机器学习(4)-图像分割算法对比小结-RCNN-FCN-boxsup
图像分割算法对比小结
- 1.{基本概念}
- 2.{R-CNN}
- 2.1R-CNN 网络结构
- 选择性搜索算法
- 为什么选择SVM作分类器
- 边框回归
- 2.2{R-CNN 训练}
- 2.3{R-CNN实验结果}
- 2.4{R-CNN语义分割}
- 2.5{补充材料}
- 2.5.1{R-CNN建议区域放缩}
- 2.5.2{IOU阈值设置不一样的原因}
- 2.5.3{Bounding-box回归修正}
- 2.6{R-CNN存在的问题}
- 3.{R-CNN变体}
- 3.1{Fast-RCNN}
- 3.1.1{Fast-RCNN的两点改进}
- 3.1.2{Fast-RCNN实验结果}
- 3.2{Faster-RCNN}
- 3.2.1{Faster-RCNN的核心改进}
- 4.{FCN-全卷积神经网络}
- 4.1{FCN网络结构}
- 4.2{FCN存在的问题}
- 5.{FCN的改进模型}
- 5.1{U-Net}
- 5.1.1{U-Net结构}
- 5.1.2{u-net两点改进}
- 5.2{segNet}
- 5.2.1{segNet结构}
- 5.2.2{segNet两点改进}
- 6.{Mask-RCNN}
- 6.1{Mask-RCNN的结构}
- 6.2{Mask-RCNN的两点改进}
- 6.3{Mask-RCNN的实验效果}
- 7.{弱监督语义分割}
- 7.1{BoxSup}
- 7.1.1{BoxSup的训练流程}
本文总结了从2014年R-CNN 第一次提出之后,将 深度学习 方法应用到图像分割领域的一些经典算法,在每个小节中,附上 文章疑难点 的参考资料。
在讲具体的方法之前,先来看一下以下相关概念。
1.{基本概念}
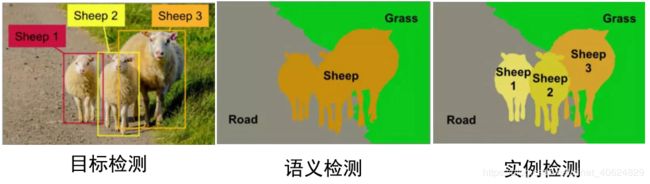
1.object detection-目标检测,检测图片是否带有感兴趣的目标,通常用方框框出来
2.semantic segmentation-语义分割,将图片中目标按不同的语义,以边缘为界分隔
3.instance segmentation-实例分割,将图片中相同语义区域内的不同实例分割开
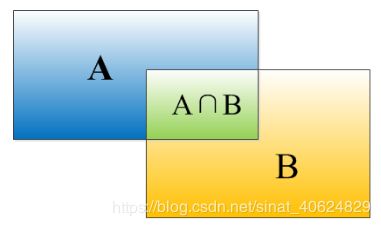
4.IOU-ntersection-over-union
目标检测需要定位出物体的bounding box,IOU用于描述bounding box的定位精度:
I O U = S A ∩ B S A + S B − S A ∩ B IOU=\frac{S_{A\cap B}}{S_A+S_B-S_{A\cap B}} IOU=SA+SB−SA∩BSA∩B
5.mAP:是指每个类别的平均正确率的算术平均值.
详细参考博文:
https://blog.csdn.net/anaijiabao/article/details/101495088
https://blog.csdn.net/a417197457/article/details/80224886
第一类方法:基于建议区域的方法。
第一篇是2014年的r-cnn,区域建议的卷积神经网络用于目标检测语义分割。
2.{R-CNN}
[1]R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic
segmentation. In Computer Vision and Pattern Recognition,
2014.
