基于深度学习的语义分割与实例分割(一)
本篇文章后文侧重医学领域
图像分割,作为计算机视觉的基础,是图像理解的重要组成部分,也是图像处理的难点之一。
那么,如何优雅且体面的图像分割?
先说一个简单的的吧,也就是先做一回调包侠:实现的库——PixelLib,了解一下。

当然,如此好用的项目,开源是必须的。
为什么要用到图像分割?
虽然计算机视觉研究工作者,会经常接触图像分割的问题,但是我们还是需要对其做下“赘述”(方便初学者)。
我们都知道每个图像都是有一组像素值组成。简单来说,图像分割就是在像素级上,对图像进行分类的任务。
图像分割中使用的一些“独门秘技”,使它可以处理一些关键的计算机视觉任务。主要分为2类:
- 语义分割:就是把图像中每个像素赋予一个类别标签,用不同的颜色来表示。
- 实例分割:它不需要对每个像素进行标记,它只需要找到感兴趣物体的边缘轮廓就行。
它的身影也经常会出现在比较重要的场景中:
- 无人驾驶汽车视觉系统,可以有效的理解道路场景。
- 医疗图像分割,可以帮助医生进行诊断测试。
- 卫星图像分析,等等。
所以,图像分割技术的应用还是非常重要的。
接下来,我们就直奔主题,开始了解一下PixelLib,这个神奇又好用的库。
快速安装PixelLib
PixelLib这个库可以非常简单的实现图像分割——5行代码就可以实现语义分割和实例分割。
老规矩,先介绍一下安装环境。
安装最新版本的TensorFlow、Pillow、OpenCV-Python、scikit-image和PixelLib:
pip3 install tensorflowpip3 install pillowpip3 install opencv-pythonpip3 install scikit-imagepip3 install pixellib
PixelLib实现语义分割
PixelLib在执行语义分割任务时,采用的是Deeplabv3+框架,以及在pascalvoc上预训练的Xception模型。
用在pascalvoc上预训练的Xception模型执行语义分割:
import pixellibfrom pixellib.semantic import semantic_segmentationsegment_image = semantic_segmentation()segment_image.load_pascalvoc_model(“deeplabv3_xception_tf_dim_ordering_tf_kernels.h5”)segment_image.segmentAsPascalvoc(“path_to_image”, output_image_name = “path_to_output_image”)
让我们看一下每行代码:
import pixellibfrom pixellib.semantic import semantic_segmentation#created an instance of semantic segmentation classsegment_image = semantic_segmentation()
用于执行语义分割的类,是从pixellib导入的,创建了一个类的实例。
segment_image.load_pascalvoc_model(“deeplabv3_xception_tf_dim_ordering_tf_kernels.h5”)
调用函数来加载在pascal voc上训练的xception模型(xception模型可以从文末传送门链接处下载)。
segment_image.segmentAsPascalvoc(“path_to_image”, output_image_name = “path_to_output_image”)
这是对图像进行分割的代码行,这个函数包含了两个参数:
- path_to_image:图像被分割的路径。
- path_to_output_image:保存输出图像的路径,图像将被保存在你当前的工作目录中。
接下来,上图,实战!
图像文件命名为:san.jpg,如下图所示。

执行代码如下:
import pixellibfrom pixellib.semantic import semantic_segmentationsegment_image =
semantic_segmentation()segment_image.load_pascalvoc_model(“deeplabv3_xception_tf_dim_ordering_tf_kernels.h
5”)segment_image.segmentAsPascalvoc(“sample1.jpg”, output_image_name = “image_new.jpg”)

可以看到,在执行代码后,保存的图像中,所有对象都被分割了。
也可以对代码稍作修改,获取一张带有目标对象分段重叠(segmentation overlay)的图像。
segment_image.segmentAsPascalvoc(“sample1.jpg”, output_image_name = “image_new.jpg”, overlay = True)
添加了一个额外的参数,并设置为True,就生成了带有分段叠加的图像。
可以通过修改下面的代码,来检查执行分割所需的推理时间。
import pixellibfrom pixellib.semantic import semantic_segmentationimport timesegment_image = semantic_segmentation()segment_image.load_pascalvoc_model(“pascal.h5”)start = time.time()segment_image.segmentAsPascalvoc(“sample1.jpg”, output_image_name= “image_new.jpg”)end = time.time()print(f”Inference Time: {end-start:.2f}seconds”)
输出如下:
Inference Time: 8.19seconds
可以看到,在图像上执行语义分割,只用了8.19秒。
这个xception模型是用pascalvoc数据集训练的,有20个常用对象类别。
对象及其相应的color map如下所示:

源码在最后!
