随机抽样

import numpy
import pandas
data=pandas.read_csv('/Users/cuiwenhao/Data_xxx/4.9/data.csv')
#设置随机种子
numpy.random.seed(seed=2)
a=data.sample(n=10)
print(a)
id class score
83 84 3 52
30 31 1 46
56 57 1 96
24 25 1 77
16 17 2 115
23 24 1 84
2 3 3 46
27 28 1 73
28 29 2 58
13 14 2 69
#按照百分比抽样
b=data.sample(frac=0.02)
print(b)
id class score
23 24 1 84
30 31 1 46
#是否可放回抽样,
#replace=True,可放回,
#replace=False,不可放回
c=data.sample(n=10, replace=True)
#典型抽样,分层抽样
gbr = data.groupby("class")#按照class分组
gbr.groups#分成了3个班
{1: Int64Index([ 1, 4, 9, 12, 19, 23, 24, 25, 27, 30, 32, 36, 37, 39, 40, 43, 44,
46, 47, 49, 53, 56, 60, 70, 76, 78, 79, 92, 93, 98],
dtype='int64'), 2: Int64Index([ 3, 8, 11, 13, 14, 15, 16, 18, 20, 21, 22, 28, 29, 35, 38, 45, 51,
54, 57, 62, 63, 68, 71, 72, 74, 75, 80, 81, 84, 85, 86, 87, 89, 94,
96, 97, 99],
dtype='int64'), 3: Int64Index([ 0, 2, 5, 6, 7, 10, 17, 26, 31, 33, 34, 41, 42, 48, 50, 52, 55,
58, 59, 61, 64, 65, 66, 67, 69, 73, 77, 82, 83, 88, 90, 91, 95],
dtype='int64')}
typicalNDict = {
1: 2, #1班抽2个
2: 4, #2班抽4个
3: 6 }
def typicalSampling(group, typicalNDict):
name = group.name
n = typicalNDict[name]
return group.sample(n=n)
result = data.groupby(
'class', group_keys=False
).apply(typicalSampling, typicalNDict)
print(result)
id class score
79 80 1 83
53 54 1 95
63 64 2 71
84 85 2 85
14 15 2 50
71 72 2 107
58 59 3 90
91 92 3 59
26 27 3 64
69 70 3 96
7 8 3 48
33 34 3 67
def typicalSampling(group, typicalFracDict):
name = group.name
frac = typicalFracDict[name]
return group.sample(frac=frac)
result1 = data.groupby(
'class', group_keys=False
