【Spark内核源码】SparkContext中的组件和初始化
目录
SparkContext概述
SparkContext组件概述
SparkContext初始化过程
第一步:确保当前线程中没有SparkContext在运行
第二步:版本反馈
第三步:真正的初始化
第四步:确认启动成功
SparkContext概述
在【Spark内核源码】Word Count程序的简单分析 当中使用Spark Shell编写了简单的Word Count程序,在进入Spark Shell的时候,Spark Shell为我们自动创建了SparkContext sc。

Spark应用程序的第一步就是创建并初始化SparkContext,SparkContext的初始化过程包含了内部组件的创建和准备,主要涉及网络通信、分布式、消息、存储、计算、调度、缓存、度量、清理、文件服务和UI等方面。它是Spark主要功能的入口点,链接Spark集群,创建RDD、累加器和广播变量,一个线程只能运行一个SparkContext。SparkContext在应用程序中将外部数据转换成RDD,因此建立了第一个RDD,也就是说SparkContext建立了RDD血缘关系的根,是DAG的根源。
SparkContext组件概述
SparkContext的组件如下图所示:
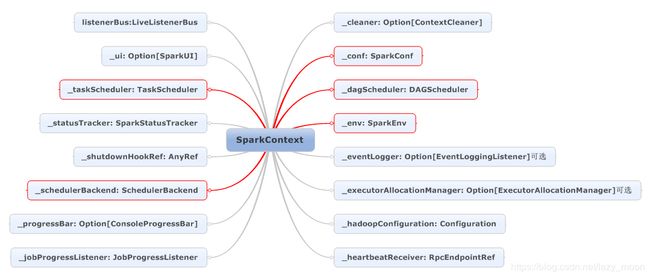
各组件的说明如下:
listenerBus:Spark事件总线,接收各个使用方的事件,以异步的方式对事件进行匹配和处理。
_ui:Spark用户界面,间接依赖于计算引擎、调度系统、存储体系、作业、阶段、存储、执行器等组件的监控数据,以SparkListenerEnvent的形式投递给LiveListener,SparkUI从SparkListener中读取数据。
_taskScheduler:任务调度器,调度系统中最重要的组件之一,按照调度算法对集群管理器已经分配给应用程序的资源进行二次调度后分配任务,TaskScheduler调度的task是DAGScheduler创建的,因此DAGScheduler是TaskScheduler的前置调度器。
_statusTracker:状态跟踪器,提供对作业、stage等的监控信息。
_shutdownHookRef:任务退出时执行清理任务。
_schedulerBackend:用于对接不同的资源管理系统。
_progressBar:进度条,利用SparkStatusTracker的API,在控制台展示Stage的进度。
_jobProgressListener:作业进度监听器,会注册到LiveListenerBus中作为时间监听器使用。
_cleaner:上下文清理器,用异步方式清理超出应用程序范围的RDD、ShuffleDependency和BroadCast。
_conf:Spark配置,以k-v的形式保存着Spark应用程序的配置信息。
_dagScheduler:DAG调度器,调度系统中最重要的组件之一,负责创建job,将DAG的RDD划分为不同的stage,提交stage。
_env:Spark运行时环境。
_eventLogger:将事件日志的监听器,Spark可选组件,spark.eventLog.enabled=true时启动。
_executorAllocationManager:Executor动态分配管理器,根据工作负载动态调整Executor的数量,在spark.dynamicAllocation.enabled=true的前提下,和非local模式下或者spark.dynamicAllocation.testing=true时启动。
_hadoopConfiguration:hadoop的配置信息,如果使用的是系统SPARK_YARN_MODE=true或者环境变量SPARK_YARN_MODE=true时,启用yarn配置,否则启用hadoop配置。
_heartbeatReceiver:心跳接收器,Executor都会向heartbeatReceiver发送心跳信息,heartbeatReceiver接收到信息后,更新executor最后的可见时间,然后传递给taskScheduler做进一步处理。
SparkContext初始化过程
在将SparkContext初始化过程之前,需要先了解SparkContext伴生对象中的两个变量,它们分别是activeContext: AtomicReference[SparkContext]和contextBeingConstructed: Option[SparkContext]。
activeContext: AtomicReference[SparkContext]记录了当前SparkContext是否处于活跃状态,当活跃的时候activeContext的value就是当前SparkContext,否则value就是null。
contextBeingConstructed: Option[SparkContext]则是SparkContext正在启动时的一个标识,SparkContext初始化时有很多组件需要进行初始化设置,需要消耗一些时间,同时又要保证一个线程中只运行一个SparkContext,通过设置SparkContext启动时的表示,来保证一个线程中只运行一个SparkContext,当SparkContext正在启动时,contextBeingConstructed=Some(sc),否则contextBeingConstructed=None。
下面来看看SparkContext启动的具体步骤,
第一步:确保当前线程中没有SparkContext在运行

markPartiallyConstructed方法中当assertNoOtherContextIsRunning方法执行通过之后,设置contextBeingConstructed = Some(sc),表示当前线程中正在建立SparkContext,如果这个线程中再建立SparkContext,就要出问题了,assertNoOtherContextIsRunning就是做这个检验用的。

assertNoOtherContextIsRunning方法中确保一个线程中吃运行一个SparkContext,如果检测到右其他的SparkContext在运行,就抛出异常。如果其他线程在构建SparkContext,就提出一个警告,这个警告是为了当SparkContext构建过程中出现错误,可以很清楚的区分开是哪个线程的SparkContext出的错误。