论文翻译:
R-CNN论文详解(论文翻译):https://blog.csdn.net/v1_vivian/article/details/78599229
【论文翻译】Mask R-CNN:https://blog.csdn.net/xiaqunfeng123/article/details/78716136
在R-CNN之前,overfeat(2013,ImageNet定位任务的冠军)已经使用深度学习的方法做目标检测,但R-CNN是第一个真正可以工业级应用的解决方案。
文章的两个贡献:
(1)apply high-capacity CNNs to bottom-up region proposals in order to localize and segment objects.
(2)when labeled training data is scarce, supervised pre-training for an auxiliary task,followed by domain-specific fine-tuning, yields a significant
performance boost.
2.1R-CNN 网络结构
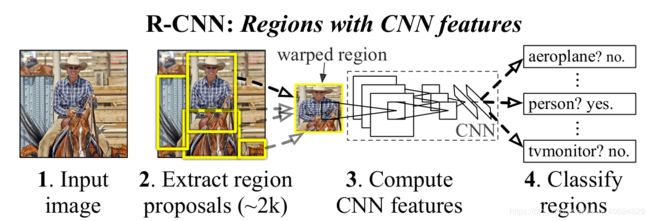
Object detection with R-CNN:
(1)selective search[39](选择性搜索)产生2000个建议区域.
(2)建议区域放缩成277*277,利用Alexnet[25](caffe),对每个放缩后的建议区域提取4096维度的特征.
(3)对特征向量使用每个类别的SVM进行打分,14096-4096(n+1) [n种前景对象+1个背景对象] 将建议区域分到分类得分最高的类别,SVM的得分是里分类面的距离越远越好【每个类别的SVM分类器是提前训练好】
(4)针对每个类别的建议区域,采用非极大值抑制算法去除多余的建议区域。【将与置信度最高的区域IOU值>0.5的区域都去除。】
选择性搜索算法
1)使用一种过分割手段,将图像分割成小区域 (2k~3k 个)
查看现有小区域,
2)按照合并规则最应该合并的相邻两个区域(颜色太相似了)。重复合并操作,直到合并的结果是整张图
3)在曾经存在过的区域中选2000个区域,即为选择性搜索产生的建议区域。
selective search 合并规则:颜色相近(颜色直方图);纹理相近(梯度直方图);合并后总面积小的;合并后总面积在其BBOX中所占比例大的(保证合并后形状规则)
多样化与后处理
颜色想尽规则的补充:
为尽可能不遗漏候选区域,上述操作在多个颜色空间中同时进行(RGB,HSV,Lab等)。在一个颜色空间中,使用上述四条规则的不同组合进行合并。所有颜色空间与所有规则的全部结果,在去除重复后,都作为候选区域输出。
为什么选择SVM作分类器
svm训练和cnn训练过程的正负样本定义方式不同,softmax得到的结果比svm精度低。
边框回归
学习一个线性回归器,用于bounding box的边框回归,输入为Alexnet pool5的输出。
回归的目标是:从 SVM给出的边框 -》真值边框 的x,y方向的平移量 Δ x , Δ y \Delta x,\Delta y Δx,Δy,缩放尺度: S x , S y S_x,S_y Sx,Sy
2.2{R-CNN 训练}
(1)有监督的预训练-AlexNet网络参数粗调整:
ILSVRC2012分类数据集(没有bounding box)上预训练CNN,采用Caffe的CNN库。
(2)特定领域的参数调优-AlexNet网络参数细调整:
结构:随机初始化的(N+1)类的分类层,替换掉ImageNet的1000类的分类层\
输入:变形后的bounding box图像
数据集:VOC2012-train
超参数:SGD,lr=0.001为预训练时的 1 10 \frac{1}{10} 101,避免破坏预训练模型,正样本IOU>=0.5(ground-truth box),mini-batch-size=128(正:负=32:96)
(3)取alexnet输出的特征,为每个物体类训练一个SVM分类器.