).apply(typicalSampling, typicalFracDict)
print(result1)
记录合并
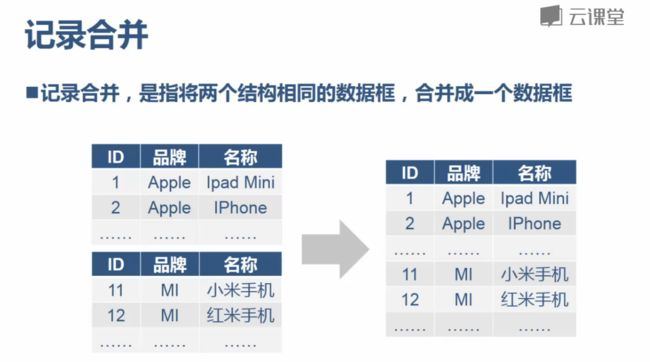
- 记录合并函数:concat([dataFrame1,dataFrame2,…])
- 参数说明
- dataFrame1 数据框
- dataFrame2 数据框
- 返回值:DataFrame
- 参数说明
import pandas
from pandas import read_csv
data1 = read_csv( '/Users/cuiwenhao/Data_xxx/4.10/data1.csv', sep="|")
data2 = read_csv(
'/Users/cuiwenhao/Data_xxx/4.10/data2.csv', sep="|"
)
data3 = read_csv(
'/Users/cuiwenhao/Data_xxx/4.10/data3.csv', sep="|"
)
data = pandas.concat([data1, data2, data3])
data11 = pandas.concat([
data1[[0, 1]],
data2[[1, 2]],
data3[[0, 2]]
])
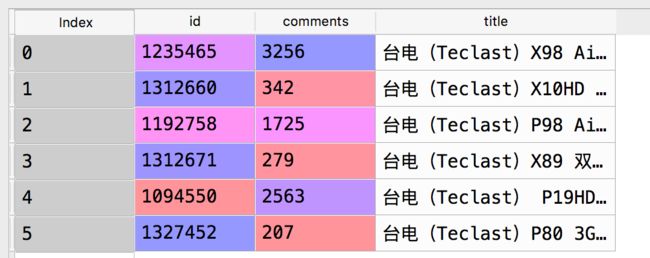
data2:
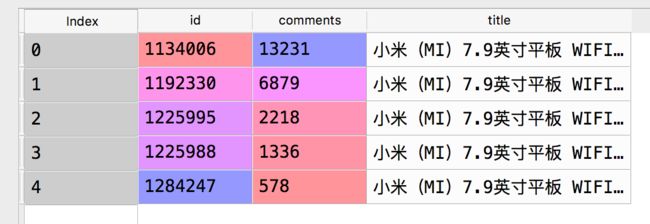
data3:
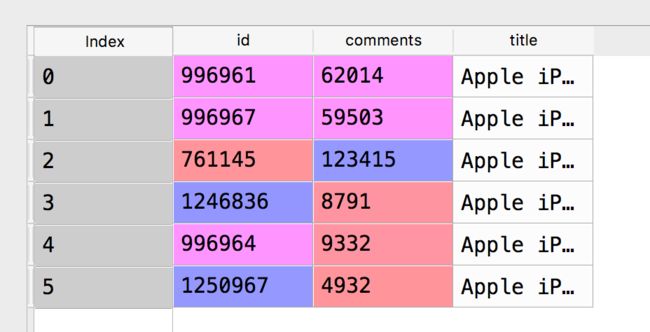
合并后的data:

字段合并
- 字段合并方法:x=x1+x2+…
from pandas import read_csv
df = read_csv(
'/Users/cuiwenhao/Data_xxx/4.11/data.csv',
sep=" ", names=['band', 'area', 'num'])
print(df)
band area num
0 189 2225 4812
1 135 2225 5003
2 134 2225 9938
3 188 2225 6753
4 189 2225 3721
5 134 2225 9313
6 138 2225 4373
7 133 2225 2452
8 189 2225 7681
df = df.astype(str)
tel = df['band'] + df['area'] + df['num']
df['tel'] = tel
print(df)
band area num tel
0 189 2225 4812 18922254812
1 135 2225 5003 13522255003
2 134 2225 9938 13422259938
3 188 2225 6753 18822256753
4 189 2225 3721 18922253721
5 134 2225 9313 13422259313
6 138 2225 4373 13822254373
7 133 2225 2452 13322252452
8 189 2225 7681 18922257681
字段匹配(类似vlookup)

- 字段匹配参数:merage(x,y,left_on,right_on)
- 参数说明
- x :第一个数据框
- y :第二个数据框
- left_on :第一个数据框用于匹配的列
- right_on : 第二个数据框用于匹配的列
- 参数说明
import pandas