PixelLib实现实例分割
Mask R-CNN是何恺明大神团队提出的一个基于Faster R-CNN模型的一种新型的分割模型,此论文斩获ICCV 2017的最佳论文,在Mask R-CNN的工作中,它主要完成了三件事情:目标检测,目标分类,像素级分割。
恺明大神是在Faster R-CNN的结构基础上加上了Mask预测分支,并且改良了ROI Pooling,提出了ROI Align。其网络结构真容就如下图所示啦:
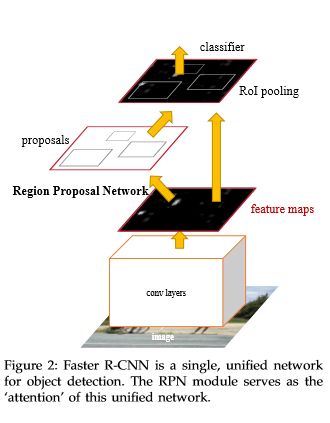
Mask R-CNN的优缺点:
- 引入了预测用的Mask-Head,以像素到像素的方式来预测分割掩膜,并且效果很好;
- 用ROI Align替代了ROI Pooling,去除了RoI Pooling的粗量化,使得提取的特征与输入良好对齐;
- 分类框与预测掩膜共享评价函数,虽然大多数时间影响不大,但是有的时候会对分割结果有所干扰。
虽然语义分割的结果看起来还不错,但在图像分割的某些特定任务上,可能就不太理想。
在语义分割中,相同类别的对象被赋予相同的colormap,因此语义分割可能无法提供特别充分的图像信息。
于是,便诞生了实例分割——同一类别的对象被赋予不同的colormap。
PixelLib在执行实例分割时,基于的框架是Mask RCNN,代码如下:
import pixellibfrom pixellib.instance import instance_segmentationsegment_image = instance_segmentation()segment_image.load_model(“mask_rcnn_coco.h5”)segment_image.segmentImage(“path_to_image”, output_image_name = “output_image_path”)
同样,我们先来拆解一下每行代码。
import pixellibfrom pixellib.instance import instance_segmentationsegment_image = instance_segmentation()
导入了用于执行实例分割的类,创建了该类的一个实例。
segment_image.load_model(“mask_rcnn_coco.h5”)
这是加载 Mask RCNN 模型来执行实例分割的代码(Mask RCNN模型可以从文末传送门链接处下载)。
segment_image.segmentImage(“path_to_image”, output_image_name = “output_image_path”)
这是对图像进行实例分割的代码,它需要两个参数:
-
path_to_image:模型所要预测图像的路径。
-
output_image_name:保存分割结果的路径,将被保存在当前的工作目录中。
-
如上图:

上图,实战第二弹!