数据集:VOC2012-trainval
输入:2000[建议区域]*4096[提取的特征]
SVM权重矩阵:4096[每一个区域的特征]*N[类别数]
正样本:ground-truth box,负样本IOU<0.5,其余全部丢弃.
2.3{R-CNN实验结果}

mAP比当时最好的方法提高了30%左右.
2.4{R-CNN语义分割}
用alexnet对CPMS区域提取特征,进行分类.
CPMS区域的三种处理方式:
(1)和前面的目标检测一样,直接形变矩形区域
(2)取矩形区域的mask,计算特征
(3)简单串联(1)(2)两个的特征
文章没有给出语义分割的效果图,只有在voc2011上的平均正确率,感觉最后也只是切割出了矩形框.
2.5{补充材料}
2.5.1{R-CNN建议区域放缩}
由selective search[39]产生2000个建议区域都是矩形的,但大小不一.附录A中作者展示了三种放缩方案,最终通过实验性能选择了{padding+各向异性} 放缩方法.

(A)bounding box图像
(B)把bounding box的边界对周围图像内容扩展延伸成227*227正方形;如果已经延伸到了原始图片的外边界,那么就用bounding box中的颜色均值填充;
©用固定的背景颜色填充成正方形图片(背景颜色也是采用bounding box的像素颜色均值)
(D)不管图片的长宽比例,直接进行放缩,不管它是否扭曲
在放缩前,先将bounding box向周围图像内容padding.上图第1、3行padding=0,第2、4行padding=16.
2.5.2{IOU阈值设置不一样的原因}
fine-tunning阶段是由于CNN对小样本容易过拟合,需要大量训练数据,故对IoU限制宽松: IoU>0.5的建议框为正样本,否则为负样本
SVM这种机制是由于其适用于小样本训练,故对样本IoU限制严格:Ground Truth为正样本,与Ground Truth相交IoU<0.3的建议框为负样本.
文章解释见附录B
2.5.3{Bounding-box回归修正}
训练了一个线性回归模型,给定一个选推荐区域的pool5特征,去回归一个新的检测窗口.(附录C)
mAP:50.2%->53.7%
2.6{R-CNN存在的问题}
(1)产生的proposal region需要经过warp操作再送入后续网络,导致图像的变形和扭曲.\
(2)每一个proposal region都需要进入CNN网络计算,两千个region存在大量的范围重叠,重复的特征提取带来巨大的计算浪费。
3.{R-CNN变体}
3.1{Fast-RCNN}
[2]R. Girshick, “Fast R-CNN,” in IEEE International Conference on
Computer Vision (ICCV), 2015.
论文翻译:https://blog.csdn.net/u014119694/article/details/88421618

Fast-RCNN算法流程:
-
selective search(选择性搜索)产生2000个建议区域
-
整张图片输进CNN,得到feature map
-
找到每个建议区域在feature map上的映射区域(具体怎么实现的没细看),将这些区域输入ROI pooling层和之后网络.
-
对候选框中提取出的特征,使用分类器判别是否属于一个特定类 ; 对于属于某一特征的候选框,用回归器进一步调整其位置。
3.1.1{Fast-RCNN的两点改进}
{改进1:}全图输入CNN生成一张feature map ,避免重复特征提取
{改进2:}feature map 上大小不一的建议区域,直接输入RoI池化中,不经过放缩形变操作.
