《Effective Java》读书笔记(已更新至24条)
《Effective Java》读书笔记目录,这篇文章记录了我读这本书的一些想法和验证,带水印刘屠户的java养猪场是我的公众号,考虑后面的源码解析同步到公众号中。
1. 考虑用静态工厂方法代替构造器
第一条,考虑用静态工厂方法代替构造器
优点一:静态工厂可以很好的理解名称

四个构造方法,面对这样的构造方法,三个、四个是可以接受的,那如果是七个八个甚至是十几个呢?这个时候有一个好的名字就是十分重要,比如书上提到的返回素数的方法名称:BigInteger.probablePrime(),这样的名称就可以很好地区分构建实例的用途,可读性也更强。
优点二:不必每次调用它们的时候都创建一个新的对象

类StaticFactoryDemo在初始化的时候会缓存10个对象到ArrayList中,可以实习对象的复用,这里只说大概意思,具体对象池、对象工厂实现可以参考Integer、Spring的IOC。
优点三:它们可以返回原返回类型的任何子类型的对象


为了方便阅读,不添加多余实现,在StaticFactoryDemo中创建的newInstance()方法用于创建实例,这个方法的实现中返回了子类的实例,使我们的代码更灵活。
优点四:在创建参数化类型实例的时候,他们使代码变得更加简洁。(已被优化)
作者的观点是过多参数会使代码看起来不是很简洁,如下代码。
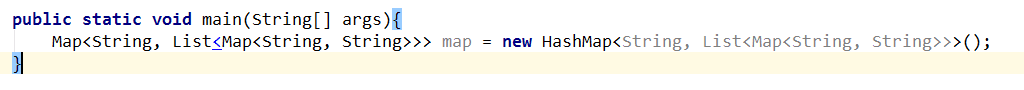
作者提供的解决办法是在HashMap中提供newIntance()方法,方法中返回复杂的泛型实例。
我的jdk版本为1.8,现在已经采取参数推断,做了优化,如下

静态工厂方法也是有缺点的
缺点一:类中如果不含有public或者protected修饰的构造方法,是无法拥有子类的。
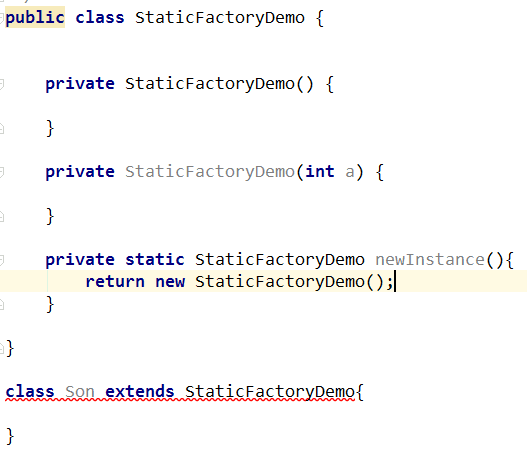
缺点二:如果没有一个漂亮的名字和注释,其他人是很难分清这个方法是不是用来构建实例的,静态工厂方法和普通静态方法实际上没有任何区别。
作者提供了一些名字供参考,valueOf、of、getInstance、newInstance、getType、newType。
总结:静态工厂方法可以提供给我们漂亮的可供区分的名字,可以提供缓存使对象复用,可以灵活的返回子类实例。同时要注意,如果没有提供公有或者受保护的构造方法时,是无法被继承的,起一个漂亮的易于理解的名称同样也很重要,注意要与设计模式中的工厂方法区分开。在需要创建对象时,要先考虑静态工厂方法,不要直接就选公有的构造方法。
2. 遇到多个构造器参数时要考虑用构造器
如果一个对象有多个参数时,应该如何处理?
代码大全2中提到过,一个函数的参数最好不要超过7个,我们熟悉的线程池参数就是7个,构造方法也不例外,在笔记本电脑中,一屏幕代码最多也就是7个左右的参数。
构建一个对象,通常我们会如何处理呢?
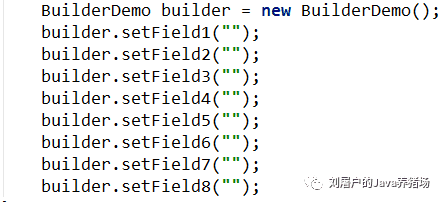
1、构造函数,下面的类BuilderDemo有8个属性

