Standalone模式的Spark集群搭建
中秋节快乐! 本文是搭建推荐系统的第一课:spark集群搭建。对于spark集群,我对它也是知之甚少。但是它和推荐系统的大规模数据计算密切相关,在本次的推荐系统痛的搭建中也使用到了spark集群。所以,搭建spark集群是我的第一步工作。因为后面的诸如HDFS,YARN,HIVE等都是基于spark集群的。由于Linux服务器数量的问题,本次搭建的sparck集群为Spark自带的集群模式(Standalone)。Spark/Spark-ha集群搭建,也就是带zookeeper集群监控的搭建,在此暂且不提。
Spark自带的集群模式
对于Spark自带的集群模式,Spark要先启动一个老大(Master),然后老大Master和各个小弟(Worker)进行通信,其中真正干活的是Worker下的Executor。关于提交任务的,需要有一个客户端,这个客户端叫做Driver.这个Driver首先和Master建立通信,然后Master负责资源分配,然后让Worker启动Executor,然后Executor和Driver进行通信。效果图如下:
1. Standalone模式:

2. Spark/Spark-ha集群模式:
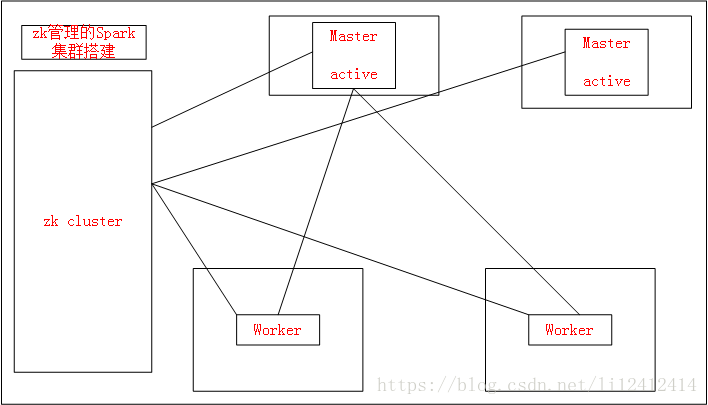
Standalone模式的Spark集群搭建
目录
准备工作
下载安装spark
配置spark
启动spark集群
停止spark集群
效果展示
准备工作
准备好三台linux服务器。在这里我准备的三台Linux服务器ip为:172.17.32.105;172.16.185.233;172.17.49.99;
在三台linux服务器上安装好jdk环境
下载安装spark
下载地址为:http://spark.apache.org/downloads.html
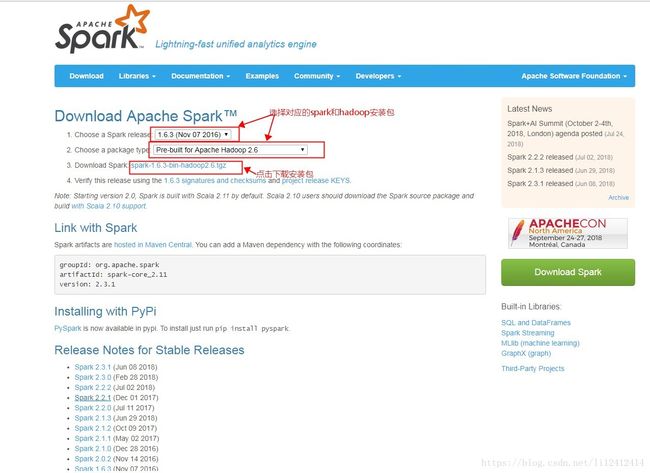
将安装包存放到三台服务器的指定目录下,并且解压。比如我存放的目录是:/home/lg/software下,执行如下的命令进行解压
tar -zxvf spark-1.6.3-bin-hadoop2.6.tgz -C /home/lg/software配置spark
spark安装完毕以后,我们需要进行相关的配置。在三台服务器上都执行如下的配置。当然你可以在一台服务器上写好了配置以后,再使用scp命令copy到其它的俩台服务器上 1. 进入到spark安装目录
cd /home/lg/software/spark-1.6.3-bin-hadoop2.62. 进入conf目录并重命名并修改spark-env.sh.template文件为spark-env.sh
cd conf
mv spark-env.sh.template spark-env.sh
vim spark-env.sh3. 配置spark-env.sh,在spark-env.sh文件中加入如下的内容
export JAVA_HOME=/data/java/jdk1.7.0_15
export SPARK_MASTER_IP=hadoop1
export SPARK_MASTER_PORT=70774. 重命名并修改slaves.template文件
mv slaves.template slaves
vi slaves5. 在slaves文件中加入如下的内容
hadoop2
hadoop36. 配置环境变量
vim /etc/profile7. 在/etc/profile中加入如下的内容
#set spark env
export SPARK_HOME=/home/lg/software/spark-1.6.3-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin8.保存退出以后,使用如下的命令使配置生效:
source /etc/profile9. 配置/etc/hosts文件,增加如下的内容
172.17.32.105 hadoop1
172.16.185.233 hadoop2
172.17.49.99 hadoop3启动spark集群
一般来说,Standalone模式的Spark集群的启动有以下的几种方式:
1. master,slave一起启动:
/home/lg/software/spark-1.6.3-bin-hadoop2.6/sbin/start-all.sh2. master,slave节点分开启动 首先在172.17.32.105上启动master:
cd /home/lg/software/spark-1.6.3-bin-hadoop2.6/sbin
./sbin/start-master.sh -h 172.17.32.105:7077其次在172.17.49.99,172.16.185.233上启动slave:
cd /home/lg/software/spark-1.6.3-bin-hadoop2.6/sbin
./start-slave.sh spark:/172.17.32.105:7077我想在此说明的一点是:我使用第一种方式进行进行启动的时候,出现的俩个错误是:第一,当连接俩个slave机器的时候,提示你要输入密码。所以,在配置spark集群的时候,我给的一个建议是三台机器最好都配置了免密码登录;第二:slave 俩台机器总是提示连接不上master,在此我猜测的原因是无法根据hostname匹配到对应的ip。所以,在此,如果采用第一种方式进行配置的时候出现了问题,我建议你采用第一种方式来进行配置。
停止spark集群
一般来说,Standalone模式的Spark集群的停止有以下的几种方式:
1. master,slave一起停止:
/home/lg/software/spark-1.6.3-bin-hadoop2.6/sbin/stop-all.sh2. master,slave节点分开停止
首先在172.17.49.99,172.16.185.233上停止slave:
cd /home/lg/software/spark-1.6.3-bin-hadoop2.6/sbin
./stop-slave.sh spark:/172.17.32.105:7077其次在172.17.32.105上停止master:
cd /home/lg/software/spark-1.6.3-bin-hadoop2.6/sbin
./sbin/stop-master.sh -h 172.17.32.105:7077
效果展示
集群启动以后,我们在浏览器输入http://masterIP:8080/,masterIP需要使用实际的master的ip来进行替代。那么可以看到如下的界面:

感谢&总结
本文主要分享了如何搭建spark集群。"日拱一卒无有尽 功不唐捐终入海",每天进步一点点,量变引起质变,最后,我们还是可以取得长足的进步的,共勉。
往期相关文章
-
初始推荐系统
-
推荐系统数据来源
-
推荐系统冷启动