sql server 性能_SQL Server预读机制; 概念和性能提升
sql server 性能
The user’s read requests in SQL Server are managed and controlled by the SQL Server Relational Engine, that is responsible for determining the most optimized access method, such as index scan or table scan, to retrieve the requested data. These read requests are also optimized internally by the SQL Server Storage Engine, the buffer manager components specifically, that is responsible for determining the general read pattern to be performed.
用户在SQL Server中的读取请求由SQL Server Relational Engine管理和控制,该引擎负责确定最优化的访问方法,例如索引扫描或表扫描,以检索请求的数据。 这些读取请求还由SQL Server存储引擎 (特别是缓冲区管理器组件)在内部进行了优化,该组件负责确定要执行的常规读取模式。
When you submit a query to request data in SQL Server, the SQL Server Database Engine will request that data pages that are required for your query from the buffer cache, performing a logical read. If these pages are not found in the buffer cache, a physical read will be performed to copy the pages from the disk into the buffer cache.
当您提交查询以请求SQL Server中的数据时,SQL Server数据库引擎将从缓存中请求查询所需要的数据页,从而执行逻辑读取。 如果在缓冲区高速缓存中找不到这些页面,则将执行物理读取以将页面从磁盘复制到缓冲区高速缓存中。
Although the SQL Server query optimizer tries to do its best in providing the most optimal execution plan that helps to retrieve the data requested by the user, you may still face CPU or I/O performance issues while executing the query. SQL Server provides us with many features that help in optimizing the data retrieval performance in order to respond to the user’s requests as fast as possible. One of these useful features is the read-ahead mechanism. As the name indicates, using the read-ahead mechanism, the SQL Server Storage Engine brings the data and index pages into the buffer cache, up to 64 contiguous pages per each file, before they are actually requested by the SQL Server Relational Engine, to respond for the user’s query. This provides more possibilities to find the data page in the buffer cache when it is requested and optimizes I/O performance by performing more logical reads, which is faster than physical reads. It allows also for computation overlap that helps in reducing the CPU time required to execute the queries.
尽管SQL Server查询优化器尝试尽最大努力提供有助于检索用户请求数据的最佳执行计划,但是在执行查询时,您仍然可能会遇到CPU或I / O性能问题。 SQL Server为我们提供了许多功能,可帮助优化数据检索性能,从而尽可能快地响应用户的请求。 这些有用的功能之一是预读机制。 顾名思义,SQL Server存储引擎使用预读机制将数据和索引页带入缓冲区高速缓存,每个文件最多包含64个连续页,然后才由SQL Server Relational Engine实际请求它们。响应用户的查询。 这提供了更多在请求时在缓冲区高速缓存中查找数据页的可能性,并通过执行更多的逻辑读取(比物理读取更快)来优化I / O性能。 它还允许计算重叠,这有助于减少执行查询所需的CPU时间。
SQL Server provides us with two types of read-ahead mechanisms: sequential read-ahead and random prefetching read-ahead mechanisms. In the sequential read-ahead mechanism, the pages will be read in allocation order or index order depending on what is being processed. For tables that are not sorted, in any order, due to having no clustered index, also called heap tables, the data will be read in the allocation order. In such cases, the SQL Server Storage Engine builds its own sorted list of addresses to be read from the disk by reading the Index Allocation Map pages, that contains a list of extents that are used by each table or index. The sorted addresses list allows the SQL Server Storage Engine to perform optimal sequential reads for the data in the disk, based on the extent addresses stored in the IAM. On the other hand, index pages will be read sequentially in key order. In this case, the SQL Server Storage Engine will scan the intermediate nodes of B tree structure of the index to prepare a list of all keys to be read from the leaf level nodes, recalling that the keys are stored in the leaf level nodes of the index.
