Python3爬虫之二网页解析【爬取自己CSDN博客信息】
与Java类比,Java的网页解析有Jsoup工具,Python的网页解析工具对应的是BeautifulSoup。详情可以阅读其官方文档。
这里以爬取我的CSDN博客信息,包括获取每篇博客的标题、链接、书写日期、访问量、评论数量等信息为例,结合BeautifulSoup,进行网页的解析,详细的说明在代码的注解中讲解。博客首页长这样
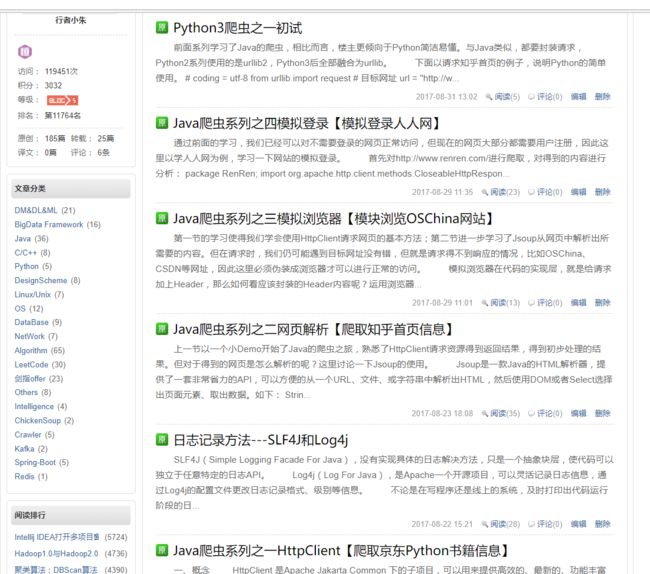
这里讲解一个小技巧,在找爬取目标时,比如这里要获取博客总页数为,在网页(如下)区域,直接“右键 --> 检查”便可直接定位到这个区域对应的源码中的位置,然后通过BeautifulSoup查找对应的元素,即可得到想要的信息。

代码如下:
# coding=utf-8
# 对CSDN博客信息进行爬取,获取博客的主题、链接、日期、访问量、评论数等信息
import re
from urllib import request
from bs4 import BeautifulSoup
class CSDNSpider:
# 初始化爬取的页号、链接以及封装Header
def __init__(self, pageIndex=1, url="http://blog.csdn.net/u012050154/article/list/1"):
self.pageIndex = pageIndex
self.url = url
self.header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36"
}
# 请求网页得到BeautifulSoup对象
def getBeautifulSoup(self, url):
# 请求网页
req = request.Request(url, headers=self.header)
res = request.urlopen(req)
# 以html5lib格式的解析器解析得到BeautifulSoup对象
# 还有其他的格式如:html.parser/lxml/lxml-xml/xml/html5lib
soup = BeautifulSoup(res, 'html5lib')
return soup
# 获取博客的博文分页总数
def getTotalPages(self):
soup = self.getBeautifulSoup(self.url)
# 得到如下内容“209条 共14页”
pageNumText = soup.find('div', 'pagelist').span.get_text()
# 利用正则表达式进一步提取得到分页数
pageNum =re.findall(re.compile(pattern=r'共(.*?)页'), pageNumText)[0]
return int(pageNum)
# 读取每个页面上各博文的主题、链接、日期、访问量、评论数等信息
def getBlogInfo(self, pageIndx):
res = []
# 每页的链接如http://blog.csdn.net/u012050154/article/list/1
# 所以按pageIndex更新url
url = self.url[0:self.url.rfind('/')+1] + str(pageIndx)
# 按url解析得到BeautifulSoup对象
soup = self.getBeautifulSoup(url)
# 得到目标信息
blog_items = soup.find_all('div', 'list_item article_item')
for item in blog_items:
# 博文主题
title = item.find('span', 'link_title').a.get_text()
blog = '标题:' + title
# 博文链接
link = item.find('span', 'link_title').a.get('href')
blog += '\t博客链接:' + link
# 博文发表日期
postdate = item.find('span', 'link_postdate').get_text()
blog += '\t发表日期:' + postdate
# 博文的访问量
views_text = item.find('span', 'link_view').get_text() # 阅读(38)
views = re.findall(re.compile(r'(\d+)'), views_text)[0]
blog += '\t访问量:' + views
# 博文的评论数
comments_text = item.find('span', 'link_comments').get_text()
comments = re.findall(re.compile(r'(\d+)'), comments_text)[0]
blog += '\t评论数:' + comments + '\n'
print(blog)
res.append(blog)
return res
def saveFile(datas ,pageIndex):
path = "D:\\Program\\PythonCrawler\\CSDN\Data\\page_" + str(pageIndex + 1) + ".txt"
with open(path, 'w', encoding='gbk') as file:
file.write('当前页:' + str(pageIndex + 1) + '\n')
for data in datas:
file.write(data)
if __name__=="__main__":
spider = CSDNSpider()
pageNum = spider.getTotalPages()
print("博客总页数:", pageNum)
for index in range(pageNum):
print("正在处理第%s页…" % (index+1))
blogsInfo = spider.getBlogInfo(index+1)
saveFile(blogsInfo, index)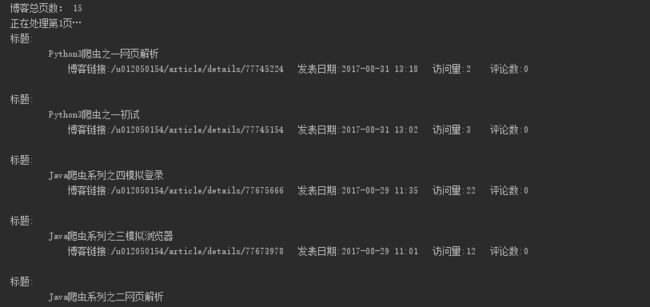

参考文献:
1、Beautiful Soup 4.4.0 文档
2、http://blog.csdn.net/fly_yr/article/details/51557656
Git代码