大沙:阿里巴巴的大数据实时计算应用
摘要:在2018年1月6日的云栖社区数据智能论坛上,阿里巴巴实时计算部的高级技术专家大沙带来了“Blink:大数据实时计算”的分享,大沙对实时计算在阿里的发展背景做了介绍,此外,他还做了Blink Runtime核心优化解读和Flink SQL核心功能解读,并举例说明了阿里巴巴在实时计算方面的应用。
以下为精彩视频整理:
实时计算in阿里巴巴
给大家介绍一下实时计算系统,在阿里巴巴内部也是有很广泛的应用,不仅支撑着内部的所有实时计算,现在阿里对外的输出也是以这套系统为主。阿里巴巴已经不是单纯的电商,它所覆盖的业务的范围是非常大的,所以阿里的数据是EB级的,它的数据增长是TB级的,今年双十一单纯用Blink处理的峰值为4.7亿,每天的峰值都在1亿左右,所以数据量是非常大的。
在阿里内部常常遇到的数据计算场景有下面几类,第一类就是对确定性的数据进行统计,这就是传统的批计算;第二类是实时计算,双十一大屏和实时机器学习都是实时计算应用;第三类就要稍复杂一点不光数据是实时变化的,各种各样的业务逻辑也是变化的。最简单的例子就是算法验证的情况,数据在不停的变更,不能确定哪个是最好的结果。在这个过程中实时计算起到的是一个数据清洗的过程。整体来讲实时计算在阿里巴巴的挑战,首先可能计算非常复杂,需要保证数据只算一次的这种能力,吞吐是非常高的,易延迟,有大量的数据,整个的规模也是非常大的。
我们调研过很多实时计算的架构,最后选择Flink是因为它是纯实时的一个技术,但开源的Flink当时离生产还差的非常远,如何在大规模稳定的环境下去生产可用,我们做了大量的实验。阿里实时计算部基于Flink最终开发了Blink,前年我们主要是做的让它更加稳定,去年我们让API更加的friendly,用户只要care它的业务逻辑是什么,更容易的在上面进行业务开发。
Blink Runtime核心优化解密
实时计算里一个比较重要的概念就是出现问题要回滚,也就是说如果想批计算,批计算是对确定的数据进行计算,如果计算过程中有一些事情发生了突发事件,比如说机器坏掉了,网络断掉了,可以重新从确定的数据中再算一遍。但是实时计算就不行,因为可能这些数据不会保留的,所以需要有一些中间状态。
什么是中间状态,就是在计算过程中需要不停的记下来一些事情,这样的话如果出现突发状况可以从之前记录下的点继续计算,把这种情况叫做拍快照,整个机群在做计算的时候我们每过一段时间拍一张照片,把当前的状态全部记下来,记下状态其实就是对各种各样的中间结果的记录。

如何做的特别高效,早期的Flink大多数人是把所有的Storage读取出来,然后merge跟新的数据,最后再全部存下来。慢慢的发现这么做很难scale,因为Storage太大,磁盘和网络都会打满,最后我们决定就不要做所有的存储,而是在每一次做snapshot的时候记录变化的那部分。很轻量的记住每一部分变化的是什么,这样回滚的时候recovery速度就非常快了。

另外一个就是刚才说到的机器学习这种类型的,很多时候计算节点的这些Storage是放不下的,很多时候需要外部设备。只要在计算过程中和外部的I/O打交道,机器就会在浪费。是因为每次的计算需要通过外部I/O读取一些数据,读取数据的时候CPU的利用率是很低的,因为在等I/O 返回。这个时候相当于浪费了CPU,也就极大的影响了吞吐。一个比较好的设计就是采用异步I/O的模式工作,就是在读取数据的时候,不用等I/O返回就继续让后面的数据继续计算或者读取I/O。异步I/O的计算模式可以选择保序也可以选择不保序。不保序的情况就是哪个I/O请求返回了就往发送哪个,保序的情况下就要把收到的数据buffer下来,直到前面的请求全部返回后,再全部发送。使用异步I/O,整体的实时计算吞吐往往可以达到10-100倍以上。
Flink SQL核心功能解密

