什么是k近邻算法,K近邻算法:Fackbook最近入住预测
目录
1.什么是k近邻算法
2.K近邻算法与标准化
3.K近邻算法:Fackbook最近入住预测
参考文档
1.什么是k近邻算法
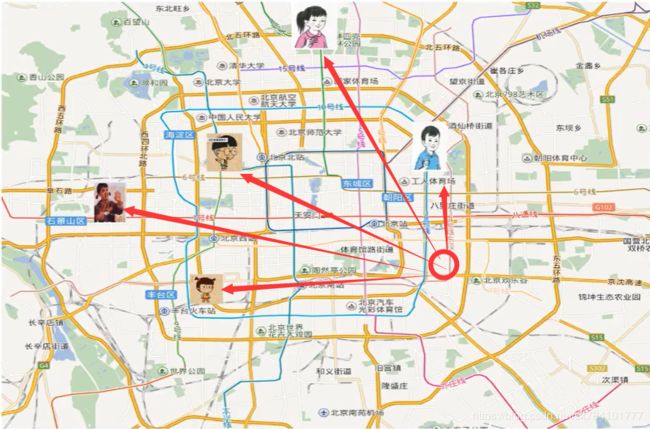
设想一个场景,在地图上,一个人处于圆圈位置,他需要知道自己在哪个区(事实上它处于朝阳区)。假设这个人不能看地图,但是他可以询问地图上的5个朋友,于是他逐个去问,他是这么问的:请告诉我你距离我多远以及你处在哪个区?于是乎5个人分别告诉他们里此人的距离,其中穿蓝色衣服的(如图所示)说出的距离与他最近,同时告诉他自己身处朝阳区。于是这个人得出结论:我和穿蓝色衣服的朋友最近,他处在朝阳区,那么我也在朝阳区。
以上就是k近邻的抽象化表达。
下面在来看一个例子
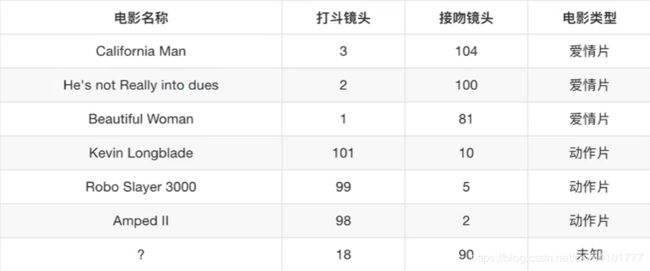
以下有七部电影,3部爱情片,3部动作片,还有一个未知类型未知名的电影。我们现在需要判断该未知电影最有可能属于哪类电影,是爱情片还是动作片?
怎么求呢,这里引入一个计算方法,求欧式距离,公式如下
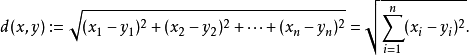
i代表维度(或特征数),这里有两个特征,一个接吻镜头,一个打斗镜头。
我们试着求出California Man与改未知电影的欧氏距离
d=√((18-3)^2+(90-104)^2)=20.5
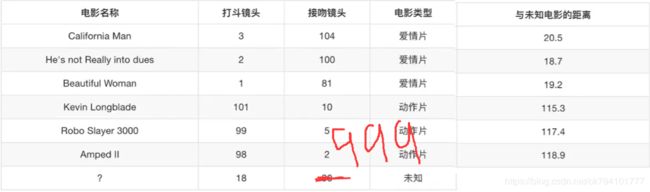
再依次求出其他电影的欧氏距离,结果如图所示。我们发现欧式举例最小的He's not Really into dues,它是一部爱情片。那么这个未知电影是爱情片的可能性更大。根据欧式距离公式可以看出,两组样本的特征值越靠近,求出的距离也越小,两者的相似性也越高、

K近邻算法定义:如果一个样本在特征空间中国的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
补充:k近邻算法是分类算法中的一种
2.K近邻算法与标准化
还是电影的例子,假设未知电影的一个特征非常大(或非常小),对欧式距离的求值是非常有影响的
如接吻镜头变为999,则
d=√((18-3)^2+(999-104)^2)=√(225+801025)
某单一特征对距离影响太大,导致其他特征被忽视。我将在后续的例子中展示标准化对预测准确度的影响。
3.K近邻算法:Fackbook最近入住预测
Kaggle地址:https://www.kaggle.com/c/facebook-v-predicting-check-ins/data
In this competition, you are going to predict which business a user is checking into based on their location, accuracy, and timestamp.