这样的代码是十分冗长的,如果有多个构造函数的话,是十分混乱的。
于是我们有个新的想法,创建这些属性的getter/setter方法
2、JavaBeans模式
这样的做法因为将设置属性分为了很多步,可能会出现线程安全问题,导致程序出现对象不一致的情况,需要开发人员自己去把控。
3、Builder模式
可耻的照扒了书中的代码如下:

![]()


过程就是创建一个静态内部类,成员变量通过final修饰保证线程安全,通过返回this,像链式一样调用。
总结:显然在参数过多的情况下,通过构造函数来构建对象的方式是不可取的,effective java作者推荐了Builder模式,从上面我们可以看出,其实增加了很多代码量(问号脸)JavaBeans的方式是可以通过编译器一键生成的,个人认为:从工作效率的角度看,JavaBeans的方式用的更多,而Builder的方式看起来更优雅。
- 用私有构造器或者枚举类型强化SingleTon属性
我们耳熟能详的单例有懒汉式、饿汉式等
例如下面这段的饿汉式
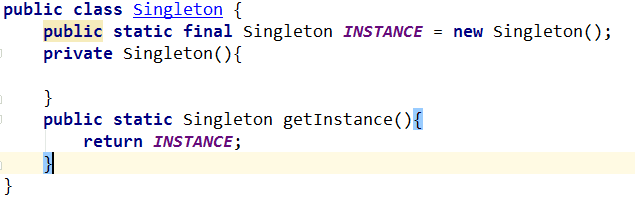
用private修饰构造方法,防止外界通过无参的构造方法直接创建对象,但是这样还是可以通过反射来攻击,造成代码的不安全,可以考虑设定一个变量,在创建第二个对象的时候抛出一个自定义的异常。
这样就安全了吗?
如果我将这个对象序列化到本地,然后再反序列化回来,这个对象还是原来的对象吗?不是的,这时可以考虑使用序列化的hock函数readResolve()来解决,当反序列化时,就会自动调用这个 readResolve方法来返回我们指定好的对象,如下图
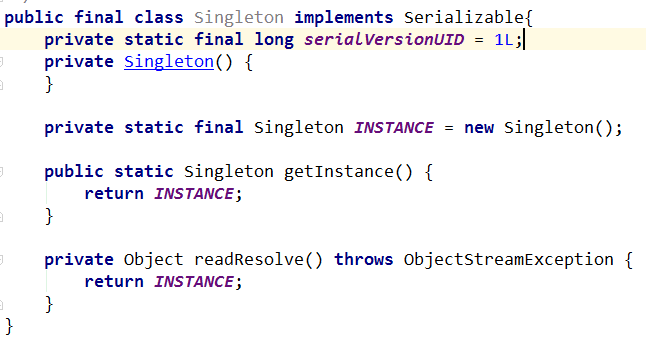
还有一种非常简洁的方式,通过枚举实现单例