图像文件命名为:sample2.jpg,如下图所示。

执行代码如下:
import pixellibfrom pixellib.instance import instance_segmentationsegment_image = instance_segmentation()segment_image.load_model(“mask_rcnn_coco.h5”)segment_image.segmentImage(“sample2.jpg”, output_image_name = “image_new.jpg”)

上图便是保存到目录的图片,现在可以看到语义分割和实例分割之间的明显区别——在实例分割中,同一类别的所有对象,都被赋予了不同的colormap。
若是想用边界框(bounding box)来实现分割,可以对代码稍作修改:
segment_image.segmentImage(“sample2.jpg”, output_image_name = “image_new.jpg”, show_bboxes = True)
这样,就可以得到一个包含分割蒙版和边界框的保存图像。

同样的,也可以通过代码查询实例分割的推理时间:
import pixellibfrom pixellib.instance import instance_segmentationimport timesegment_image = instance_segmentation()segment_image.load_model(“mask_rcnn_coco.h5”)start = time.time()segment_image.segmentImage(“former.jpg”, output_image_name= “image_new.jpg”)end = time.time()print(f”Inference Time: {end-start:.2f}seconds”)
输出结果如下:
Inference Time: 12.55 seconds
可以看到,在图像上执行实例分割,需要12.55秒的时间。
最后,奉上、模型下载地址 百度搜索就有:
PixelLib项目地址:
https://github.com/ayoolaolafenwa/PixelLib
xception模型下载地址:
https://github.com/bonlime/keras-deeplab-v3-plus/releases/download/1.1/deeplabv3_xception_tf_dim_ordering_tf_kernels.h5
Mask RCNN模型下载地址:
https://github.com/matterport/Mask_RCNN/releases/download/v2.0/mask_rcnn_coco.h5
除了使用PixelLib还可以用这些:
2019年CVPR的oral,来自华中科技大学的研究生黄钊金同学提出的
MS R-CNN,这篇文章的提出主要是对上文所说的Mask R-CNN的一点点缺点进行了修正。他的网络结构也是在Mask R-CNN的网络基础上做了一点小小的改进,添加了Mask-IoU。
黄同学在文章中提到:恺明大神的Mask R-CNN已经很好啦!但是有个小毛病,就是评价函数只对目标检测的候选框进行打分,而不是分割模板(就是上文提到的优缺点中最后一点),所以会出现分割模板效果很差但是打分很高的情况。所以黄同学增加了对模板进行打分的MaskIoU Head,并且最终的分割结果在COCO数据集上超越了恺明大神,下面就是MS R-CNN的网络结构啦~