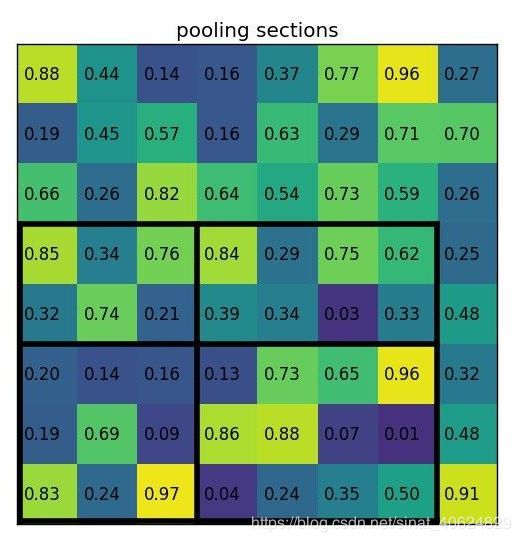
RoI pooling:建议区域大小为wh,池化后的目标尺寸为WH,将wh的区域划分为WH个网格,每个格子的尺寸为[w/W,h/H],对每个[w/W,h/H]格子进行最大/平均池化操作,以达到不同大小的建议区域,经过RoI pooling 之后得到相同大小的特征层.
参考博文:ROI Pooling(感兴趣区域池化)
https://blog.csdn.net/H_hei/article/details/89791176
3.1.2{Fast-RCNN实验结果}

(注:S,M,L为三种不同的训练模型)
Fast-RCNN 比 R-CNN训练快了大概10倍,测试大概快了100倍左右.
3.2{Faster-RCNN}
[3]Ren S , He K , Girshick R , et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2015, 39(6):1137-1149
Faster-RCNN(2015)算法流程:
(1)输入图像到卷积网络中,生成该图像的feature map。
(2)将feature map传入Region Proposal Network,返回object proposals
(3)将object proposals 传入 ROI pooling层和之后网络
(4)(后续部分与R-CNN相同)
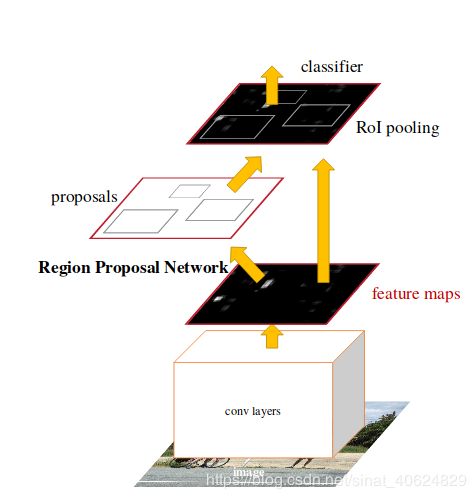
3.2.1{Faster-RCNN的核心改进}
利用Region Proposal Network,优化object proposals的方法.

第二类方法是基于图像逐像素分类的方法,先来看看2015年的第一篇文章,全卷机网络用于语义分割。
4.{FCN-全卷积神经网络}
[5]J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in CVPR, pp. 3431–3440, 2015.
(201503 arXiv)
论文翻译:https://blog.csdn.net/mmmmsunshine/article/details/78921265
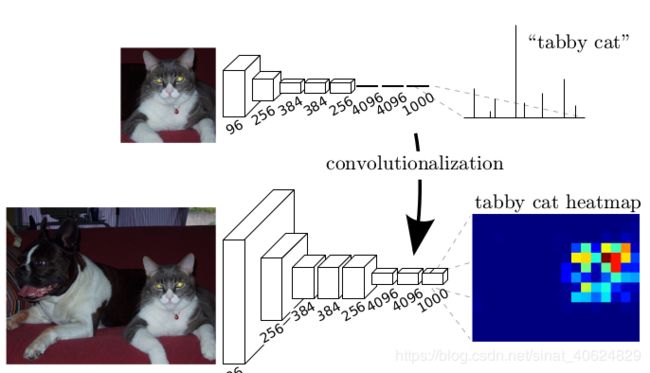
FCN开创性地利用图像逐像素分类,解决了语义级别的图像分割(semantic segmentation)问题。与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全连接层+softmax输出)不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,在最后上的采样的特征图上进行逐像素分类。
4.1{FCN网络结构}
{1.卷积化:}将CNN分类器最后的全连接层换成卷积层,使得网络可以接受任意尺寸的输入,经过全卷积处理之后得到图像的heatmap.