第二步:版本反馈
输出Spark版本,检验java和scala版本,spark 2.1.0需要使用java7和scala2.10会有警告

第三步:真正的初始化
初始化过程分为十几个步骤:
/**
* SparkConext初始化第三步:
* 通过克隆的方式获取sparkconf,在sparkContext初始化的过程中做了以下几件事:
* 1、会对conf中的配置信息进行校验(部署模式、appName、yarn模式校验等等)
* 2、处理或设置参数:
* 2.1、driver的IP、端口号和ID
* 2.2、处理jar路径和文件路径
* 2.3、事件日志路径、是否压缩事件
* 2.4、设置是否启动yarn配置的属性
* 3、初始化并启动一些组件(以下按照创建顺序):
* 3.1、创建任务进度监听器,并增加到事件总线中
* 3.2、创建spark运行环境
* 3.3、创建状态跟踪器
* 3.4、创建进度条
* 3.5、创建Spark UI
* 3.6、创建hadoop的配置信息(SPARK_YARN_MODE=true时,采用yarn配置信息)
* 3.7、加载jar和file
* 3.8、配置Executor运行环境
* 3.9、创建心跳接收器,在创建taskScheduler之前创建,因为Executor需要再构造函数中检索heartbeatReceiver
* 3.10、创建schedulerBackend和taskScheduler
* 3.11、创建dagScheduler,向dagScheduler引入了taskScheduler
* 3.12、根据taskScheduler生成的_applicationId启动度量系统,并且将监控信息发送给SparkUI进行展示
* 3.13、创建事件日志监听器,并增加到总线中
* 3.14、创建并启动Executor动态分配管理器
* 3.15、创建并启动上下文清理器
* 3.16、设置并启动事件总线
* 3.17、发布环境更新事件
* 3.18、发布应用程序启动事件
* 3.19、taskScheduler需要等待SchedulerBackend
* 3.20、将dagScheduler、BlockManagerSource和ExecutorAllocationManager注册到度量系统中
* */
1、通过克隆的方式获取sparkconf,会对conf中的配置信息进行校验(部署模式、appName、yarn模式校验等等)
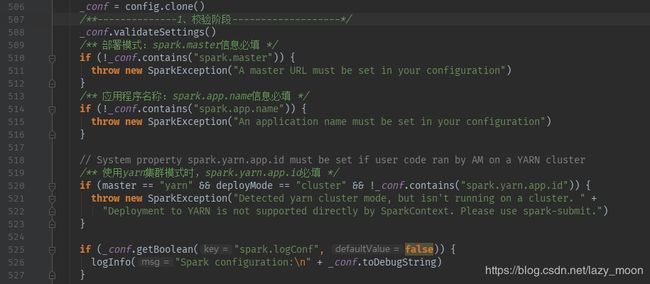
2、处理或设置参数:
2.1、driver的IP、端口号和ID

2.2、处理jar路径和文件路径
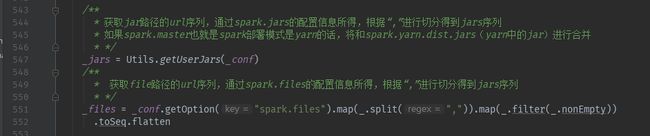
2.3、事件日志路径、是否压缩事件

2.4、设置是否启动yarn配置的属性
![]()
3、初始化并启动一些组件(以下按照创建顺序):
3.1、创建任务进度监听器,并增加到事件总线中

3.2、创建spark运行环境

3.3、创建状态跟踪器

3.4、创建进度条

3.5、创建Spark UI

3.6、创建hadoop的配置信息(SPARK_YARN_MODE=true时,采用yarn配置信息)

3.7、加载jar和file

3.8、配置Executor运行环境

3.9、创建心跳接收器,在创建taskScheduler之前创建,因为Executor需要再构造函数中检索heartbeatReceiver

3.10、创建schedulerBackend和taskScheduler

3.11、创建dagScheduler,向dagScheduler引入了taskScheduler

3.12、启动taskScheduler,并根据taskScheduler生成的_applicationId启动度量系统,并且将监控信息发送给SparkUI进行展示

3.13、创建事件日志监听器,并增加到总线中

3.14、创建并启动Executor动态分配管理器

3.15、创建并启动上下文清理器

3.16、设置并启动事件总线

3.17、发布环境更新事件

3.18、发布应用程序启动事件

3.19、taskScheduler需要等待SchedulerBackend

3.20、将dagScheduler、BlockManagerSource和ExecutorAllocationManager注册到度量系统中

第四步:确认启动成功
设置activeContext的状态

这一步的处理逻辑和第一步类似,都是先调用assertNoOtherContextIsRunning方法,确保当前线程中没有其他SparkContext在创建,然后将contextBeingConstructed设置为None和activeContext的value设置为当前SparkContext

这里吐槽一句:老外写的代码真的很奇葩,初始化的代码真的是翻山越岭才构造完,第一步在90多行,第二步在200多行,第三步在500多行,第四步在2400多行,这每一步中间穿插着很多的成员变量、方法,就不能写在一块吗?