语音问答系统调研
因工作需要,准备开始做语音问答系统,之前对语音和自然语言处理(NLP)没接触过,所以开头还是很难的,历时两周做了一个大概的了解,适合像我这样的新手入门,里边借鉴了n多大神的内容,并给出了讲得比较好的网页、课程等等,如侵权请联系删除。。。
一 对话系统框架
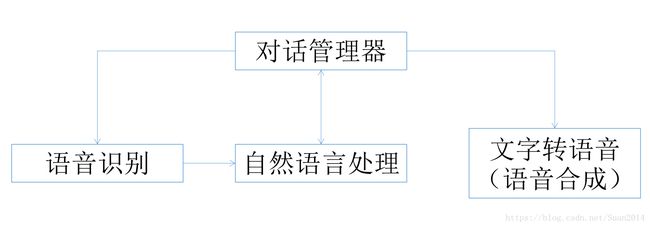
二 调研内容
- 语音识别-- Speech Recogniton, SR
- 闲聊型问答系统--Chitchat-bot
- 知识库问答--Knowledge base Question Answering,KB-QA
- 垂直领域QA
三 循环神经网络(RNN)基本类型
在语音识别和问答系统中,必不可少的就是循环神经网络(RNN)了,这里不对算法做详细介绍,只给出基本类型及应该学习了解的网络结构及其较好的学习资源。
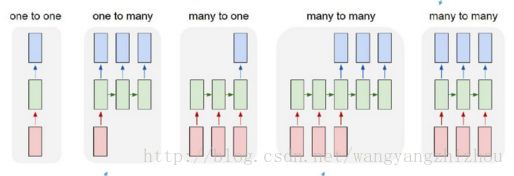
上图是RNN的基本类型,下边对其输入输出及其作用做一个大概的说明
- one to one: 给一个输入,得到一个输出,就是基本的网络结构,不含序列信息,比如我们常用的图像分类
- one to many:给一个输入,得到一系列输出,可用于image caption generation,输入一张图像,输出对该张图像的文字描述
- many to one: 给一系列输入,得到一个输出,可用于文本情感分类,如分析文本是积极的还是消极的
- many to many: 第四幅图像,输入和输出的序列数不一定相同,可用于机器翻译、问答系统等
- many to many: 第五幅图像,输入和输出的序列数相同,可用于字符预测、对视频的帧打标签等
需要提前了解的网络结构有RNN、 LSTM、 Attention机制,推荐李宏毅老师的课程:
http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLSD15_2.html
四 语音识别的前世今生
前世
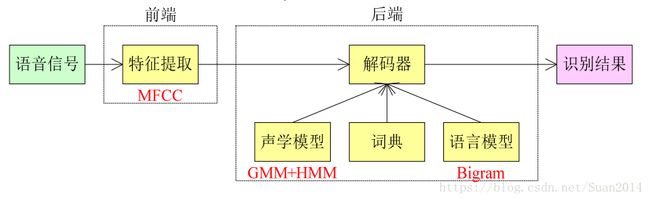
从1990年到2010年,语音识别多采取上述框架,下边对上述框架的部分做一简要解析
预处理:
1. 首尾端的静音切除,降低对后续步骤造成的干扰,静音切除的操作一般称为VAD(语音激活检测);
2. 声音分帧,也就是把声音切开成一小段一小段,每小段称为一帧,使用移动窗函数来实现,不是简单的切开,各帧之间一般是有交叠的;
特征提取:
主要算法有线性预测倒谱系数( LPCC)和Mel 倒谱系数( MFCC),目的是把每一帧波形变成一个包含声音信息的多维向量;
声学模型( AM):
通过对语音数据进行训练获得,输入是特征向量,输出为音素信息;常用算法为GMM+HMM;
字典:
字或者词与音素的对应, 简单来说, 中文就是拼音和汉字的对应,英文就是音标与单词的对应;
语言模型( LM) :
通过对大量文本信息进行训练,得到单个字或者词相互关联的概率;常用算法为: n-gram模型;
解码:
就是通过声学模型、字典、 语言模型对提取特征后的音频数据进行文字输出;
上述模块中涉及到很多知识,在此列出本人觉得比较好的链接,部分内容我也已经转载,但是为了尊重原创,还是给出原文链接:
- MFCC算法请参看: https://www.cnblogs.com/BaroC/p/4283380.html
https://blog.csdn.net/xueyingxue001/article/details/53183757
- GMM+HMM算法详解请参看:https://blog.csdn.net/davidie/article/details/46929269 以及 https://www.zhihu.com/lives/843853238078963712
- n-gram模型请参看:https://blog.csdn.net/ahmanz/article/details/51273500
今生
今生主要得益于神经网络,主要思想就是用DNN取待原有模块,或做最后的大融合