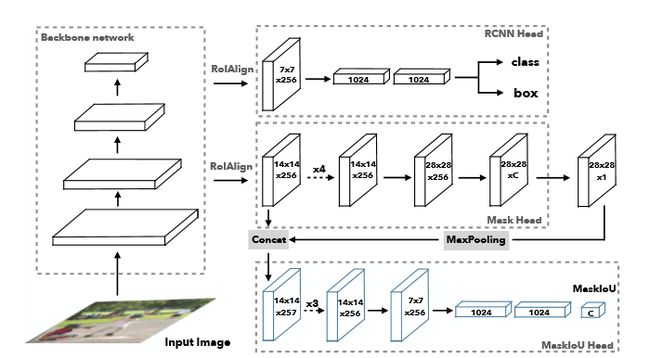
MS R-CNN的优缺点:
- 优化了Mask R-CNN中的信息传播,提高了生成预测模板的质量;
- 未经大批量训练的情况下,就拿下了COCO 2017挑战赛实例分割任务冠军;
- 要说缺点的话。。应该就是整个网络有些庞大,一方面需要ResNet当作主干网络,另一方面需要其它各种Head共同承担各种任务。
3.基于RNN的图像分割
Recurrent neural networks(RNNs)除了在手写和语音识别上表现出色外,在解决计算机视觉的任务上也表现不俗,在本篇文章中我们就将要介绍RNN在2D图像处理上的一些应用,其中也包括介绍使用到它的结构或者思想的一些模型。
RNN是由Long-Short-Term Memory(LSTM)块组成的网络,RNN来自序列数据的长期学习的能力以及随着序列保存记忆的能力使其在许多计算机视觉的任务中游刃有余,其中也包括语义分割以及数据标注的任务。接下来的部分我们将介绍几个使用到RNN结构的用于分割的网络结构模型:
1.ReSeg模型
ReSeg可能不被许多人所熟知,在百度上搜索出的相关说明与解析也不多,但是这是一个很有效的语义分割方法。众所周知,FCN可谓是图像分割领域的开山作,而RegNet的作者则在自己的文章中大胆的提出了FCN的不足:没有考虑到局部或者全局的上下文依赖关系,而在语义分割中这种依赖关系是非常有用的。所以在ReSeg中作者使用RNN去检索上下文信息,以此作为分割的一部分依据。
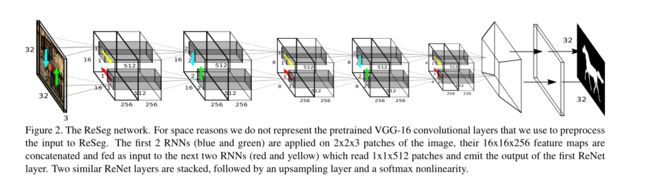
该结构的核心就是Recurrent Layer,它由多个RNN组合在一起,捕获输入数据的局部和全局空间结构。
优缺点:
- 充分考虑了上下文信息关系;
- 使用了中值频率平衡,它通过类的中位数(在训练集上计算)和每个类的频率之间的比值来重新加权类的预测。这就增加了低频率类的分数,这是一个更有噪声的分割掩码的代价,因为被低估的类的概率被高估了,并且可能导致在输出分割掩码中错误分类的像素增加。
2.MDRNNs(Multi-Dimensional Recurrent Neural Networks)模型
传统的RNN在一维序列学习问题上有着很好的表现,比如演讲(speech)和在线手写识别。但是 在多为问题中应用却并不到位。MDRNNs在一定程度上将RNN拓展到多维空间领域,使之在图像处理、视频处理等领域上也能有所表现。
该论文的基本思想是:将单个递归连接替换为多个递归连接,相应可以在一定程度上解决时间随数据样本的增加呈指数增长的问题。以下就是该论文提出的两个前向反馈和反向反馈的算法。

4.基于上采样/反卷积的分割方法
卷积神经网络在进行采样的时候会丢失部分细节信息,这样的目的是得到更具特征的价值。但是这个过程是不可逆的,有的时候会导致后面进行操作的时候图像的分辨率太低,出现细节丢失等问题。因此我们通过上采样在一定程度上可以不全一些丢失的信息,从而得到更加准确的分割边界。
接下来介绍几个非常著名的分割模型:
a.FCN(Fully Convolutional Network)
是的!讲来讲去终于讲到这位大佬了,FCN!在图像分割领域已然成为一个业界标杆,大多数的分割方法多多少少都会利用到FCN或者其中的一部分,比如前面我们讲过的Mask R-CNN。