SQL Server为我们提供了两种类型的预读机制: 顺序 预读机制和随机预取预读机制。 在顺序预读机制中,将根据处理的内容以分配顺序或索引顺序读取页面。 对于没有排序的表,由于没有聚簇索引(也称为堆表),因此不按任何顺序排序,将按分配顺序读取数据。 在这种情况下,SQL Server存储引擎将通过读取“索引分配映射”页面来构建要从磁盘读取的地址排序列表,该页面包含每个表或索引使用的扩展区列表。 排序地址列表允许SQL Server存储引擎根据IAM中存储的扩展区地址,对磁盘中的数据执行最佳顺序读取。 另一方面,索引页将按键顺序顺序读取。 在这种情况下,SQL Server存储引擎将扫描索引的B树结构的中间节点,以准备要从叶级节点读取的所有键的列表,并回想这些键已存储在索引的叶级节点中。指数。
A random prefetching read-ahead mechanism is used to speed up the fetching of data from non-clustered indexes, where the leaf level nodes contain only pointers to the data rows in the table or the clustered index. In this case, the SQL Server Storage Engine will read the data rows, asynchronously, that it already retrieves its pointers from the non-clustered index. In this way, the underlying table’s data rows will be fetched using the SQL Server Storage Engine before completing the non-clustered index scan. The number of pages to be read ahead is not configurable and depends on the edition of the SQL Server, with the Enterprise edition having the most number of allowed pages.
随机预取预读机制用于加快从非聚簇索引中获取数据的速度,其中叶级节点仅包含指向表或聚簇索引中数据行的指针。 在这种情况下,SQL Server存储引擎将异步读取数据行,因为它已经从非聚集索引中检索了其指针。 这样,在完成非聚集索引扫描之前,将使用SQL Server存储引擎来提取基础表的数据行。 预先读取的页面数是不可配置的,并且取决于SQL Server的版本,其中企业版具有允许的页面数最多的版本。
To understand how the read-ahead will affect the performance in practical terms, let’s go through the following example. We will create a simple testing table, using the CREATE TABLE T-SQL statement below:
要了解预读将如何实际影响性能,让我们看一下下面的示例。 我们将使用下面的CREATE TABLE T-SQL语句创建一个简单的测试表:
USE SQLShackDemo
GO
CREATE TABLE ReadAheadDemo
(
ID INT IDENTITY (1,1) PRIMARY KEY,
CustName VARCHAR(50),
CustAddress NVARCHAR(MAX)
)
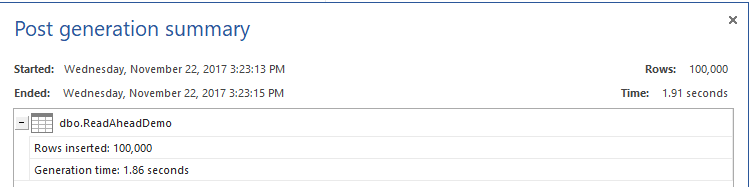
Once created, we will fill that table with 100K records, using ApexSQL Generate, a SQL test data generator tool:
创建完成后,我们将使用ApexSQL Generate (SQL测试数据生成器工具)在该表中填充10万条记录:
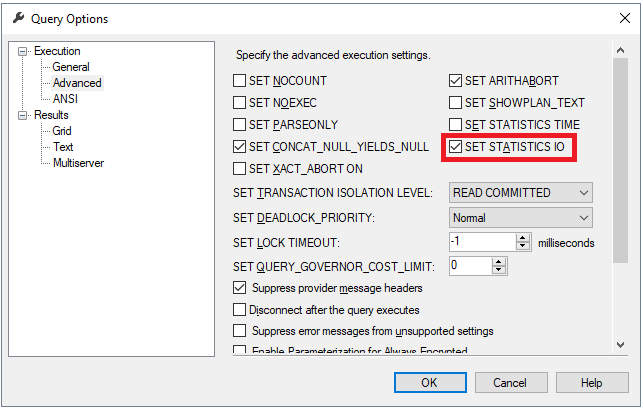
The table is ready now to start our testing scenario. To track the read-ahead, we will enable the IO statistics in the session that we will execute the query within, using the SET STATISTICS IO ON command, or by ticking the SET STATISTICS IO checkbox from the Query Options Advanced tab as shown below:
现在该表已准备就绪,可以开始我们的测试方案。 为了跟踪预读,我们将使用SET STATISTICS IO ON命令或在Query Options Advanced选项卡中选中SET STATISTICS IO复选框来启用将在其中执行查询的会话中的IO统计信息,如下所示:
We will also use the DBCC DROPCLEANBUFFERS command to flush all data pages in the buffer cache before running our SELECT query so that the buffer cache will be empty and the read-ahead reads can take place. This is used for testing purposes and not recommended to be used in a production environment. After enabling IO statistics, TIME statistics, the actual execution plan and cleaning the buffer cache, we will run the SELECT statement below to retrieve data from the previously created table, using the T-SQL query below:
在运行SELECT查询之前,我们还将使用DBCC DROPCLEANBUFFERS命令刷新缓冲区高速缓存中的所有数据页,以便缓冲区高速缓存为空,并且可以进行预读。 这用于测试目的,不建议在生产环境中使用。 启用IO统计信息,TIME统计信息,实际执行计划并清理缓冲区缓存后,我们将使用以下T-SQL查询运行以下SELECT语句从先前创建的表中检索数据:
DBCC DROPCLEANBUFFERS
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT [ID]
,[CustName]
,[CustAddress]
FROM [SQLShackDemo].[dbo].[ReadAheadDemo]
WHERE ID >157
We are not interested here in the retrieved data as we will check the IO and TIME statistics for performance comparison purposes only. From the messages tab of the query result, we will see that the number of read-ahead reads performed while retrieving data for this query is 708 pages. This means that 708 pages were brought into the buffer pool while executing that query. The query took 1444ms to be executed and consumed 141ms from the CPU time as shown in the statistics below:
我们在这里对检索到的数据不感兴趣,因为我们仅出于性能比较目的检查IO和TIME统计信息。 从查询结果的“消息”选项卡中,我们将看到在检索此查询的数据时执行的预读读取数为708页。 这意味着在执行该查询时,将708页引入了缓冲池。 查询耗时1444ms ,从CPU时间开始消耗了141ms ,如下统计所示:

From the execution plan generated after executing the previous query, right-click on the SELECT node properties, you will see that the PAGEIOLATCH_SH wait type occurred 4 times and stayed for 3ms, as shown in the snapshot below:
在执行上一个查询之后生成的执行计划中,右键单击SELECT节点属性,您将看到PAGEIOLATCH_SH等待类型发生了4次并停留了3ms ,如下面的快照所示:

If we execute the previous SELECT query again, enable IO and TIME statistics for that query and enable the actual execution plan, but this time we will not clear the buffer cache content as shown in the T-SQL query below:
如果我们再次执行上一个SELECT查询,请为该查询启用IO和TIME统计信息并启用实际的执行计划,但是这一次我们将不会清除缓冲区缓存内容,如下面的T-SQL查询所示:
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT [ID]
,[CustName]
,[CustAddress]
FROM [SQLShackDemo].[dbo].[ReadAheadDemo]
WHERE ID >157
You will derive from the TIME and IO statistics, shown in the Messages tab, that there is no need to perform read-ahead reads this time, as the requested pages are already in the buffer cache. The same result can be derived also from the TIME statistics, showing that it took the query only 889 ms to be executed completely, which is 60% of the time consumed in the previous query, and consumes 62 ms from the CPU time, which is 44% of the previous query CPU consumption. All of that due to the same reason; the data already exists in the buffer cache as a result of previous read-ahead reading operations. The IO and TIME statistics in our situation will be as follows:
您将从“消息”选项卡中显示的“时间”和“ IO”统计信息中得出结论,由于请求的页面已在缓冲区高速缓存中,因此这次无需执行预读。 同样的结果也可以从TIME统计信息中得出,表明查询仅花费889 ms即可完全执行,这是前一次查询消耗的时间的60%,并且从CPU时间消耗了62 ms 。先前查询CPU消耗的44%。 所有这些都是由于相同的原因; 由于先前的预读操作,该数据已存在于缓冲区高速缓存中。 我们的情况下的IO和TIME统计信息如下:

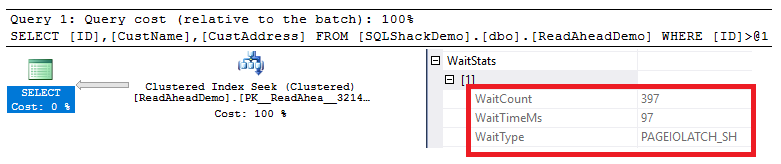
Checking the SELECT node properties in the execution plan generated by the executing the previous query, you will see that, when the read-ahead reads are not performed, the PAGEIOLATCH_SH wait type occurred 397 times and stayed for 97ms, as shown in the snapshot below:
检查由执行上一个查询生成的执行计划中的SELECT节点属性,您将看到,如果不执行预读,则PAGEIOLATCH_SH等待类型发生了397次,停留时间为97ms ,如下面的快照所示。 :
If we try to run the same previous query, providing a different value in the WHERE clause, and enabling both TIME and IO statistics for performance comparison purposes, as in the SELECT statement below:
如果我们尝试运行相同的先前查询,请在WHERE子句中提供不同的值,并同时启用TIME和IO统计信息以进行性能比较,如下面的SELECT语句所示:
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT [ID]
,[CustName]
,[CustAddress]
FROM [SQLShackDemo].[dbo].[ReadAheadDemo]
WHERE ID >774
You will see that the query will ask for new pages that are not available in the buffer cache. Because of this, read-ahead reads will be performed, to retrieve extra pages in addition to the requested pages and copy it to the buffer cache using complex algorithms to predicate the pages that the user may request in the coming queries, as shown in the Messages tab snapshot below:
您将看到查询将查询缓冲区高速缓存中不可用的新页面。 因此,将执行预读操作,以检索除请求的页面之外的其他页面,并使用复杂算法将其复制到缓冲区高速缓存中,以断言用户可能在即将到来的查询中请求的页面,如下面的消息选项卡快照:

The read-ahead mechanism is enabled by default. Which means that, whenever a read-ahead read is required, it will take place. There is a Trace Flag 652 that can be used to disable the default read-ahead mechanism. Recall the first SELECT query in our demo in which we clear the buffer cache before executing the query, that forced the read-ahead to take place. If we turn on the Trace Flag 652 before executing the same query, as shown in the T-SQL script below:
默认情况下,预读机制处于启用状态。 这意味着,每当需要预读时,都会进行预读。 有一个跟踪标志652可用于禁用默认的预读机制。 回想一下我们的演示中的第一个SELECT查询,在该查询中我们在执行查询之前清除了缓冲区缓存,这迫使进行预读。 如果我们在执行同一查询之前打开跟踪标志652,如下面的T-SQL脚本所示:
DBCC TRACEON(652)
DBCC DROPCLEANBUFFERS
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT [ID]
,[CustName]
,[CustAddress]
FROM [SQLShackDemo].[dbo].[ReadAheadDemo]
WHERE ID >157
Checking the IO statistics of the previous query, you will find that, no read-ahead read is performed in the query that has 708 read-ahead reads previously, due to turning on the TF 652 before executing it, that disabled the read-ahead mechanism, as shown in the statistics below:
检查上一个查询的IO统计信息,您会发现,由于在执行TF 652之前先打开了TF 652,因此先前在其中执行708个预读的查询中未执行预读。机制,如下统计数据所示:

I hope this all made sense. If anything was unclear, please feel free to comment below!
我希望这一切都是有道理的。 如果不清楚,请在下面发表评论!
翻译自: https://www.sqlshack.com/sql-server-read-ahead-mechanism-concept-performance-gains/
sql server 性能