items = pandas.read_csv(
'/Users/cuiwenhao/Data_xxx/4.12/data1.csv',
sep='|',
names=['id', 'comments', 'title'])
prices = pandas.read_csv(
'/Users/cuiwenhao/Data_xxx/4.12/data2.csv',
sep='|',
names=['id', 'oldPrice', 'nowPrice'] )
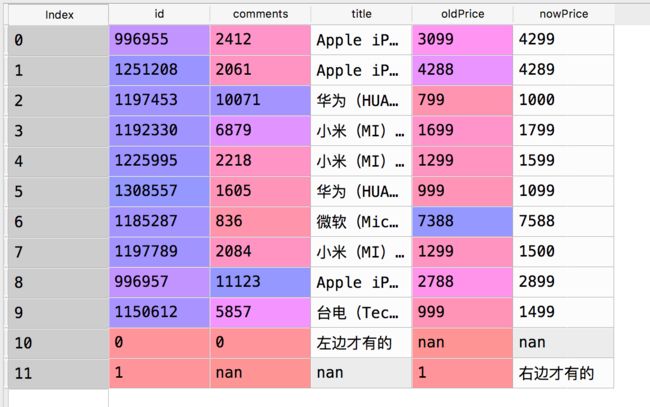
items:
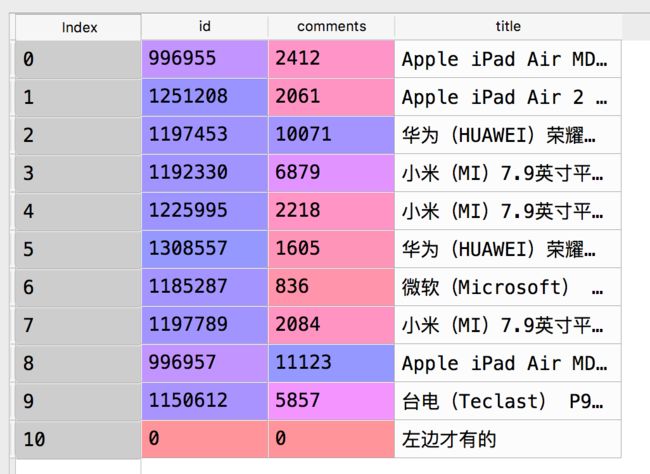
price:
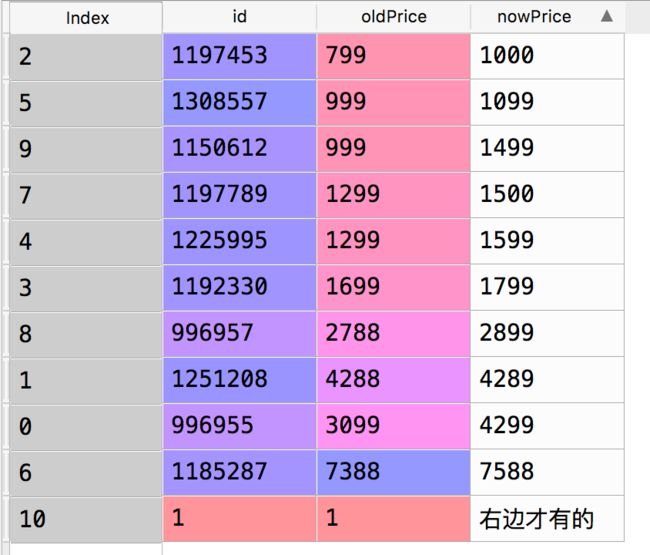
#默认只是保留连接上的部分
itemPrices = pandas.merge(
items,
prices,
left_on='id',
right_on='id')
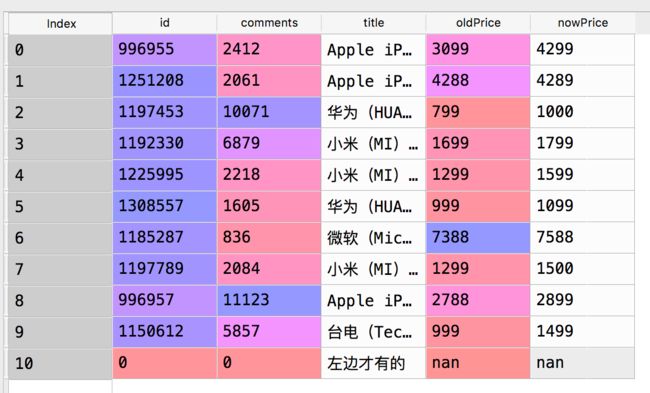
#即使连接不上,也保留右边没连上的部分
itemPrices = pandas.merge(
items,
prices,
left_on='id',
right_on='id',
how='right')
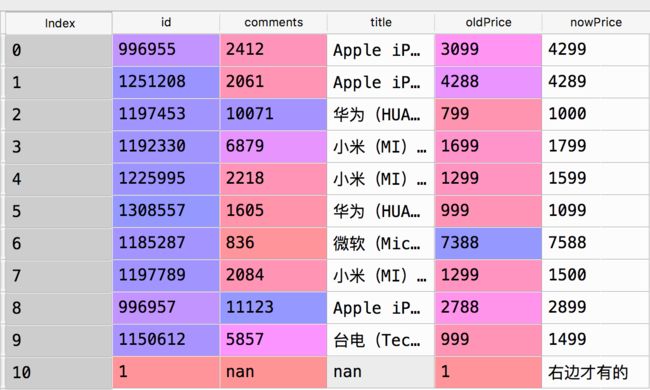
#即使连接不上,也保留所有没连上的部分
itemPrices = pandas.merge(
items,
prices,
left_on='id',
right_on='id',
how='outer')
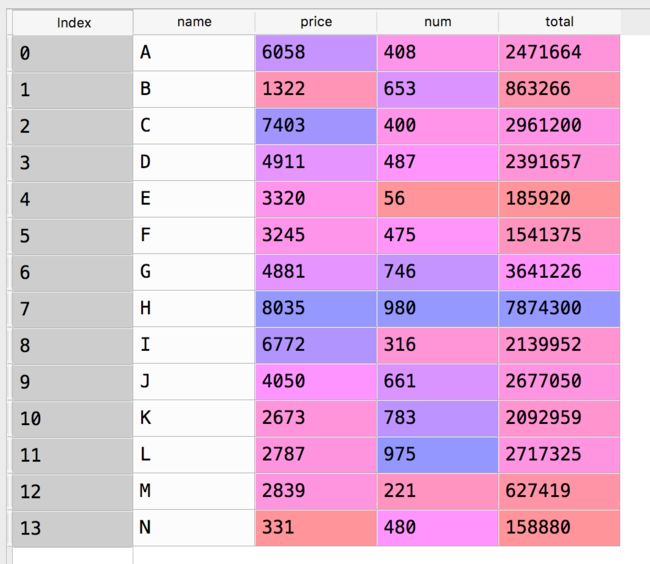
简单计算
import pandas
data = pandas.read_csv(
'/Users/cuiwenhao/Data_xxx/4.13/data.csv',
sep="|" )
data['total'] = data.price*data.num
数据标准化

原数据:
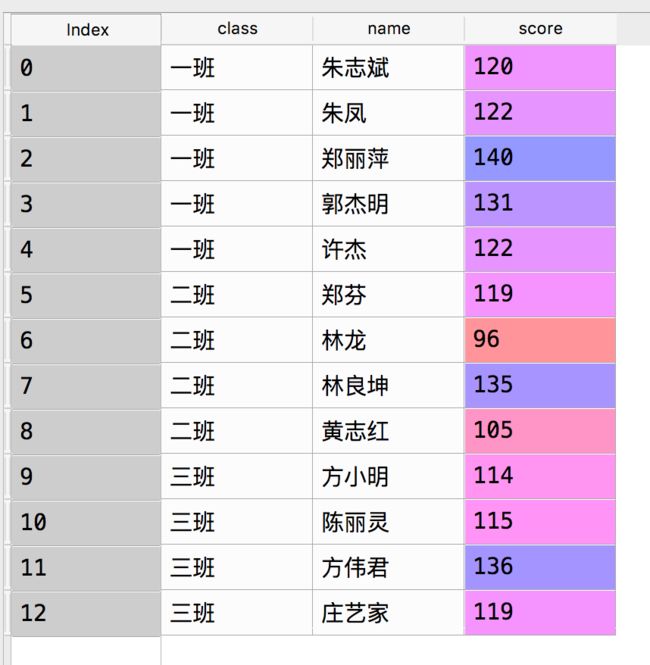
data['scale'] = round(
(
data.score-data.score.min()
)/(
data.score.max()-data.score.min()
)
, 2) # 保留两位小数
class name score scale
0 一班 朱志斌 120 0.55
1 一班 朱凤 122 0.59
2 一班 郑丽萍 140 1.00
3 一班 郭杰明 131 0.80
4 一班 许杰 122 0.59
5 二班 郑芬 119 0.52
6 二班 林龙 96 0.00
7 二班 林良坤 135 0.89
8 二班 黄志红 105 0.20
9 三班 方小明 114 0.41
10 三班 陈丽灵 115 0.43
11 三班 方伟君 136 0.91
12 三班 庄艺家 119 0.52
数据分组
- cut函数:cut(series,bins,right=True,labels=NUll)
- series 需要分组的数据
- bins:分组的划分数组
- right:分组的时候,右边是否闭合
- labels: 分组的自定义标签,可以不自定义
import pandas
data = pandas.read_csv( '/Users/cuiwenhao/Data_xxx/4.15/data.csv', sep='|')
tel cost