The train and test dataset are split based on time, and the public/private leaderboard in the test data are split randomly. There is no concept of a person in this dataset. All the row_id's are events, not people.
Note: Some of the columns, such as time and accuracy, are intentionally left vague in their definitions. Please consider them as part of the challenge.
File descriptions
- train.csv, test.csv
- row_id: id of the check-in event
- x y: coordinates
- accuracy: location accuracy
- time: timestamp
- place_id: id of the business, this is the target you are predicting
- sample_submission.csv - a sample submission file in the correct format with random predictions
以上大致说明里这样一件事:
这个比赛的目标是预测一个人想去哪个地方报到。为了这次比赛,Facebook创造了一个由10万个地点组成的人工世界,这个世界位于10公里乘10公里的广场上。对于给定的一组坐标,您的任务是返回最有可能的位置的排序列表。数据被编造成类似于来自移动设备的定位信号,让您了解如何处理由不准确和噪声值复杂的真实数据。不一致和错误的位置数据可能会破坏Facebook等服务的体验。
我们来看看给出了哪些特征:
- row_id: 登记事件id
- x y: 坐标
- accuracy: 定位准确性
- time: 时间戳
- place_id: 事件id,预测的目标
上程序
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import pandas as pd
def kncls():
#读数据集
data=pd.read_csv("datas/train.csv")
#由于数据量过于庞大,只取一部分数据做试验
data=data.query("x>0 & x<0.5 & y>0 & y<0.5")
#处理时间格式,时间戳->秒
time_value=pd.to_datetime(data["time"],unit="s")
#日期格式转换为字典
time_value=pd.DatetimeIndex(time_value)
#构造日期特征
data['day']=time_value.day
data['hour']=time_value.hour
data['weekday']=time_value.weekday
#删除时间戳
data.drop(['time'],axis=1)
#根据place_id进行分组
place_count=data.groupby('place_id').count()
tf=place_count[place_count.row_id > 4 ].reset_index()
data=data[data['place_id'].isin(tf.place_id)]
#去除无用的特征
data.drop(['row_id'], axis=1)
#拆分特征值与目标值
y=data["place_id"] #目标值
x=data.drop(["place_id"],axis=1) #特征值,去除目标值
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25)
# 对训练集做标准化
std = StandardScaler()
#对训练值进行标准化
x_train=std.fit_transform(x_train)
x_test=std.fit_transform(x_test)
#使用k近邻算法做目标值估计
knn=KNeighborsClassifier(n_neighbors=5)
knn.fit(x_train,y_train)
print("准确度:",knn.score(x_test,y_test))
