DataNode心跳机制的作用讲解了DataNode的三个作用:
- register:当DataNode启动的时候,DataNode需要将自身的一些信息(hostname, version等)告诉NameNode,NameNode经过check后使其成为集群中的一员,然后信息维护在
NetworkTopology中 - block report:将block的信息汇报给NameNode,使得NameNode可以维护数据块和数据节点之间的映射关系
- 定期的send heartbeat
- 告诉NameNode我还活着,我的存储空间还有多少等信息
- 执行NameNode通过heartbeat传过来的指令,比如删除数据块
以上第1和第2个动作都是在DataNode启动的时候发生的,register的步骤主要功能是使得这个DataNode成为HDFS集群中的成员,DataNode注册成功后,DataNode会将它管理的所有的数据块信息,通过blockReport方法上报到NameNode,帮助NameNode建立HDFS文件数据块到DataNode的映射关系,这一步操作完成后,DataNode才正式算启动完成,可以对外提供服务了。
由于NameNode和DataNode之间存在主从关系,DataNode需要每隔一段时间发送心跳到NameNode,如果NameNode长时间收不到DataNode节点的心跳信息,那么NameNode会认为DataNode已经失效。NameNode如果有一些需要DataNode配合的动作,则会通过心跳返回给DataNode,心跳返回值是一个DataNodeCommand数组,它是一系列NameNode的指令,这样DataNode就可以根据指令完成指定的动作,比如HDFS文件的删除。
HDFS文件的删除
Java基本操作HDFS API的最后讲解了HDFS文件的删除原理,HDFS文件删除的示例代码如下:
package com.twq.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URI;
public class FileDeleter {
public static void main(String[] args) throws IOException {
String dest = "hdfs://master:9999/user/hadoop-twq/cmd/java_writer.txt";
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.get(URI.create(dest), configuration);
fileSystem.delete(new Path(dest), false);
}
}
HDFS文件的删除很简单,我们看下HDFS文件删除的流程图:
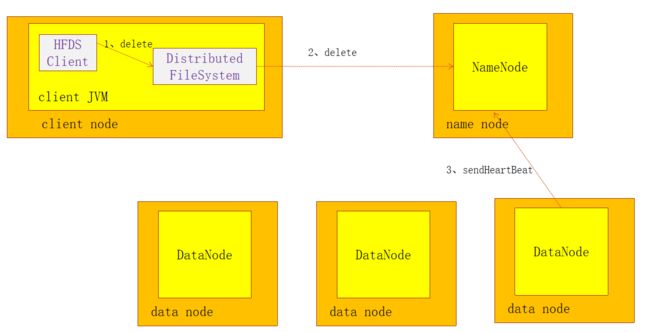
流程图其实也是很简单,步骤如下:
- 客户端创建一个
FileSystem实例 - 调用
FileSystem的delete方法,这个时候会向NameNode发起删除文件的请求,这个时候在NameNode中会删除对应的文件的元数据,并将这个文件标记为删除,但是这个文件对应的数据块并不会删除 - 当需要删除的文件对应的数据块所在的DataNode向NaneNode发了心跳后,NameNode将需要删除这个文件对应数据块的指令通过心跳返回给DataNode,DataNode收到指令后才会真正的删除数据块
总结
DataNode预NabeNode之间的交互非常的简单,大部分都是DataNode到NameNode的心跳,考虑到一个规模的HDFS集群,一个名字节点会管理上千个DataNode,所以这样的设计也非常自然了。