0 166424556600 2.0
1 166424557199 5.0
2 166424561768 75.3
3 166424569696 20.0
4 166424569924 97.3
5 166424579238 3.0
6 166424581334 100.0
7 166424589730 77.0
8 166424591167 5.5
9 166424598020 50.0
10 166424598259 28.6
11 166424606270 10.8
12 166424632819 76.7
13 166424635250 84.6
14 166424641824 10.0
#设置分组 区间最小值-1,最大值+1(能全都包含进去)
bins = [ min(data.cost)-1, 20, 40, 60, 80, 100, max(data.cost)+1]
data['cut'] = pandas.cut(
data.cost,
bins)
tel cost cut
0 166424556600 2.0 (1.0, 20.0]
1 166424557199 5.0 (1.0, 20.0]
2 166424561768 75.3 (60.0, 80.0]
3 166424569696 20.0 (1.0, 20.0]
4 166424569924 97.3 (80.0, 100.0]
5 166424579238 3.0 (1.0, 20.0]
6 166424581334 100.0 (80.0, 100.0]
7 166424589730 77.0 (60.0, 80.0]
8 166424591167 5.5 (1.0, 20.0]
9 166424598020 50.0 (40.0, 60.0]
10 166424598259 28.6 (20.0, 40.0]
11 166424606270 10.8 (1.0, 20.0]
12 166424632819 76.7 (60.0, 80.0]
13 166424635250 84.6 (80.0, 100.0]
14 166424641824 10.0 (1.0, 20.0]
#右边闭合
data['cut'] = pandas.cut(
data.cost,
bins,
right=False)
tel cost cut
0 166424556600 2.0 [1.0, 20.0)
1 166424557199 5.0 [1.0, 20.0)
2 166424561768 75.3 [60.0, 80.0)
3 166424569696 20.0 [20.0, 40.0)
4 166424569924 97.3 [80.0, 100.0)
5 166424579238 3.0 [1.0, 20.0)
6 166424581334 100.0 [100.0, 101.0)
7 166424589730 77.0 [60.0, 80.0)
8 166424591167 5.5 [1.0, 20.0)
9 166424598020 50.0 [40.0, 60.0)
10 166424598259 28.6 [20.0, 40.0)
11 166424606270 10.8 [1.0, 20.0)
12 166424632819 76.7 [60.0, 80.0)
13 166424635250 84.6 [80.0, 100.0)
14 166424641824 10.0 [1.0, 20.0)
#自定义分组标签
labels = [
'20以下', '20到40', '40到60',