if __name__ =="__main__":
kncls()1)数据抽样
我们逐行分析,首先是读程序,由于数量过于庞大,只拿一部分数据来作分析即可(当然你电脑好也可以不做过滤)
#读数据集
data=pd.read_csv("datas/train.csv")
#由于数据量过于庞大,只取一部分数据做试验
data=data.query("x>0 & x<0.5 & y>0 & y<0.5")
以上的操作就是取整个区域的一部分
打印一下数据看看效果(print(data)):一共是78733条

2)时间戳处理
我们看到time这一行,time在这里是入住时间,是以时间戳来显示的,以计算机起始时间1970-01-01向后取秒。
这里我们将时间戳转换为看的懂的 年-月-日 时-分-秒 形式。实际上这么做不仅仅是为了好看,也是为了拆分时间戳来增加特征数量,以助于后面的特征分析。
#处理时间格式,时间戳->秒
time_value=pd.to_datetime(data["time"],unit="s")
#日期格式转换为字典
time_value=pd.DatetimeIndex(time_value)
这里使用到了pandas的时间处理函数to_datetime(), 作用是将时间戳转换为年-月-日 时-分-秒 形式。
我们再通过DatetimeIndex()函数转换为字典格式,可通过打印time_value看看原始格式:
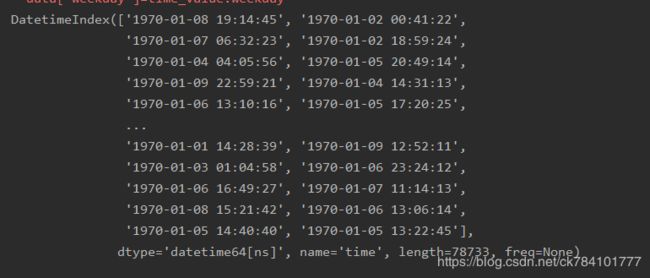
做完以上步骤,我们就可以通过调用time_value.day,time_value.hour,time_value.weekday来获取天,小时,星期,然后在data原始数据中创建新的列。为什么是获取天,小时,星期呢,可以看到原始数据都是1970年1月份的数据(人造数据),所以获取年或月的意义不大。
#构造日期特征
data['day']=time_value.day
data['hour']=time_value.hour
data['weekday']=time_value.weekday#删除时间戳
data.drop(['time'],axis=1)
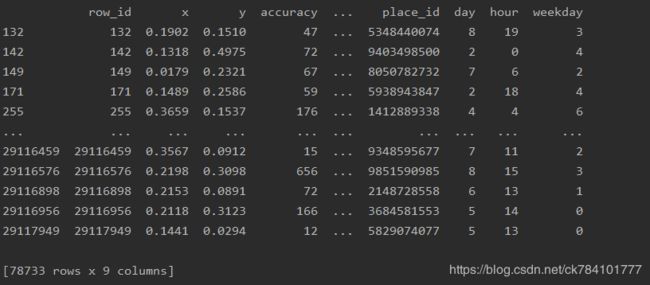
补充:pandas.DatetimeIndex()源码提供以下字典键

打印查看一下效果:
3)取高频目标值
place_id是我们的目标值,我们可以取高频次的目标值来构造新的训练数据集。为什么这么做?设想一下,当一家酒店旁的样本数数量更多,当新加入一个样本,那么它邻居的个数也就越多,k近邻在求欧式距离时取这些邻居的可能性也就越大,而该样本的实际目标值就是这家酒店,对于预测准确性有很大帮助。
如图所示,黑色代表入住的酒店,6个红圈为入住该酒店的样本,蓝圈代表待求目标值的样本,若它旁边的邻居都入住该酒店,则这个新的样本入住该酒店的可能性就非常大。
下面就是对目标值进行筛选的程序表达,首先groupby('place_id').count()对place_id进行分组。
place_count[place_count.row_id > 4 ].reset_index()将place_id仅出现4或4此以下的过滤掉。reset_index()函数将创建一个新的字典集。
最后重构data,a.isin(b),取a与b的交集
#根据place_id进行分组
place_count=data.groupby('place_id').count()
tf=place_count[place_count.row_id > 4 ].reset_index()
data=data[data['place_id'].isin(tf.place_id)]
打印tf看下输出:
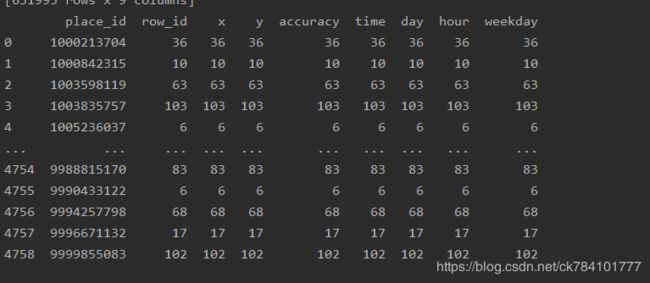
4)最数据集进行拆分
拆分数据集,构成训练集与测试集。目标值值为place_id,从数据集中划出来构成x,y仅存放目标值做对比验证。
#拆分特征值与目标值 y=data["place_id"] #目标值 x=data.drop(["place_id"],axis=1) #特征值,去除目标值 x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25)
5)标准化处理
标准化处理是必须要做的,否则极其容易受到异常数据的影响
# 对训练集做标准化 std = StandardScaler() #对训练值进行标准化 x_train=std.fit_transform(x_train) x_test=std.fit_transform(x_test)
6)调用k近邻算法进行预测精确性判断