在FCN当中的反卷积-升采样结构中,图片会先进性上采样(扩大像素);再进行卷积——通过学习获得权值。FCN的网络结构如下图所示:
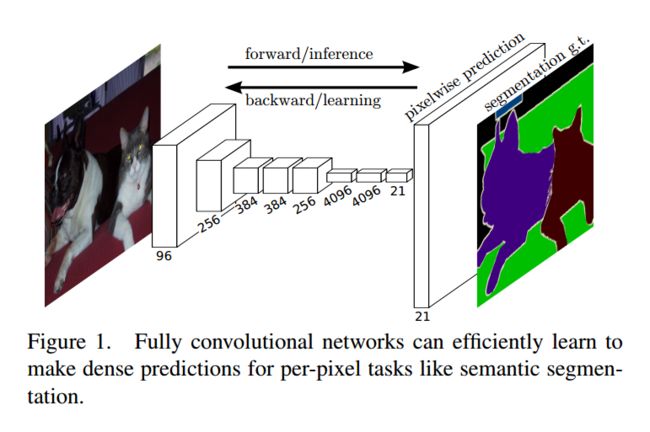
当然最后我们还是需要分析一下FCN,不能无脑吹啦~
优缺点:
- FCN对图像进行了像素级的分类,从而解决了语义级别的图像分割问题;
- FCN可以接受任意尺寸的输入图像,可以保留下原始输入图像中的空间信息;
- 得到的结果由于上采样的原因比较模糊和平滑,对图像中的细节不敏感;
- 对各个像素分别进行分类,没有充分考虑像素与像素的关系,缺乏空间一致性。
2.SetNet
SegNet是剑桥提出的旨在解决自动驾驶或者智能机器人的图像语义分割深度网络,SegNet基于FCN,与FCN的思路十分相似,只是其编码-解码器和FCN的稍有不同,其解码器中使用去池化对特征图进行上采样,并在分各种保持高频细节的完整性;而编码器不使用全连接层,因此是拥有较少参数的轻量级网络:
图像分割是计算机视觉研究中的一个经典难题,已经成为图像理解领域关注的一个热点,图像分割是图像分析的第一步,是计算机视觉的基础,是图像理解的重要组成部分,同时也是图像处理中最困难的问题之一。所谓图像分割是指根据灰度、彩色、空间纹理、几何形状等特征把图像划分成若干个互不相交的区域,使得这些特征在同一区域内表现出一致性或相似性,而在不同区域间表现出明显的不同。简单的说就是在一副图像中,把目标从背景中分离出来。对于灰度图像来说,区域内部的像素一般具有灰度相似性,而在区域的边界上一般具有灰度不连续性。 关于图像分割技术,由于问题本身的重要性和困难性,从20世纪70年代起图像分割问题就吸引了很多研究人员为之付出了巨大的努力。虽然到目前为止,还不存在一个通用的完美的图像分割的方法,但是对于图像分割的一般性规律则基本上已经达成的共识,已经产生了相当多的研究成果和方法。
本文对于目前正在使用的各种图像分割方法进行了一定的归纳总结,由于笔者对于图像分割的了解也是初窥门径,所以难免会有一些错误,还望各位读者多多指正,共同学习进步。
SetNet的优缺点:
- 保存了高频部分的完整性;
- 网络不笨重,参数少,较为轻便;
- 对于分类的边界位置置信度较低;
- 对于难以分辨的类别,例如人与自行车,两者如果有相互重叠,不确定性会增加。
以上两种网络结构就是基于反卷积/上采样的分割方法,当然其中最最最重要的就是FCN了,哪怕是后面大名鼎鼎的SegNet也是基于FCN架构的,而且FCN可谓是语义分割领域中开创级别的网络结构,所以虽然这个部分虽然只有两个网络结构,但是这两位可都是重量级嘉宾,希望各位能够深刻理解~
5.基于提高特征分辨率的分割方法
在这一个模块中我们主要给大家介绍一下基于提升特征分辨率的图像分割的方法。换一种说法其实可以说是恢复在深度卷积神经网络中下降的分辨率,从而获取更多的上下文信息。这一系列我将给大家介绍的是Google提出的DeepLab 。
DeepLab是结合了深度卷积神经网络和概率图模型的方法,应用在语义分割的任务上,目的是做逐像素分类,其先进性体现在DenseCRFs(概率图模型)和DCNN的结合。是将每个像素视为CRF节点,利用远程依赖关系并使用CRF推理直接优化DCNN的损失函数。
在图像分割领域,FCN的一个众所周知的操作就是平滑以后再填充,就是先进行卷积再进行pooling,这样在降低图像尺寸的同时增大感受野,但是在先减小图片尺寸(卷积)再增大尺寸(上采样)的过程中一定有一些信息损失掉了,所以这里就有可以提高的空间。