'60到80', '80到100', '100以上'
]
data['cut'] = pandas.cut(
data.cost, bins,
right=False, labels=labels
)
tel cost cut
0 166424556600 2.0 20以下
1 166424557199 5.0 20以下
2 166424561768 75.3 60到80
3 166424569696 20.0 20到40
4 166424569924 97.3 80到100
5 166424579238 3.0 20以下
6 166424581334 100.0 100以上
7 166424589730 77.0 60到80
8 166424591167 5.5 20以下
9 166424598020 50.0 40到60
10 166424598259 28.6 20到40
11 166424606270 10.8 20以下
12 166424632819 76.7 60到80
13 166424635250 84.6 80到100
14 166424641824 10.0 20以下
时间处理
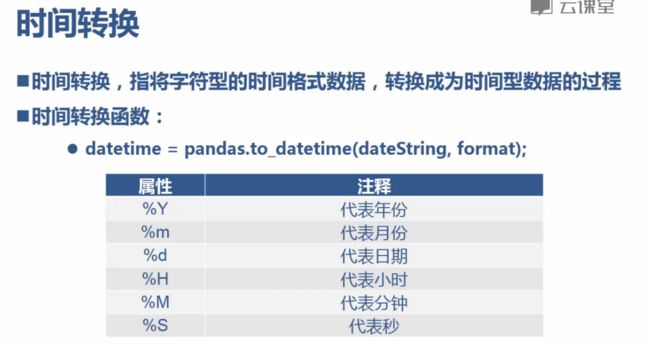
- 时间格式化:是指将时间型数据,按照指定格式,转为字符型数据
-
时间格式化函数:dateTimeFormat=datetime.dt.strtime(format)
import pandas
data = pandas.read_csv(
'/Users/cuiwenhao/Data_xxx/4.16/data.csv',
encoding='utf8')
#转换为时间型格式
data['时间'] = pandas.to_datetime(
data.注册时间,
format='%Y/%m/%d')
#时间形式转换为字符型数据
data['格式化时间'] = data.时间.dt.strftime('%Y-%m-%d')
data['时间.年'] = data['时间'].dt.year
data['时间.月'] = data['时间'].dt.month
data['时间.周'] = data['时间'].dt.weekday
data['时间.日'] = data['时间'].dt.day
data['时间.时'] = data['时间'].dt.hour
data['时间.分'] = data['时间'].dt.minute
data['时间.秒'] = data['时间'].dt.second
虚拟变量

- 离散特征的取值之间有大小意义的处理函数
- panads.Series.map(dict)
- dict 映射字典
# -*- coding: utf-8 -*-
import pandas
data = pandas.read_csv(
'/Users/cuiwenhao/Data_xxx/4.18/data.csv',
encoding='utf8'
)
data['Education Level'].drop_duplicates()#去重
print(data)
0 Doctorate
3 Bachelor's Degree
6 Master's Degree
20 Associate's Degree
35 Some College
102 Post-Doc
111 Trade School
157 High School
187 Grade School
"""
博士后 Post-Doc
博士 Doctorate
硕士 Master's Degree
学士 Bachelor's Degree