Single就是要实现单例的类,通过SingeltonEnum.INSTANCE.getInstance()创建单例对象,枚举实际上是一种语法糖,反编译后会发现是由静态方法和匿名内部类组成。
总结:单例的实现有很多种,还有double-check,同步方法等方式实现,在这里不一一赘述,在effective java中作者强烈推荐枚举来实现高效安全的单例,不会被反射和序列化攻击所困扰。
4. 通过私有构造器强化不可实例化的能力
一些类是不希望其他类对它实例化的,比如java.util.Arrays、java.lnag.Math、java.util.Collections。我们发现这些类都会声明一个私有的构造方法,这样外界就无法通过默认无参的构造方法来创建这些类的对象,同时这些类也不能被继承。
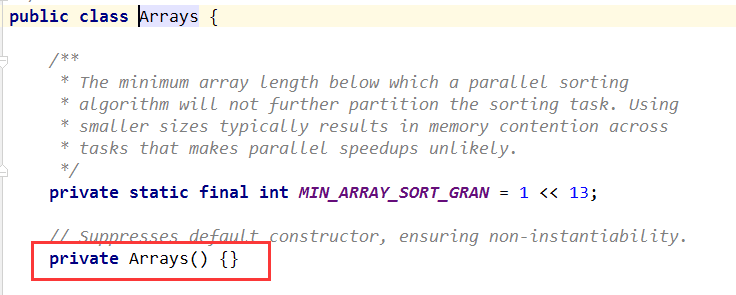
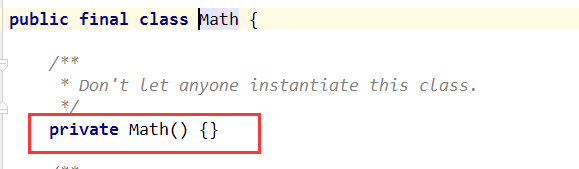

我们知道抽象类也是不可以被实例化的,那么为什么不使用抽象类呢?
抽象类是可以有子类的,而且抽象类的出现可能会让人误解它的用途,被人理解为是故意用来被继承的。
总结:通过private修饰无参的构造器,可以防止其他地方实例化该类的对象,但是同样这个类不会再有子类了,因为子类对象的创建,首先就要先访问父类的构造方法。
5. 避免创建不必要的对象
经典问题: 这两行创建了几个对象?第一行创建了几个,第二行创建了几个?
这两行创建了几个对象?第一行创建了几个,第二行创建了几个?
第一行创建了一个对象,第二行也是创建了一个对象。引用一共有两个,一个在虚拟机栈的栈帧的局部变量表中,另一个是在全局字符串池中(StringTable,本质上是个哈希表,池的位置视JDK的版本而定,1.6版本在方法区,1.7版本在堆,1.8从堆里面独立,被称为元空间),这个池中只保留被双引号修饰的字符串引用,实际对象还是存储在堆(heap)中,这个池子并不叫常量池。还有一种池子叫做运行时常量池,每个类在运行的时候都有自己独立的池,用来存储每个类的信息。
有人可能会这样说:当创建一个string对象的时候,去字符串常量池看一下是否有这个字符串,如果有就返回,没有就创建一个。
这样的说法是否存在问题呢?
是有问题的,intern()方法在1.7版本之前确实是这样,1.7之后,因为StringTable被放在了堆中,只是会把首次遇到的字符串实例的引用添加到全局字符串池中(没有复制),并返回此引用。intern()这个方法如果使用不当可能还导致YGC时间变长,原因是StringTable并不会存储这个字符串的引用,实际上对象还是在堆里面,也就是说每一次YGC的时候JVM都会扫描这个StringTable,StringTable过大就会影响YGC的时间,可以使用jmap -histo:live 加pid来强制进行一个full gc,full gc是可以对StringTable进行清理的。
Integer在内部也是有维护缓存池的,由一个名字叫做IntegerCache的缓冲池维护,范围为-128到127,如果使用了这个范围的数字包装类,多次使用同一个数字,会返回相同的对象。除double和float外,其他基本数据类型对应的包装类都有类似机制。