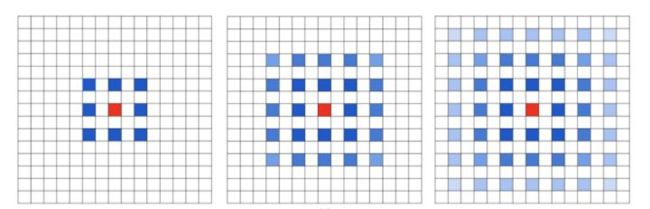
接下来我要介绍的是DeepLab网络的一大亮点:Dilated/Atrous Convolution,它使用的采样方式是带有空洞的采样。在VGG16中使用不同采样率的空洞卷积,可以明确控制网络的感受野。
图a对应3x3的1-dilated conv,它和普通的卷积操作是相同的;图b对应3x3的2-dilated conv,事迹卷积核的尺寸还是3x3(红点),但是空洞为1,其感受野能够达到7x7;图c对应3x3的4-dilated conv,其感受野已经达到了15x15.写到这里相信大家已经明白,在使用空洞卷积的情况下,加大了感受野,使每个卷积输出都包含了较大范围的信息。
这样就解决了DCNN的几个关于分辨率的问题:
1)内部数据结构丢失;空间曾计划信息丢失;
2)小物体信息无法重建;
当然空洞卷积也存在一定的问题,它的问题主要体现在以下两方面:
1)网格效应
加入我们仅仅多次叠加dilation rate 2的 3x3 的卷积核则会出现以下问题
我们发现卷积核并不连续,也就是说并不是所有的像素都用来计算了,这样会丧失信息的连续性;
2)小物体信息处理不当
我们从空洞卷积的设计背景来看可以推测出它是设计来获取long-ranged information。然而空洞步频选取得大获取只有利于大物体得分割,而对于小物体的分割可能并没有好处。所以如何处理好不同大小物体之间的关系也是设计好空洞卷积网络的关键。
6.基于特征增强的分割方法
基于特征增强的分割方法包括:提取多尺度特征或者从一系列嵌套的区域中提取特征。在图像分割的深度网络中,CNN经常应用在图像的小方块上,通常称为以每个像素为中心的固定大小的卷积核,通过观察其周围的小区域来标记每个像素的分类。在图像分割领域,能够覆盖到更大部分的上下文信息的深度网络通常在分割的结果上更加出色,当然这也伴随着更高的计算代价。多尺度特征提取的方法就由此引进。
在这一模块中我先给大家介绍一个叫做SLIC,全称为simple linear iterative cluster的生成超像素的算法。
首先我们要明确一个概念:啥是超像素?其实这个比较容易理解,就像上面说的“小方块”一样,我们平常处理图像的最小单位就是像素了,这就是像素级(pixel-level);而把像素级的图像划分成为区域级(district-level)的图像,把区域当成是最基本的处理单元,这就是超像素啦。
算法大致思想是这样的,将图像从RGB颜色空间转换到CIE-Lab颜色空间,对应每个像素的(L,a,b)颜色值和(x,y)坐标组成一个5维向量V[l, a, b, x, y],两个像素的相似性即可由它们的向量距离来度量,距离越大,相似性越小。
算法首先生成K个种子点,然后在每个种子点的周围空间里搜索距离该种子点最近的若干像素,将他们归为与该种子点一类,直到所有像素点都归类完毕。然后计算这K个超像素里所有像素点的平均向量值,重新得到K个聚类中心,然后再以这K个中心去搜索其周围与其最为相似的若干像素,所有像素都归类完后重新得到K个超像素,更新聚类中心,再次迭代,如此反复直到收敛。
有点像聚类的K-Means算法,最终会得到K个超像素。
Mostahabi等人提出的一种前向传播的分类方法叫做Zoom-Out就使用了SLIC的算法,它从多个不同的级别提取特征:局部级别:超像素本身;远距离级别:能够包好整个目标的区域;全局级别:整个场景。这样综合考虑多尺度的特征对于像素或者超像素的分类以及分割来说都是很有意义的。
