交互特征与多项式特征
一、多项式特征
想要丰富特征,特别是对于线性模型而言,除了分箱外,另一种方法是添加原始数据的交互特征和多项式特征。对于给定的特征x,我们可以考虑x,x**2、x**3等,可用preprocessing模块的PolynomialFeatures实现。同样采用wave数据集进行分析。
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.preprocessing import PolynomialFeatures
#导入数据
X, y = mglearn.datasets.make_wave(n_samples=100)
line = np.linspace(-3, 3, 1000, endpoint=False).reshape(-1, 1)
#包含到x**10的多项式
#默认的include_bias=True添加恒等于1的常数特征
poly = PolynomialFeatures(degree=10, include_bias=False)
poly.fit(X)
X_poly = poly.transform(X)

将多项式特征与回归模型一起使用,可以得到经典的多项式回归。
reg = LinearRegression().fit(X_poly, y)
line_poly = poly.transform(line)
plt.plot(line, reg.predict(line_poly), label='polynomial linear regression')
plt.plot(X[:, 0], y, 'o', c='k')
plt.ylabel("Regression output")
plt.xlabel("Input feature")
plt.legend(loc="best")
作为对比,下面是在原始数据上学到的核SVM模型,没有做任何变换。
from sklearn.svm import SVR
for gamma in [1, 10]:
svr = SVR(gamma=gamma).fit(X, y)
plt.plot(line, svr.predict(line), label='SVR gamma={}'.format(gamma))
plt.plot(X[:, 0], y, 'o', c='k')
plt.ylabel("Regression output")
plt.xlabel("Input feature")
plt.legend(loc="best")
使用更复杂的模型(即核SVM),我们能够学到一个与多项式回归复杂度类似的预测结果,且不需要进行显式地特征变换。
二、交互特征
这部分采用波士顿房价数据集。
1.加载数据,利用MinMaxScaler将其放缩到0-1之间。
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
boston = load_boston()
X_train, X_test, y_train, y_test = train_test_split(
boston.data, boston.target, random_state=0)
# rescale data
scaler = MinMaxScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)2.提取多项式特征和交互特征
poly = PolynomialFeatures(degree=2).fit(X_train_scaled)
X_train_poly = poly.transform(X_train_scaled)
X_test_poly = poly.transform(X_test_scaled)
print("X_train.shape: {}".format(X_train.shape))
print("X_train_poly.shape: {}".format(X_train_poly.shape)) 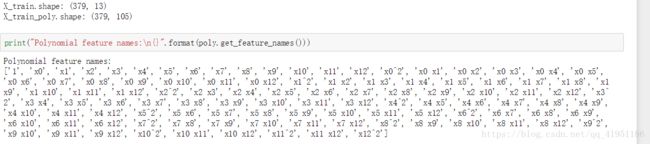
原始数据有13个特征,现在被扩展到105个交互特征(原始特征,两个不同特征地积,原始特征地平方,以及常数特征‘1’)。
3.对Ridge在有交互特征地数据集和没有交互特征地数据上地性能进行对比
from sklearn.linear_model import Ridge
ridge = Ridge().fit(X_train_scaled, y_train)
print("Score without interactions: {:.3f}".format(
ridge.score(X_test_scaled, y_test)))
ridge = Ridge().fit(X_train_poly, y_train)
print("Score with interactions: {:.3f}".format(
ridge.score(X_test_poly, y_test)))
显然,在使用Ridge时,交互特征和多项式特征对性能有很大地提升。但如果使用更复杂地模型(比如随机森林),情况会稍有不同。
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor(n_estimators=100).fit(X_train_scaled, y_train)
print("Score without interactions: {:.3f}".format(
rf.score(X_test_scaled, y_test)))
rf = RandomForestRegressor(n_estimators=100).fit(X_train_poly, y_train)
print("Score with interactions: {:.3f}".format(rf.score(X_test_poly, y_test)))![]()
可以看出,即使没有额外的特征, 随机森林的性能也要优于Ridge。添加交互项特征和多项式特征实际上会略微降低其性能。