2.上采样:}将heatmap进行上采样处理之后,得到N+1张与原图同样大小的特征图.
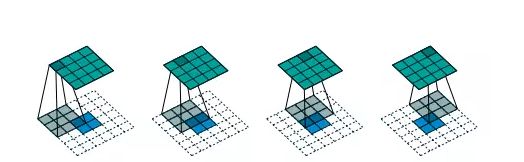
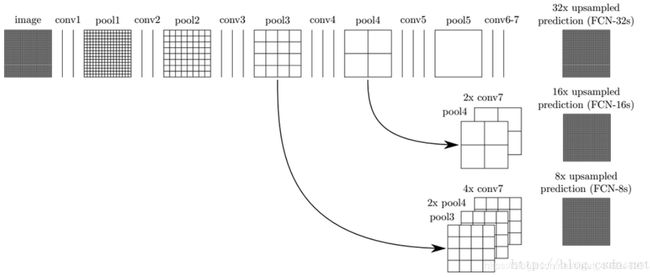
3.跳跃结构(Skip Layer):}直接将heatmap上采样到原图大小,丢失了分割细节.所以作者将heatmap2倍上采样之后,与次层特征相加,再做上采样的以捕捉更多的细节信息.
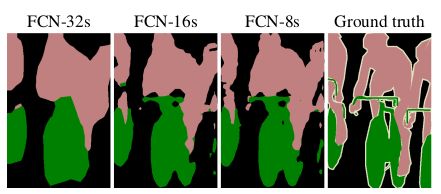
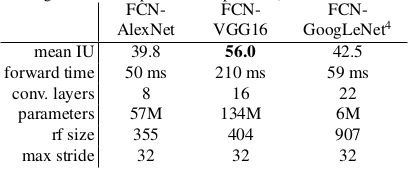
作者对AlexNet,VGG,GoogleLeNet做了网络结构的对比实验,发现VGG的效果最好:
网络超参数设置:
(1)minibatch:20张图片
(2)learning rate:0.001
(3)初始化:分类网络之外的卷积层参数初始化为0
(4)反卷积参数初始化为bilinear插值。最后一层反卷积固定位bilinear插值
4.2{FCN存在的问题}
1.分割的结果不够精细。图像过于模糊或平滑,没有分割出目标图像的细节。
2.因为模型是基于CNN改进而来,即便是用卷积替换了全连接,但是依然是独立像素进行分类,没有充分考虑像素与像素之间的关系。
与当时最先进方法的对比实验(对比R-CNN mean I0U 提高了10%)

在FCN 提出的同年内,随即出现了两个比较不错的改进工作,一个是5月份提出的U-net模型,另一个是11月份提出的segnet模型。
5.{FCN的改进模型}
5.1{U-Net}
[7]Ronneberger O , Fischer P , Brox T . U-Net: Convolutional Networks for Biomedical Image Segmentation[J]. 2015.
(201505 arXiv)
生物学会议ICMICCAI 2015相关的文章,主要是针对生物学影像进行分割。该文考虑到医学影像往往比较少,而深度学习通常需要大量的图像。因此作者使用数据增强提高数据的利用效率;并基于FCN提出U型网络模型,最终在三个生物学数据集上达到了当时最好的性能。
U-Net 因其网络的实用性,小数据学习能力,现在已经成功地被应用到其他领域,例如 卫星图像分割,同时也成为许多模型的改进基础。
5.1.1{U-Net结构}
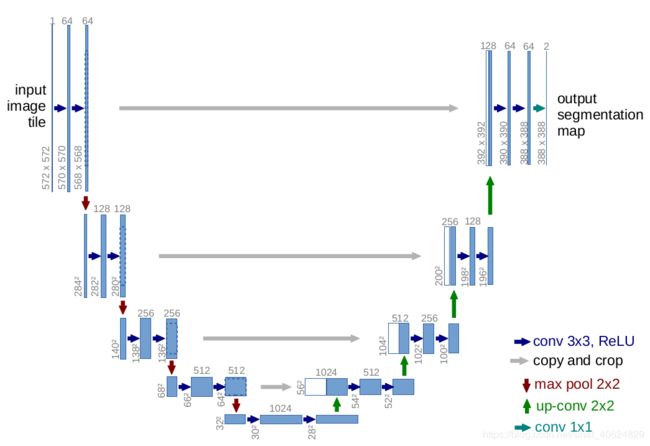
5.1.2{u-net两点改进}
改进1:}结构上编码网络与解码网络对称构成U形结构,编码器用的是典型的CNN,解码时上采样,卷积处理得到特征图与对应的编码层特征图拼接,卷积处理后输入后续的解码层.拼接的过程中,需要将编码层特征图进行剪裁处理.