接下来的部分我将给大家介绍另一种完整的分割网络:PSPNet:Pyramid Scene Parsing Network
论文提出在场景分割是,大多数的模型会使用FCN的架构,但是FCN在场景之间的关系和全局信息的处理能力存在问题,其典型问题有:1.上下文推断能力不强;2.标签之间的关系处理不好;3.模型可能会忽略小的东西。
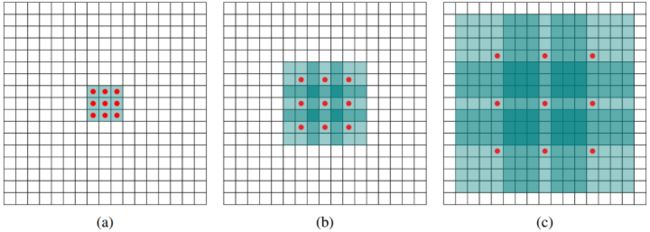
本文提出了一个具有层次全局优先级,包含不同子区域时间的不同尺度的信息,称之为金字塔池化模块。
该模块融合了4种不同金字塔尺度的特征,第一行红色是最粗糙的特征–全局池化生成单个bin输出,后面三行是不同尺度的池化特征。为了保证全局特征的权重,如果金字塔共有N个级别,则在每个级别后使用1×1 1×11×1的卷积将对于级别通道降为原本的1/N。再通过双线性插值获得未池化前的大小,最终concat到一起。其结构如下图:
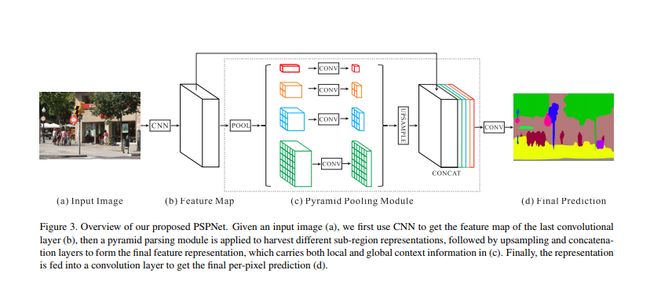
最终结果就是,在融合不同尺度的feature后,达到了语义和细节的融合,模型的性能表现提升很大,作者在很多数据集上都做过训练,最终结果是在MS-COCO数据集上预训练过的效果最好。
为了捕捉多尺度特征,高层特征包含了更多的语义和更少的位置信息。结合多分辨率图像和多尺度特征描述符的优点,在不丢失分辨率的情况下提取图像中的全局和局部信息,这样就能在一定程度上提升网络的性能。
后半部分的资料来源我的关注的公众号:计算机视觉LIFE
深度学习与医学影像分割
一、医学影像分割有助于临床工作
图像分割在影像学诊断中大有用处。自动分割能帮助医生确认病变肿瘤的大小,定量评价治疗前后的效果。除此之外,脏器和病灶的识别和甄别也是一项影像科医生的日常工作。CT和磁共振的数据都是三维数据,这意味着对器官和病灶的分割就需要逐层进行。如果都是手工分割的话,会给医生带来繁重的工作量。实际上,已经有很多学者提出了许多医学影像的分割方法,但由于医学影像复杂,分割目标多变,仍有很多自动分割问题等待解决。
近年来深度学习在计算机视觉的各个细分邻域都取得了出色的成绩,那么,深度学习如何帮助医生得到更满意的图像分割结果呢?本文就从三个深度学习分割网络的改进思路谈起,聊一聊这些改进的出发点和具体实现策略。
二、医学影像分割的特点
2.1 分割问题有别于分类问题
深度学习开始大放异彩的工作,莫过于在ImageNet数据集上,对输入图片的分类了。只要输入图片,就能判断图片中主体所属的类别。然而,和分类问题输入图像输出主体的类别不一样,分割问题需要对每个像素点的类别进行识别。图1就展示了分类和分割的不同点,上图的网络只需要对图片中的主体识别,得到图中有一只小猫的结论,而对下图的分割问题,则需要得出关于这只小猫所在像素点的热力分布图。
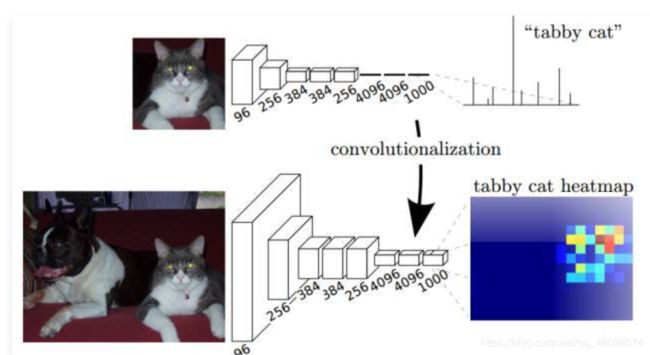
图1 分割和分类的区别[1]
2.2 医学影像的分割精度要求高
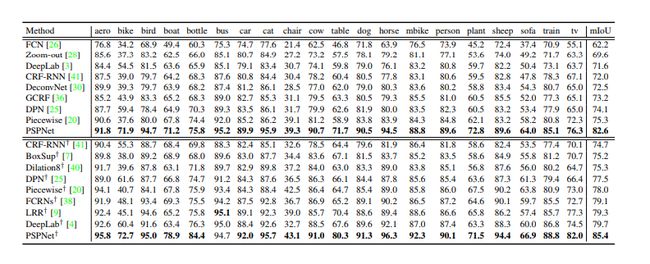
经典的语义分割更重视像素点的多分类信息,往往对多个类别进行分割,对分割细节要求不高。一个典型的例子就是今年发表于CVPR的文章[2]中,对街景的分割。图2可以看出,它出色的捕捉到了像素的类别信息,但是在分割细节上就不是那么的让人满意了。

图2 工作[2]分割结果,左图为待分割图像,中图为金标准,右图为分割结果