这种情况是不一样的,当对Long类型的数字进行计算时,由于Long是包装类,无法进行基本数据类型的计算,需要先转化为基本数据类型,这个过程叫拆箱,自动拆箱和自动装箱是JDK1.5版本提供的,在提供简便的同时也有这性能的损耗。
总结:在写代码过程中要避免创建不必要的对象,String类型的字符串尽量不要去new,如果有连结字符串的需求的话,可以考虑StringBuilder和线程安全的StringBuffer,二者底层和String一样,都是char数组,StringBuffer在方法上加上了synchornized,所以StringBuilder的性能要好一些,在后续版本,加号会被编译器优化为StringBuilder的append方式,但是由于规范和jdk版本问题,建议连结字符串使用append()方法。Integer下的缓冲池在某些情况是可以被破坏的,如果通过反射获取了缓冲池对象,修改缓冲池中的内容,结合printf()方法,会出现错误。包装类虽然有一点性能损耗,但是如果不是大量计算的话,不是很明显,况且包装的好处就是比如Integer的默认值是null,相比基本数据类型如int的默认是0,这样就很容易判断出有没有获取到值。
6. 消除过期的引用
引用书中的例子代码
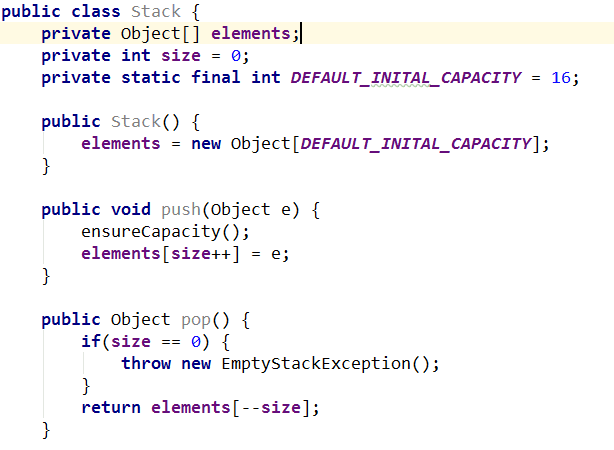

这段代码是有内存泄漏的隐患的,主要原因在pop()方法,pop()方法将一个元素从栈中弹出后,虽然size减少了,但是elements[]数组还持有着弹出元素的引用,从而引发内存泄漏。
解决办法是可以手动将这个元素的引用置为null。
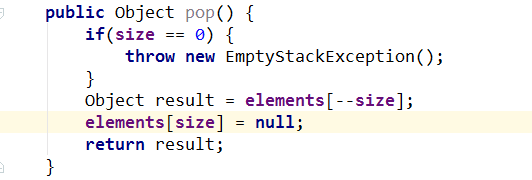
显然在写代码的时候不可能一直关注着引用,发现不用就置为null,这是不可取的,那么在什么时候应该注意引用的手动释放(也就是置为null)呢?作者给出的答案是,在需要自己管理内存的时候,比如栈这样的数据结构。
ThreadLocal也有可能出现内存泄漏的问题,ThreadLocal内部维护了一个ThreadLocaMap的静态内部类,ThreadLocal通过空间换时间的方式完成了线程间的隔离,ThreadLocalMap内部有个Entry静态内部类,存放了ThreadLocal类型的key和Object类型的value,如果ThreadLocal对象被回收,value是无法被回收的,ThreadLocal在设计的时候考虑到了这一点,在get()方法、set()方法、remove()方法都显示的将该引用置为null,同时使用了WeakRefrence来,该引用只能生存到下一次垃圾回收,value可以在下一次get()/set()/remove()的时候释放。不可以单纯的依赖WeakRefrence,比如线程池会一直持有下去导致内存泄漏,所以在使用ThreadLocal完毕后一定要手动释放remove(),就像ReentrantLock一样,使用完要释放锁,关于ThreadLocal详细内容这里不详细展开,大家有兴趣的话可以自行搜索。
缓存的场景也容易发生内存泄漏,比如在类的初始化的时候创建了一些缓存,这些缓存很容易被人遗忘掉,可以自己通过WeakRefrence或者定时任务自定义策略去把控。
总结:在开发中要特别注意防止代码发生内存泄漏,内存泄漏的原因往往是很难排查的,有时会依靠一些分析工具,最好的解决办法就是将问题在发生前扼杀。
7. 避免使用finalize()方法
首先说一下finalize()方法用来做什么,这是一个Object类的方法,也就是说所有类都会继承这个finalize()方法,这个方法默认实现为空,这个方法被用于在类对象被GC之前做一些收尾工作,但是被执行是有条件的,类重写的finalize()方法必须不为空。
首先JVM会先判断这个类是否重写了finalize()方法,并且这个方法不为空,如果满足这个条件会被标记。
在java.lang.ref包中的Finalizer类,如果一个类不再与引用链相连结,这意味着这个对象会被垃圾回收(关于这里不理解的可以自行搜索GCRoots),在回收之前会判断这个类是否已经重写了finalize()方法并且这个方法不为空,是否从未执行过finalize()方法(不理解可以搜索垃圾回收对象的二次拯救),如果同时满足这两个条件,才会考虑执行finalize()方法,并且不是直接执行的,下面简单介绍下具体流程。
如果同时满足以上两个条件的话,JVM会调用这个register()方法,这里创建Finalizer类的实例。
我们知道创建一个类的实例后调用顺序是这样的:
- 父类静态代码块
- 子类静态代码块
- 父类代码块
- 父类构造方法
- 子类代码块
- 子类构造方法