改进2:} 增加损失函数对分割边界像素的惩罚系数:
E = ∑ x ∈ Ω w ( x ) l o g ( p l ( x ) ( x ) ) E=\sum_{x\in \Omega}w(x)log(p_{l(x)}(x)) E=x∈Ω∑w(x)log(pl(x)(x))
w ( x ) = w c ( x ) + w 0 ∗ e x p ( − d 1 ( x ) + d 2 ( x ) 2 σ 2 ) w(x)=w_c(x)+w_0*exp(-\frac{d_1(x)+d_2(x)}{2\sigma^2}) w(x)=wc(x)+w0∗exp(−2σ2d1(x)+d2(x))
x x x:图像像素点,l(x):x的真是类别
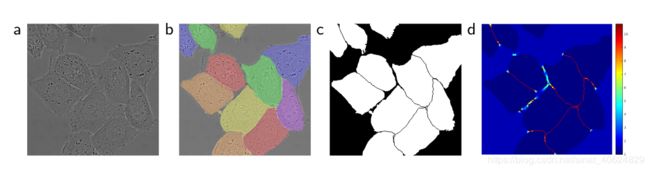
{u-net实验效果图}
5.2{segNet}
[6] Badrinarayanan V , Kendall A , Cipolla R . SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation[J]. 2015.
(201511 arXiv,TPAMI 2015收录)
论文翻译:https://blog.csdn.net/u014451076/article/details/70741629
segnet是专门为道路场景图像语义分割设计的一个网络,作者认为在自动驾驶,场景分析这类实时性要求很高的场景中,模型方法推断过程中内存和计算的效率要十分高效才行.
5.2.1{segNet结构}
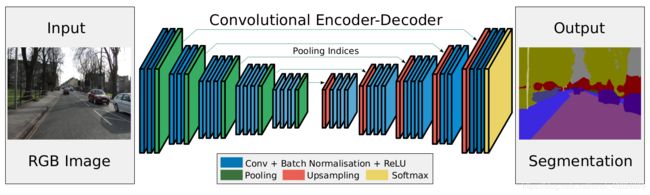
5.2.2{segNet两点改进}
改进1:}去除了VGG16中的全链接层,只留下卷积层.以便减小网络可学习参数,加速end-to-end训练过程.

改进2:}在解码网络中,segNet改进了FCN的上采样去卷积的方式,segNet网络中的解码层,先上采样,再进行卷积操作.上采样过程中接受对应编码层传递过来的max-pooling indices,将特征填入对应的位置.

作者认为如果反卷积过程中利用了对应卷积层的信息,且这个信息越多,对最后的逐像素分类的效果会越好.FCN用了2-3层的卷积层信息(这个在推断阶段的存储代价已经很大了),为了利用更多的信息,又不造成内存压力,segnet 利用了每一卷积层中max -pooling indices.