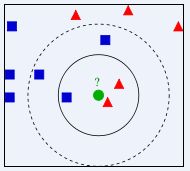
n_neighbors为邻居数,取值由什么讲究呢,这里插入一个小的例子
如图所示,当:
-
K=3,绿色圆点的最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
-
K=5,绿色圆点的最近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类
#使用k近邻算法 knn=KNeighborsClassifier(n_neighbors=5) knn.fit(x_train,y_train) print("准确度:",knn.score(x_test,y_test))
7)执行程序
输出结果为:

好吧,确实挺低的- -,最大的原因可能在与我们对数据集进行了抽样,导致在这个范围内的某些样本的目标值不在这个范围。读者可以验证一下不做抽样后的结果,可以下方留言打出。目前score排名最高的是0.62279,可去官网看看他怎么处理数据的。
4.总结
Fackbook最近入住预测这个案例是非常具有代表性的,我们大致回顾一下我们对数据进行了怎样的处理,以提高k近邻算法预估的准确性。
1、缩小数据集范围
这个对算法本身没影响,只是受限与CPU算力,读者可以尝试不做此步,我的电脑是需要计算半个小时。
2、处理日期数据
此操作增加了数据维度,将时间戳拆分为若干个时间特征,对算法本身影响不大。但是也可以这样设想一下,某人习惯于每个月的第一天去指定的一家酒店入住,这样的人多了,对算法计算就有影响了。
3、过滤无用的特征
类似与id号这种对预估没有帮助的特征可删除。这里的id为row_id,仅用于记录id号。
4、将入住酒店次数少于n的样本过滤
这是对算法准确性影响最大的一条了,前文也说了,入住次数少的酒店不划分进分类,对于整体的正确性是有帮助的。但是也不绝对,此做法的缺点是:入住次数少的酒店被过滤了,从而导致没有正确的目标值,而当某个样本恰巧是要入住该酒店,那么其给出的预测结果就一定是错的。
如图所示,红圈(待预测样本)的邻居为3黑一行黄,若红圈实际上要入住黄色酒店,而预测结果却给到了黑色酒店,那么这些黑圈就对预测值造成了干扰,称为噪音,减少噪音的方法要么是增大k值(k近邻算法中的邻居数),要么是增大样本数量。在这个案例中,我们能做的只有增大k值,但是增大k值又会导致产生更多的噪音(更多的样本对预测起作用了)
说些题外话,看到这是不是感受到机器学习的矛盾了,所以仅仅只是知道用算法还不够,还需要学会做数据做处理,对算法参数做调整。
但是由于入住少的酒店在本例中仅为极小数(1%),所以我们干脆放弃1%的正确性,追求整体更高的预测性。
5、k近邻算法的k值
K 近邻算法使用的模型实际上对应于对特征空间的划分。K 值的选择,距离度量和分类决策规则是该算法的三个基本要素:
-
K 值的选择会对算法的结果产生重大影响。K值较小意味着只有与输入实例较近的训练实例才会对预测结果起作用,但容易发生过拟合;如果 K 值较大,优点是可以减少学习的估计误差,但缺点是学习的近似误差增大,这时与输入实例较远的训练实例也会对预测起作用,使预测发生错误。在实际应用中,K 值一般选择一个较小的数值,通常采用交叉验证的方法来选择最优的 K 值。随着训练实例数目趋向于无穷和 K=1 时,误差率不会超过贝叶斯误差率的2倍,如果K也趋向于无穷,则误差率趋向于贝叶斯误差率。
-
该算法中的分类决策规则往往是多数表决,即由输入实例的 K 个最临近的训练实例中的多数类决定输入实例的类别
-
距离度量一般采用 Lp 距离,当p=2时,即为欧氏距离,在度量之前,应该将每个属性的值规范化,这样有助于防止具有较大初始值域的属性比具有较小初始值域的属性的权重过大。
参考文档
欧式举例公式:https://www.cnblogs.com/xregan/p/11006912.html
k近邻算法讲解与代码实现:https://www.cnblogs.com/ishero/p/11136304.html
数据预处理,标准化:https://blog.csdn.net/ck784101777/article/details/107136002
k近邻算法:https://blog.csdn.net/legendayue/article/details/96007093
k近邻算法百度解释:https://baike.baidu.com/item/k%E8%BF%91%E9%82%BB%E7%AE%97%E6%B3%95/9512781?fr=aladdin