1.封装:在讲继承之前,我们先谈谈封装,因为封装我们之前已经使用过很多了,所以我们只谈谈封装的概念以及一些优点就行了;
2.封装概念:就是把一些属性以及方法封装在对象里面,外界根本不需要去管内部的一些实现,外界只需要根据内部提供的一些接口去使用就可以了,比如说吹风机,我们只需要知道怎么用就可以了,吹风机内部的实现我们并不需要关心;
3.使用封装的好处:1.使用起来会更方便,因为内部的原理已经实现了,就像是工具箱,我们只管用就可以了,2.保证数据的安全,我们的数据都是放在工具箱里面的,可以把数据设置成只读,或者私有,也可以拦截数据的写操作,进行校验和过滤,这样外界是无法对数据进行直接操作的;3.利于代码的维护,如果后期功能需求发生变化,我们只需要修改内部就可以了,只要不改变接口名称,外界不需要做任何改变;
1.继承:现在我们再来看继承的概念,我们在生活中继承指的是拥有,比如说小明继承了他爸在北京的房子,那么小明就是这个房子的拥有者,我们再来看看python里面的继承,在python里面,继承指的是子类拥有父类的资源的方式之一,这里有两个概念解释一下,这里的拥有和现实中的拥有不太一样,这里的拥有指的是使用权,而不是真正意义上的拥有,资源指的是非私有的属性和方法,继承的目的也就是为了资源的重用;
2.继承的分类:在python里面继承分为了单继承和多继承,这和java就不一样,java只有单继承
2.1单继承:只继承了一个父类:下面是语法,我们可以看到直接在子类的后面写上父类名字就可以了
class Animal:
pass
class Person(Animal):
pass
2.2多继承。继承了多个父类:
class Horse:
pass
class Donkey:
pass
class Mule(Horse,Donkey):
pass
3.元类type和父类object的关系:在python3里面,默认创建的类都是继承object的,也就是新式类,我们可以通过__bases__去查看一个类的父类,所以在python3里面所有的类都具有object的一些资源的使用权,这里在插一句题外话,我们知道描述器只能在新式类中使用,不能在经典类使用,这是为啥呢?现在就可以给出答案了:因为描述器底层是通过__getattribute__这个方法实现的,而我们的新式类就有这个方法,所以新式类中肯定能使用描述器,但是在经典类是没有这个方法的,因为经典类没有父类,只拥有自己的方法;好了,继续看type和object的关系,我们再来回顾一下type,是元类,是创建所有类对象的类,而object是所有类的父类,这是有很大区别的:
4.继承下的影响:
4.1资源的继承:在前面也讲过,在python里面,资源的继承指的是资源的使用权,并不是说子类独立的拥有这个资源,也不说说子类有一份,父类有一份,这里需要注意,另外哪些资源能继承,哪些不能继承呢?其实就只有私有属性,以及私有方法不能继承,其余都能继承;下面我们看看测试代码:
4.2继承资源的重申:也就是说当我们在A类有一个age属性等于9,B类继承自A类,那在B类把age改成10,会不会影响到A类的age呢?答案是不会影响,这种情况会在B类也创建个属性age,也就是说,B类只是继承A类资源的读取权,并不能继承修改权:

4.3资源继承的标准顺序:由于继承分为了单继承和多继承,多继承又分为了无重叠多继承和有重叠多继承,下面我们先来直接看各种继承的访问资源顺序:
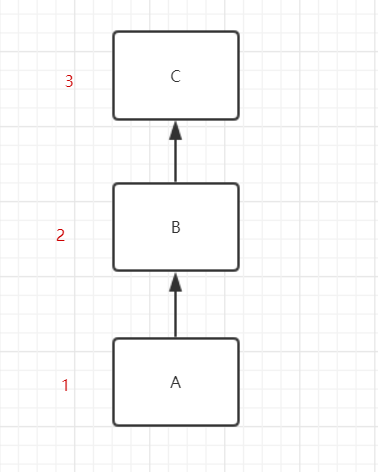
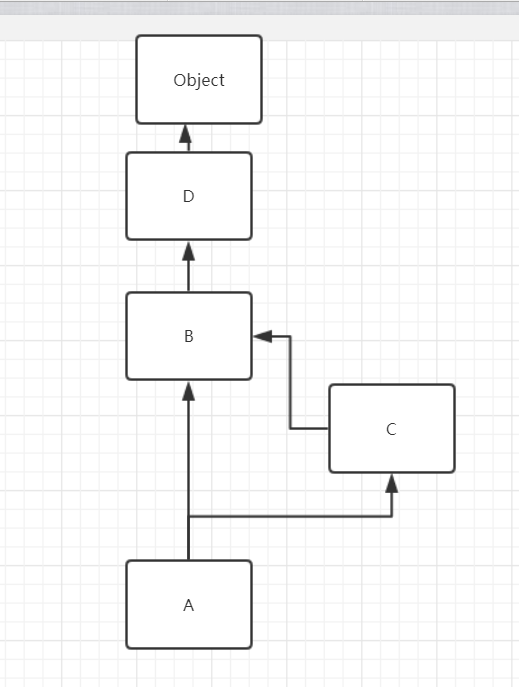
4.3.1单继承:比如说A类继承B类,B类继承C类,那当我们在A类访问某一个资源时,顺序是A-B-C,如下图的1 2 3;从下往上查找
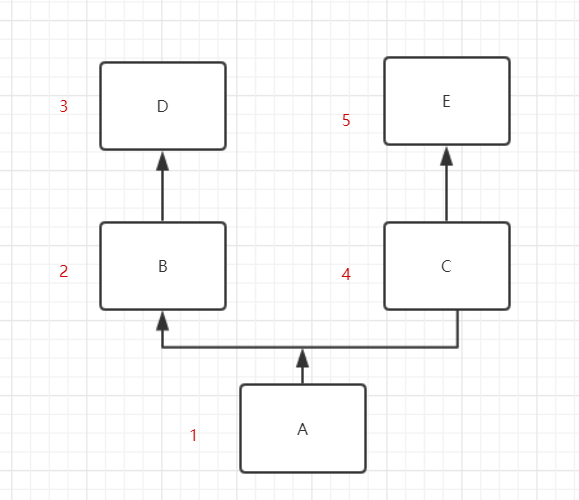
4.3.2无重叠多继承:无重叠多继承访问顺序是A-B-D-C-E,分支查找,从左到右,按分支查找
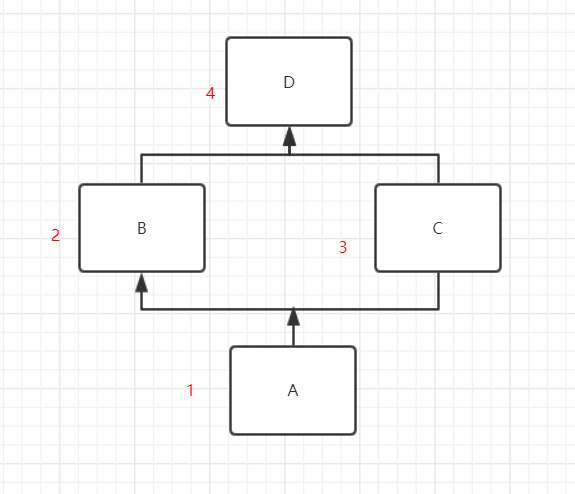
4.3.3:无重叠多继承访问顺序是A-B-C-D,从下往上查找;
4.4到这里,大家肯定都会有疑惑,为什么无重叠多继承访问资源是这个顺序呢?有重叠多继承访问资源又是那个顺序,我们总不能去死记硬背吧,确实,我也不建议大家死记硬背,死记硬背今天能记住,一个礼拜能记住,但是一个月就不一定能记住了,任何东西,我们只要掌握它的原理,就算忘记了,我们也能推导出来,所以我就给大家讲讲为什么是这个顺序;
首先任何一门语言,刚出生也不是十全十美的,Python也不例外,所以讲继承资源我们要从python2版本演化到python3版本的一个过程:
4.4.1:python2.2版本之前:只有经典类,也就是没有继承object的类,那个时候的MRO遵循的是深度优先算法,MRO其实就是资源访问顺序,准确的说是方法解析顺序,方法其实就是资源,解析其实就是访问,从广义上讲就是资源访问顺序,我们在看看深度优先,从左往右的算法:1.把最底层子类也就是目标类压入栈中,2.每次从栈中弹出一个元素也就是一个类,搜索所有在它下一级的元素也就是它的所有父类,把这些元素(父类)压入栈中,3.重复第2个步骤到结束为止;出栈的顺序就是资源的访问顺序,就比如访问集合的元素,取出来的元素就能被访问到是一个道理(栈:就是指只有一端能进行插入或者删除操作,比如水桶只有一个口子,先进后出)下面就用这个算法,分别作用于各种不同的继承,在看看结果
单继承:A-B-C
无重叠多继承:A-B-C-D-E
有重叠多继承:A-B-D-C-D,按照算法就是这样,但是由于D在之前已经查过了,最后再去查D就没有意义了,所以是A-B-D-C,但是其实这种方式违背了重写可用,比如说我们在D类有个age属性,但是我们在D的子类C中重写了age的值,如果用这种方式的话就永远得不到C类的age了,也就是说重写了age但是起不到作用;其实就是跳过了某个父类,直接去找父类的父类,这样肯定是有问题的,就像现实生活中也是不能越级报告,一个道理;所以在python2.2版本之前代码继承的设计都会避开这种继承模式;
python2.2版本:由于继承可以得到父类的很多资源,那么子类就不用在新建这么多资源了,所以在python2.2版本就出现了新式类object,出现了新式类之后,菱形问题就会变得很普遍,所以这个阶段对于有继承自新式类的MRO规则进行了优化,具体规则是:在深度优先,从左到右的基础上如果产生重复元素会保留最后一个,对于全是经典类的MRO规则不变;所以这里对于经典类的继承就不画图了,我们只针对于新式类的继承作一个图:
针对python2.2版本,算法做了一些优化,但是随着一些其他情况的产生,又出现了一些问题,比如说一些混乱的继承,不合理的继承,用这种算法根本检测不问题来并且还能给出结果,比如说:下面这种继承关系,本身就是有问题的,是一种变态的继承,但是我们通过算法根本没有问题,还能得出结果,这里我就不再演示了,大家可以按照深度优先原则进行推算;
所以在python2.3到2.7版本,又进行了优化,在python2.3到2.7版本也是新式类和经典类共存,针对于经典类我们还是按照深度优先算法,而新式类用的就是C3算法;所谓C3算法就是:
算法:L(object)=object;
L(子类(父类1,父类2))=[子类]+merge(L(父类1),L(父类2),[父类1,父类2]);
再来解释一下这个算法,首先+号表示列表的合并,其次就是merge()的计算了,所谓merge就是1.第一个列表的第一个元素是后续列表的第一个元素或者后续列表中没有再次出现则将这个元素合并到最终的结果并从当前操作的所有列表中移除,2.如果不符合则跳过此元素,查找下一个列表的第一个元素,重复1的判断,3.如果最终无法把所有元素归并到解析列表则报错;
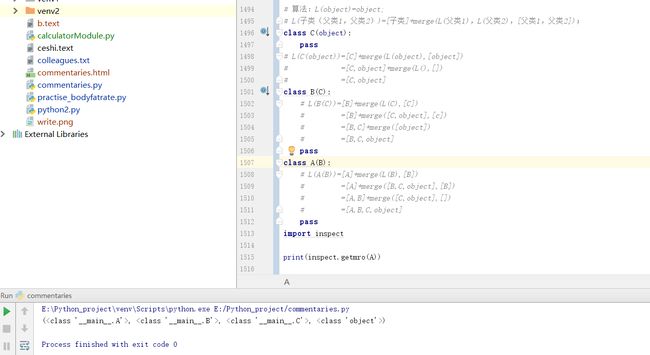
现在我们来检验一下这个算法:这里有一个包是inspect,通过inspect的getmro函数就可以得到mro顺序;
1.单继承:A-B-C-object:
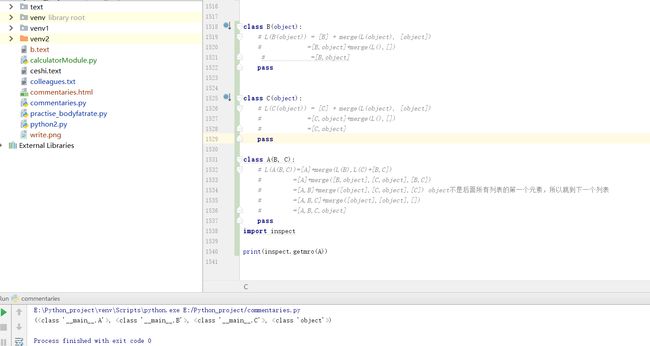
2.有重叠的多继承:
3.现在我们来测试一下2.2版本有问题的继承,看看能不能检测出来:如下所示,确实检测出了问题;

讲了c3算法,我们这里要说明一点就是c3算法并不是拓扑排序,只是在很多情况下两种算法的结果都一样,就好比优化过后的深度优先算法并不是广度优先一样,至于拓扑排序,这里就不讲了,可自行百度;
python3.x版本:我们知道在python2.x版本,对于经典类还是用的深度优先,从左到右的算法,那么只要是经典类,那么菱形问题就依然存在,所以在python3.x版本,我们就把所有的类都默认继承object,就全部是新式类,新式类就使用c3算法;
资源的继承顺序总结:这里就用文字总结一下资源的访问顺序,A:单继承,遵循从下到上原则,B:无重叠多继承,遵循单调原则,优先调用左继承链,在用右继承链,C:有重叠的多继承,也是从下到上原则;我们在资源的继承顺序这里花了很大的篇幅来讲它的各种历史以及算法,其实算法只是工具,我们也没必要去知道为什么算法要这样设计,非要知道的话,就只有去问吉多·范罗苏姆了,其实我们在前面一步一步的分析,大家也知道,算法也是在不断的完善,这种算法的产生是为了解决上个算法出现的问题,所以程序也是一直在更新中,其实在工作中,我们掌握最简单的怎么获取类的MRO顺序就可以了,但是作为一名python开发工程师我们完全有必要去了解python的继承史,这对于我们更深入的研究代码是有深刻意义的;
最后给出获取MRO的几种方法:
import inspect
print(inspect.getmro(A))
print(A.mro())
print(A.__mro__)
对于继承还有两个点没讲,就是资源的覆盖以及资源的累加,这小节内容偏多,我们就把另外两个点放到下一节,大家喜欢的话,点个赞,谢谢大家;