而对于医学影像分割,有一个好消息和一个坏消息:好消息是对于医学影像而言,往往不需要进行多分类,只需要进行病灶或器官的区分即可;而坏消息在于,医学影像所需的分割精度较高,同时稳定性也需要很高,但医学影像往往信噪比相对较低,即使是医生也需要长期的专业训练,而一致性也往往会受到医生经验、疲劳程度和耐心程度的限制。
在Kaggle上举办的心室分割比赛要求参赛选手们对心脏的内包膜和外包膜同时进行分割,如图3所示,该任务对分割细节的要求较高。和图2的街景分割任务相比,医学影像的分割细致程度要求较高,不正确或是不稳定的分割将会直接影响心脏射血量的定量计算,从而失去了对医学图像分割的本来意义。
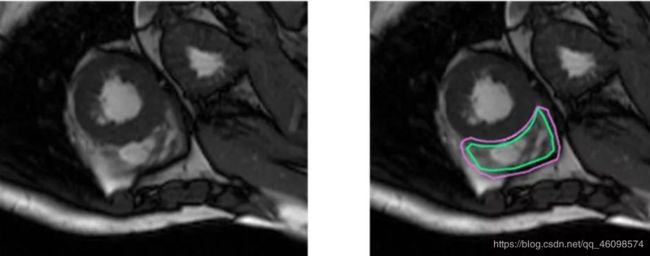
图3 左图为待分割图像,右图为心脏的内包膜和外包膜的分割
三、深度学习分割的开山鼻祖——FCN网络
Fully convolutional network[1]作为分割的代表性工作得到了广泛关注,其核心思想在于将在ImageNet数据集上已经训练好的网络中,深层网络的全连接层改为全卷积层,从而保存分割的位置信息,但是由于最终的分割结果只利用了深层特征映射(feature map),分割结果不够精确。
文章作者也尝试将不同池化(pooling)层的输出进行不同倍数的上采样得到如图4的结果。可以看出,上采样倍数越多(更深层的池化输出)的结果显得越模糊但分类的语义信息较为精确,上采样倍数越少(更浅层的池化输出)的结果保留的分割细节更多而语义信息却不精确。因此,作者指出,该网络中像素类别的精确性和位置的精确性存在着此消彼长的关系。
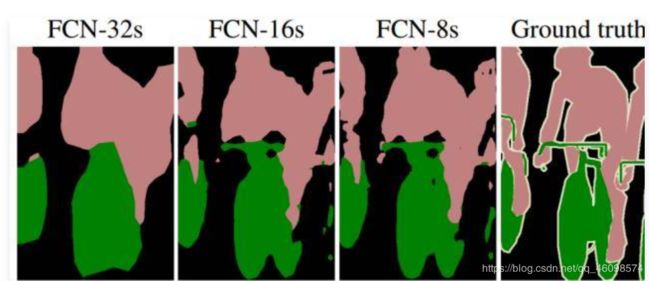
图4 不同池化层做上采样操作后的结果,最右侧为金标准
对于医学影像分割,深度学习已经有了非常出色的表现,而且越来越多的新思路和新方法用于不断提高分割精度和稳健性,并逐渐减轻医生繁琐的日常工作,降低视觉疲劳的压力,成为临床医生的有力工具(文章来源:腾讯云,完整版,请自行搜索)
源码:
import pixellib
from pixellib.semantic import semantic_segmentation
from pixellib.instance import instance_segmentation
segmengt_image = semantic_segmentation()
segmengt_image.load_pascalvoc_model("deeplabv3_xception_tf_dim_ordering_tf_kernels.h5")
segmengt_image.segmentAsPascalvoc("k.jpg", output_image_name="k1.jpg", overlay=True)
segmengt_image = instance_segmentation()
segmengt_image.load_model("mask_rcnn_coco.h5")
segmengt_image.segmentImage("k.jpg", output_image_name="k2.jpg", show_bboxes=True)
这是前辈们的训练及其封装,权重文件可以自行百度或者联系我的微信,我自己的深度学习交流群,也欢迎大家进入!
 上海第二工业大学 智能科学与技术
上海第二工业大学 智能科学与技术
周小夏(CV调包侠)