问的。而对于堆排序来说,数据是跳着访问的。 比如,堆排序中,最重要的一个操作就是数据的堆化。比如下面这个例子,对堆顶节点进行堆化,会依次访问数组下标是 1,2,4,8 的元素,而不是像快速排序那样,局部顺序访问,所以,这样对 CPU 缓存是不友好的。

第二点:对于同样的数据,在排序过程中,堆排序算法的数据交换次数要多于快速排序。
快速排序数据交换的次数不会比逆序度多。堆排序的第一步是建堆,建堆的过程会打乱数据原有的相对先后顺序,导致原数据的有序度降低。比如,对于一组已经有序的数据来说,经过建堆之后,数据反而变得更无序了。