副学士 Associate's Degree
专业院校 Some College
职业学校 Trade School
高中 High School
小学 Grade School
"""
educationLevelDict = {
'Post-Doc': 9,
'Doctorate': 8,
'Master\'s Degree': 7,
'Bachelor\'s Degree': 6,
'Associate\'s Degree': 5,
'Some College': 4,
'Trade School': 3,
'High School': 2,
'Grade School': 1
}
#有大小意义的映射字典
data['Education Level Map'] = data[
'Education Level'
].map(
educationLevelDict
)
Age Education Level Gender Education Level Map
0 33.0 Doctorate Male 8
1 47.0 Doctorate Male 8
2 NaN Doctorate Male 8
3 35.0 Bachelor's Degree Male 6
4 32.0 Bachelor's Degree Male 6
5 32.0 Bachelor's Degree Male 6
6 32.0 Master's Degree Male 7
7 32.0 Bachelor's Degree Male 6
8 33.0 Master's Degree Male 7
9 44.0 Master's Degree Male 7
10 39.0 Master's Degree Male 7
- 没有大小意义用
-
panads.get_dummies()
-
data['Gender'].drop_duplicates()#去重
0 Male
13 Female
39 NaN
#没有大小意义的用pandas.get_dummies
dummies = pandas.get_dummies(
data,
columns=['Gender'],
prefix=['Gender'],
prefix_sep="_",
dummy_na=False,
drop_first=False
)
Age Education Level ... Gender_Female Gender_Male
0 33.0 Doctorate ... 0 1
1 47.0 Doctorate ... 0 1
2 NaN Doctorate ... 0 1
3 35.0 Bachelor's Degree ... 0 1
4 32.0 Bachelor's Degree ... 0 1
5 32.0 Bachelor's Degree ... 0 1
6 32.0 Master's Degree ... 0 1
7 32.0 Bachelor's Degree ... 0 1
8 33.0 Master's Degree ... 0 1
9 44.0 Master's Degree ... 0 1
10 39.0 Master's Degree ... 0 1
11 29.0 Master's Degree ... 0 1
12 41.0 Doctorate ... 0 1
13 44.0 Doctorate ... 1 0
14 59.0 Master's Degree ... 0 1
15 45.0 Bachelor's Degree ... 0 1
dummies['Gender'] = data['Gender']