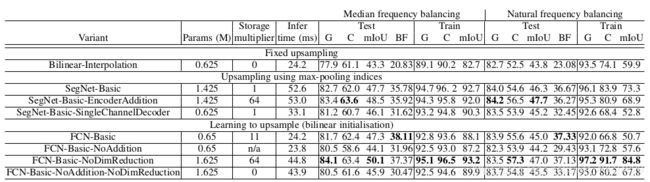
(CamVid road scenes 数据集)
文章贡献:}
(1)提高了边界划分的精度;
(2)减少了可训练参数数量,实现端到端训练;
(3)文中upsampling的形式可以方便地合并到其他模型中[FCN].
接下来看一下第一类和第二类方法的一个结合体:mask-R-cnn
Mask-R-CNN 是何凯明2017年提出的一篇文章,是ICCV2017最佳论文。
6.{Mask-RCNN}
[4] He K , Gkioxari G , Dollar P , et al. Mask R-CNN[C]// 2017 IEEE International Conference on Computer Vision (ICCV). IEEE Computer Society, 2017.
论文翻译:https://blog.csdn.net/xiaqunfeng123/article/details/78716136
Mask R-CNN是ICCV 2017的best paper , Mske R-CNN在Faster R-CNN 架构上添加了一个全卷积网络分支,用于预测每个建议区域的mask,使得整个模型可以集目标检测,目标分类,语义分割三大任务于一体.
6.1{Mask-RCNN的结构}
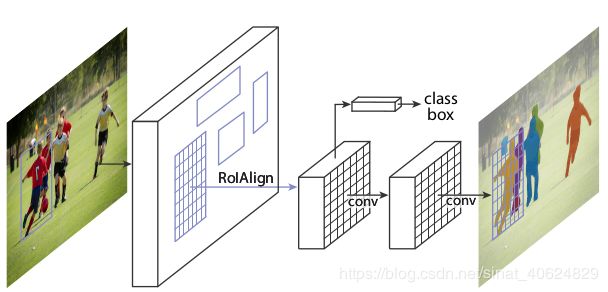
6.2{Mask-RCNN的两点改进}
改进1:RoI Pooling->RoI Align}\
在RPN给出特征图的建议区域之后,将大小不一的建议区域传给RoI Align层进行处理,相比于Faster R-CNN 中的RoI Pooling , RoI Align对建议区域的采用双线性插值计算输入特征的准确值,使AP提高了3%.
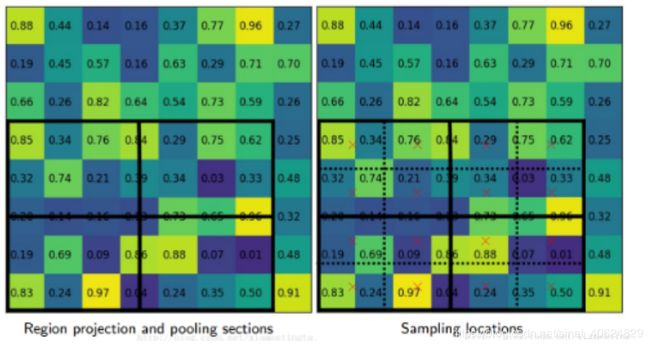
改进2:mask分支}\
经过RoI Align处理后的特征图分两路输入后续的网络:
一路去往和Faster R-CNN 一样的分支(bounding box 的回归与分类);
一路去往Mask分支,产生K个 m ∗ m m*m m∗m二值的mask.
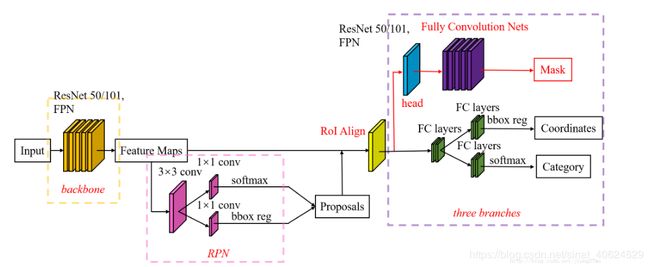
全卷积网络接受feature map产生N个mask图,接受一个来自分类分支的类别标签,选择对应类的maks输出.