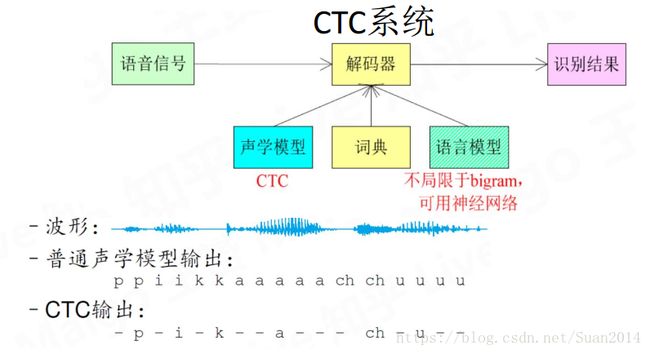

上述涉及到的知识如果想要详细了解请参考以下链接:
- 对声波型号如何转化为可输入到神经网络的向量请参看https://zhuanlan.zhihu.com/p/24703268
- 关于语音识别的前世今生及其算法的详细解释请参看https://www.zhihu.com/lives/843853238078963712
五 闲聊型问答系统
Seq2Seq
在闲聊型问答系统介绍之前不得不先请出该系统的明星:Seq2Seq
其模型结果如下所示:
- 每个单元是循环神经网络,如: RNN、 LSTM、 GRU等, LSTM居多;
- seq2seq属于encoder-decoder结构中的一种, encoder将一个可变长度的信号序列变为固定长度的向量表达, Decoder将这个固定长度的向量变成可变长度的目标信号序列。
- 该模型有很多变体,如加入注意力机制、记忆力模型等

说明: 上上一个模型为训练模式,即decoder的输入为ground truth,上个模型为部署模式,在测试时, decoder的输入为其上一时刻的输出
闲聊式问答系统框架

分词
概念
a) 中文分词指的是将一个汉字序列切分成一个一个单独的词。 分词就是将连续的字序
列按照一定的规范重新组合成词序列的过程。
中文分词方法
a) 基于字符串匹配的分词方法
b) 基于理解的分词方法 ( 处于试验阶段)
c) 基于统计的分词方法
d) 实际使用时结合a)和c)
中文分词工具
jieba分词、 SnowNLP、 THULAC、 NLPIR
词嵌入( Word Embedding)
概念
a) 是一种词的类型表示, 具有相似意义的词具有相似的表示, 是将词汇映射到实数向
量的方法总称。
独热码( one-hot encoding)
a) 将词表示为很长的向量, 词的维度是词表大小, 绝大多数维度为0, 只有一个维度为
1
b) “ 可爱” [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 ……]
常用算法
a) word2vec:详细算法请参看http://www.dataguru.cn/article-13488-1.html Skip-gram及CBOW算法详解及训练过程请参看cs224d视频的第2节课的内容
Seq2Seq
工具
a) Tensorflow embedding_attention_seq2seq的API接口
b) 接口参数请参看http://www.shareditor.com/blogshow?blogId=136
c) 该接口融合了word embedding 和attention机制
d) seq2seq详细算法讲解请参看 https://blog.csdn.net/Irving_zhang/article/details/78889364
自然语言生成( Word Embedding)
算法
a) 贪婪搜索:输出序列的每一步中输出最有可能的单词
b) 集束搜索( beam search) :返回可能性最大的输出序列列表
c) 详细讲解请参看: https://www.sohu.com/a/159397046_206784
知识库问答系统(KB-QA)
- 概念
给定自然语言问题,通过对问题进行语义理解和解析,进而利用知识库进行查询、推理得出答案。
- 应用场景
适合回答when,what等事实性问题,回答的答案是知识库中的实体或实体关系
- 知识库
利用三元组存储(实体entity, 实体关系relation, 实体entity),如(姚明,出生地,上海)
- 主流方法
语义解析
思想在于将人类使用的自然语言句子转化为机器可以理解的逻辑形式,通过数据库得出答案。
信息抽取
思想在于通过抽取句子中的特征信息和知识库中相关实体的特征信息,用以上特征训练分类器对候选答案排序得出答案。
向量建模
思想在于将知识库的实体和自然语言句子都映射到同一个向量空间中,通过比较相似度寻找答案。
深度学习
应用于语义解析、向量建模;采用记忆网络、 Attention机制
动态模型
思想在于预定义一些网络模块,通过对问题进行解析,针对问题使用不同的
模块组合出动态模型进行回答。
参考资料
知乎专栏 https://zhuanlan.zhihu.com/p/27141786
垂直领域QA
对话系统
基于检索的对话系统 (面向具体任务的问答新系统)
模式: s1,s2->R, 即字符串s1和s2符合一定的规则
将回复使用的数据预先存储, 优点为回复的内容不会有语
法和语义的错误;
缺点:不会创造新的回答, 无法对未训练的问题作出回答
- 基于生成的对话系统 ( chitchat-bot, KB-QA)
模式: s1->s2, 即由字符串s1得到s2
- 趋势
具有上述两种功能的混合对话系统
说明
- 现大部分采用对用户的问题与已有的问句计算语义相似度并排序选出最相似的问句, 再使用这句问句的应答句回答用户;
- https://blog.csdn.net/coder_oyang/article/details/72731419涉及知识图
- http://www.sohu.com/a/115593961_465975 http://www.sohu.com/a/140243692_500659 2017年之前的较好的检索式对话论文( 可通过此了解关键词, 查询较新的论文)
- https://zhuanlan.zhihu.com/p/31638132 示例
总结
- 相关知识比较庞杂,基础知识比较欠缺的情况下,刚开始学起来可能成就感较低,弄清楚一个知识点可能需要查阅许多资料;
- 传统方法比较多,比较难理解; 但是不要灰心,不断学习总能掌握