这个类的父类不在我们的讨论范围,我们可以直接看这个类的静态代码块。

这里主要是创建了一个优先级为3的守护线程并启动了它。

我们再来看这个类的构造方法。

首先这个构造方法时private,我们是无法继承这个类的,接下来看一下add()方法。

作用是将当前引用加入一个双向链表中,在这时我们可以发现宏观上这是一个由Finalizer类对象组成的一个队列,我们继续来看这个守护线程类的run()方法中的for循环中的代码,首先将队列中的引用移除,然后调用了runFinalizer()方法,我们来看看这个方法做了些什么?

首先,在同步代码块中判断是否已经执行过finalize()方法了,如果已经执行过,就直接移出队列,等待GC。如果没有执行过,就直接执行finalize()方法,这里是JVM来负责执行,最后调用父类的父类Refrence的clear()方法,将refrence设置为null,这样就可以等待垃圾回收了。
具体步骤并不仅仅是这些,这里只是分析finalize()的缺陷。读者有兴趣的话,可以看一下Refrence类中的队列的实现。
总结:finalize()在一些时候不保证会被执行,前面提到,因为是一个优先级为3的守护线程执行,所以在大量线程占有资源的时候,这个线程会很难获得CPU资源去执行,这个线程会等待执行,在等待的这段时间,有可能经历数次年轻代GC,大量对象晋升到老年代,有可能引发full gc甚至OOM。
8.覆盖equals()遵守通用约定
在Object类中的注释写到:
- 在java应用执行期间,只要对象的equals方法的比较操作所用到的信息没有被修改,那么对这同一对象调用多次hashCode方法都必须始终如一地同一个整数。在同一个应用程序的多次执行过程中,每次执行该方法返回的整数可以不一致。
如果两个对象根据equals(Object)方法比较是相等的,那么调用这两个对象中任意一个对象的hashCode方法都必须产生同样的整数结果。
如果两个对象根据equals(Object)方法比较是不相等的,那么调用这两个对象中任意一个对象的hashCode方法没必要产生不同的整数结果。但是程序猿应该知道,给不同的对象产生截然不同的整数结果,有可能提高散列表(hash table)的性能。
第二条划重点!!!先说结论,当一个类重写了equals()方法后,没有重写hashcode()方法时,会发生一些错误,那么什么情况下会出现这个错误呢?是什么错误呢?
对HashMap、HashTable、HashSet等集合类熟悉的同学应该清楚,这些函数通过将一个对象做hash,将多个对象均匀分布在散列桶中,当查找这个函数时,会先调用这个对象的hash()函数,寻找这个对象时在哪个桶中,然后通过equals()方法去比较。问题就出在这里,因为调用了这个对象的hashcode()方法,但是这个对象所属的类,只重写了equals()方法,并没有重写hashcode()方法,这里调用的是object()类的hashcode()方法!按照Object类中hashcode()的规则,默认只认为内存地址相同的对象,返回的hashcode才是相同的,这样会导致两个对象,在我们重写equals()的规则下,是相等的,但是却返回了不相等的hashcode。简单的说,首先我们向HashMap中存入了对象a在A桶,当我们查询的时候,我们去B桶去寻找,当然找不到了,查找的结果要么是null,要么是其他值,整个数据结构也就没有意义了。
作者推荐了重写hashcode()的方式如下:
int result = 17;
result = 31 * result + areaCode;
result = 31 * result + prefix;
result = 31 * result + lineNumber;
其中areaCode、prefix、lineNumber是当前类的属性。
为什么是17和31呢?
- 31是(2>>5)-1,通过位运算处理更快
- 17和31都是素数,有paper论证了素数可以使散列分布更均匀
- 一些虚拟机为31专门做了优化,从此约定俗成(网上查询,待印证)
9. 覆盖equals()时总是要覆盖hashcode()
在Object类中的注释写到:
- 在java应用执行期间,只要对象的equals方法的比较操作所用到的信息没有被修改,那么对这同一对象调用多次hashCode方法都必须始终如一地同一个整数。在同一个应用程序的多次执行过程中,每次执行该方法返回的整数可以不一致。
如果两个对象根据equals(Object)方法比较是相等的,那么调用这两个对象中任意一个对象的hashCode方法都必须产生同样的整数结果。
如果两个对象根据equals(Object)方法比较是不相等的,那么调用这两个对象中任意一个对象的hashCode方法没必要产生不同的整数结果。但是程序猿应该知道,给不同的对象产生截然不同的整数结果,有可能提高散列表(hash table)的性能。
第二条划重点!!!先说结论,当一个类重写了equals()方法后,没有重写hashcode()方法时,会发生一些错误,那么什么情况下会出现这个错误呢?是什么错误呢?
对HashMap、HashTable、HashSet等集合类熟悉的同学应该清楚,这些函数通过将一个对象做hash,将多个对象均匀分布在散列桶中,当查找这个函数时,会先调用这个对象的hash()函数,寻找这个对象时在哪个桶中,然后通过equals()方法去比较。问题就出在这里,因为调用了这个对象的hashcode()方法,但是这个对象所属的类,只重写了equals()方法,并没有重写hashcode()方法,这里调用的是object()类的hashcode()方法!按照Object类中hashcode()的规则,默认只认为内存地址相同的对象,返回的hashcode才是相同的,这样会导致两个对象,在我们重写equals()的规则下,是相等的,但是却返回了不相等的hashcode。简单的说,首先我们向HashMap中存入了对象a在A桶,当我们查询的时候,我们去B桶去寻找,当然找不到了,查找的结果要么是null,要么是其他值,整个数据结构也就没有意义了。
作者推荐了重写hashcode()的方式如下:
int result = 17;
result = 31 * result + areaCode;
result = 31 * result + prefix;
result = 31 * result + lineNumber;
其中areaCode、prefix、lineNumber是当前类的属性。
为什么是17和31呢?
- 31是(2>>5)-1,通过位运算处理更快
- 17和31都是素数,有paper论证了素数可以使散列分布更均匀
- 一些虚拟机为31专门做了优化,从此约定俗成(网上查询,待印证)
10.始终要覆盖toString()
打印出合适的容易阅读的toString()是十分优雅的,可以返回自己想要的,可阅读的格式,个人认为在开发阶段这个方法还是很好用的 -。-
11.谨慎的覆盖clone
首先说一些,clone()是什么?应该怎么用?
clone()方法是Object类中的方法,protected修饰符修饰,用来复制对象。
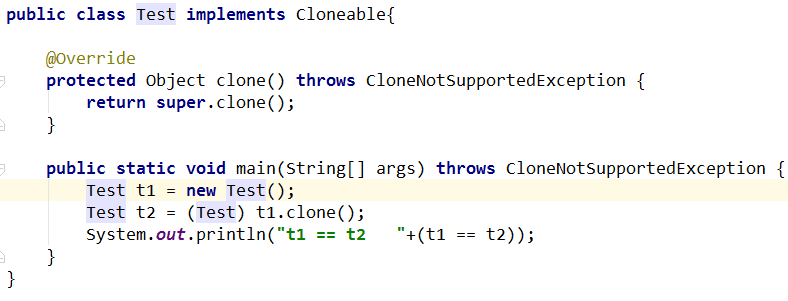
下面是结果: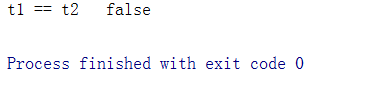
可以看到clone()创建了一个完全不同的对象,t2指向了一个新的在堆中的对象。使用clone()方法需要实现Cloneable接口,如果不实现的话会抛出CloneNotSupportedException,这个接口并没有什么实际意义,只是一个标记,用于区分这个类是否允许clone,这样的拷贝只是浅拷贝,并不会拷贝当前类中,其他类引用中的信息,如果要做到深度拷贝,可以在clone()方法中实现自己的拷贝逻辑,可以采取迭代或者递归等。还可以通过静态工厂和构造方法传入参数来实现clone()方法,好处是可以直接传入对象,不需要在代码中去强制转换。
总结:clone()默认实现的只是浅拷贝,如果想要完成对复杂对象的拷贝,还是需要自己写逻辑,这也是把双刃剑,clone()的使用确实方便快捷,但是自己实现逻辑会带来风险和编码上的负担,同时要注意clone的时候线程安全的问题。
12.考虑实现Comparable接口
Java实现了比较器,实现方式有两种,第一种方法是通过实现Comparable接口,重写它的compareTo()方法,这个方法的返回值是int,用户可以通过返回0,正数,负数,如1、0、-1来进行比较排序,示例如下:

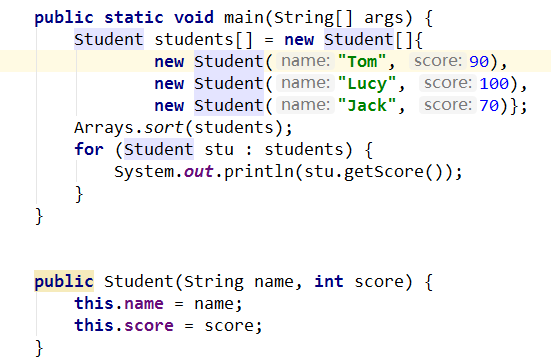
一个Student类,有两个属性,name和score,要求将分数从低到高排序。
运行结果:

第二种方法是使用Comparator,Comparator使用方法也是类似,二者区别是使用时可以不实现Comparator,在一些工具类如Arrays的方法中的参数可以放入Comparator的匿名内部类:
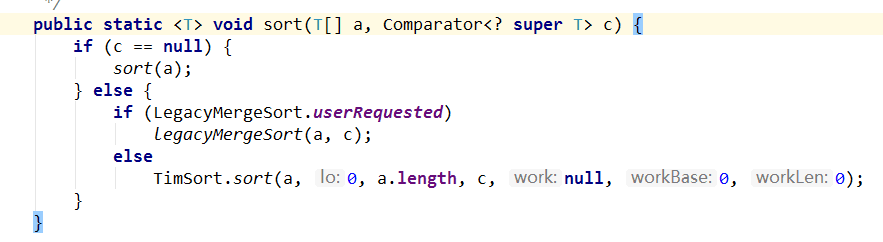
上面的比较方法,其实可以这样写:

这样写可能会有弊端,因为返回值是int类型,int的范围是-2147483648到2147483647,如果this.getScore() - stu.getScore()超过了这个范围会溢出,但是代码还是可以正常工作的,问题很难排查,因为根本没有报错。同时要注意,compareTo()/compare()方法内部返回值为0的逻辑尽量要与equals()相同。
13.使类和成员的可访问性最小化
Java通过封装和修饰符等手段限制访问权限,尽量降低类的可访问性,可以降低风险,应成员变量和成员方法的访问权限降低,尤其是成员变量,尽量使用private修饰,如果不是很有必要,不要使用成员变量,成员变量在并发条件下容易引发线程安全问题,为了防止出现这种问题,使用同步等方式会增加开销。
14.在共有类中使用访问方法而非公有域
这本书辣鸡翻译,根本看不明白它说的是啥,这个题目的意思是“尽量使用getter()/setter()方法来获取和设置成员变量的值,而不要使成员变量声明为public!”
15.使可变性最小化
16.复核优于继承
继承被认为是破坏封装性的表现。
17.要么为继承而设计,并提供文档说明,要么就禁止继承。
18.接口优于抽象类
Java不支持多继承,可以通过接口定义规则,类实现接口,重写接口里面的方法,这种方法比通过继承抽象类更好,当一些类有很多公共逻辑的时候,可以考虑放在抽象类中,注意抽象类是无法实例化的,切记接口的职责要单一!!!如果接口中定义规则(接口中的方法),类可能会Override一些没有必要重写的方法。
19.接口只用于定义类型
不要在接口中定义常量,可以通过定义专门的枚举类或者工具类来存放常量,也可以在类中定义常量。
20.类层次优于标签类
比如编程语言类,有一个公共语言类,搞两个编程语言类Java和Python继承继承这个语言类,在Java和Python中存放自己的属性和方法。不要搞一个枚举类存放类型,好多属性和方法堆在一起,不看好还不好维护。
21.用函数对象表示策略
文中提到了策略模式,策略模式是一种将逻辑下发到子类的去进行的操作,具体代码体现可以通过将通用逻辑封装到抽象类,具体逻辑使用多态下发到子类去完成,达到了可扩展。
22.优先考虑静态成员类
内部类一共有四种:静态成员类、非静态成员类、匿名内部类、局部内部类。
优先考虑静态内部类的原因是,创建非静态成员类时,这个类会持有外部类的对象,占有额外的空间和时间消耗,有兴趣的同学可以看一下HashMap的Node内部类,这个内部类是被static修饰的,是个静态内部类,用于提高效率。静态内部类实际上可以理解为与外部类独立开的一个类,之所以声明为静态内部类是因为这样可以起到一个标签的效果,为了告诉人们这个类是单独为外部类使用的,当用户使用这个内部类的时候,会有出现new OuterClass.StaticInnerClass(),提醒人们这个静态内部类StaticInnerClass是被OuterClass使用的。
总结:内部类是为外部类服务的,当一个功能作为一个组件为类提供服务,并且这段功能逻辑很复杂,不适合放在方法里面的时候,可以考虑体现为静态内部类,如果不涉及到效率问题,并且每个内部类的实例都需要一个指向外部类的引用的话,可以考虑将其声明为非静态内部类,匿名内部类多用于代码简写,比如线程的创建。
23.请不要在新代码中使用原生类型
使用泛型的好处是显而易见的,我们在代码编写的阶段就会发现错误,而不用等到运行时再去解决,之所以强调新代码,是因为泛型的推出是在1.5版本,在那时类库已经很庞大了,如果不使用泛型也不会报错,只会提示警告,是面向兼容性的一种妥协。
24.消除非受检警告
使用编译器完成代码编写的时候,可能会有黄色的波浪线提示警告,不要忽略它,每一处警告可能都是一个ClassCastException,可以使用
@SuppressWarnings(“uncheched”)消除警告,这个声明可以作用的范围十分广泛,类、方法、变量上都可以,尽可能的使作用范围小一些,在声明这个注解的时候最好加上注释,注明理由为什么这里是安全无须检查?