训练过程:一个真实标签为k的RoI,对应mask 损失 L m a s k L_{mask} Lmask只由第k个mask 产生,其余mask不起作用.作者认为为每一类别产生mask避免了与其他类别产生竞争现象,使得他的模型比FCN的性能提升了5.5%的AP.
6.3{Mask-RCNN的实验效果}
任务:实例分割
数据集:coco,80k训练集,35k测试集,5k验证集
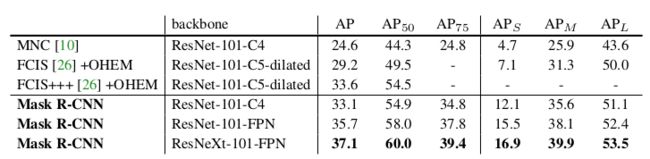
注 : MNC 2015冠军 , FCIS 2016冠军.\
通过实验作者表明Mask rcnn 能更好解决实例分割中的难题:实例重叠场景下的分割.

语义分割中大多数方法都依赖于大量带有像素级标注的图像,然而,手工标注相当费时费力。因此,一些弱监督方法被提出。就个人而言,我一直觉得半监督的方法不太靠谱。下面就介绍一个吧,是2015ICCV 的一个方法。
7.{弱监督语义分割}
7.1{BoxSup}
[8]Dai J , He K , Sun J . BoxSup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation[J]. 2015.
参考博文:论文阅读笔记 | (ICCV 2015) BoxSup
https://blog.csdn.net/qq_16525279/article/details/79812057
7.1.1{BoxSup的训练流程}
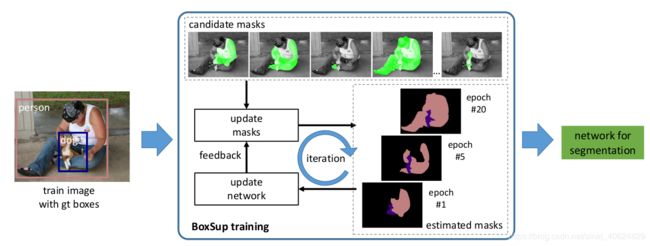
(1)对图片的bounding box ground-truth使用,Multiscale Combinatorial Grouping (MCG)生成分割mask的候选,并优化label选一个与bounding box平均交集最大的mask作为监督信息。
(2)利用上述标签信息更新分割网络(FCN)的参数
(3)基于训练出的语义分割网络对物体框中的前景区域进行预测,提升前景mask 的准确度,再循环训练FCN.
BoxSup的核心思想就是通过这种迭代过程不断提升网络的语义分割能力。
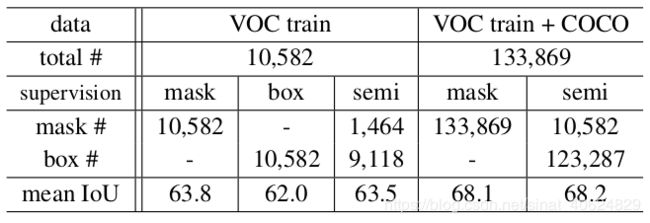
BoxSup 实验结果}
参考资料:
https://perper.site/2019/02/11/RCNN%E8%AF%A6%E8%A7%A3/?nsukey=OzE2MLcBB2GYybpl4cS%2BPGz6N9r7FRNQ02hQVzYylRq3Z1oF9nPap1k0yfBVdjTHXR8tXFih88F6WoVIegQ8uuHEjEQ7%2F1MNLmO23AVmQae5uPFs9su9Xi11UmIUFJRUpfF945J0bnucf6QVcqeuoyqy1dANjcWPRjv1Te4Mdsb5Itfu1H4%2FjsTHwlULqrUCYAeRrpKTau%2Bx%2FTbjfZ5L7w%3D%3D