Blink计算在API上主推的是SQL。为什么选择SQL呢,是因为下面几个好处:
1)SQL是十分通用的描述性语言,SQL适合用来让用户十分方便的描述Job的需求。
2)SQL拥有比较好的优化框架,使得用户只需要专注于业务逻辑得设计而不用关心状态管理,性能优化等等复杂得设计,这样就大大降低了使用门槛。
3)SQL易懂,适合不同领域的人使用。使用SQL的用户往往都不需要特别多的计算机编程基础,从产品设计到产品开发各种人员都可以快速掌握SQL的使用方法。
4)SQL的API十分稳定,在做机构升级,甚至更换计算引擎时都不用修改用户的Job而继续使用。
5)有些应用场景需要流式更新,批式验证。使用SQL可以统一批计算和流计算的查询query。真正实现一个Query,同样的结果。
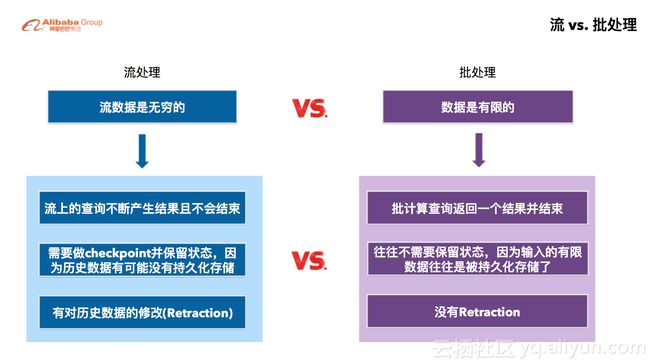
我们的目标就是实时计算要和传统的SQL是同样的语义,要想设计和批处理统一的流计算SQL,就要了解流处理和批处理的区别。两者的核心区别在于流处理的数据是无穷的而批处理的数据是有限的。这个本质区别又能引入另外三个更具体的区别:
1)流处理会不断产生结果而不会结束,批处理往往只返回一个最终结果并且结束。比方说,如果要统计双11的交易金额,使用批处理计算就要在双11当天的所有交易结束后,再开始计算所有买家花费的总金额并得到一个最终数值。而流处理需要追踪实时的交易金额,实时的计算并更新结果。
2)流计算需要做checkpoint并保留状态,这样在failover的时候能够快速续跑。而批计算由于它的输入数据往往是被持久化存储过的,因此往往不需要保留状态。
3)流数据会不断更新,例如某一买家的花费总金额在不断变化,而批处理的数据是一天花费的总金额,是固定的,不会变化的。流数据处理是对最终结果的一个提前观测,往往需要把提前计算的结果撤回(Retraction)做更改而批计算则不会。
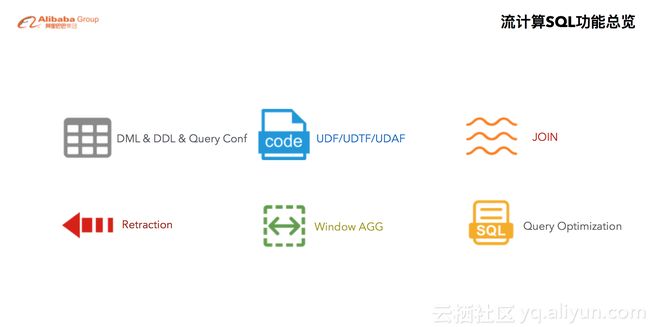
我们实现了流计算所需要的核心ANSI SQL功能,包括:DML、DDL、UDF/UDTF/UDAF、连接Join、撤回(Retraction)、Window聚合等等, 除了这些功能之外,我们还做了大量的查询优化,从而保障了Flink SQL即能满足用户的各种查询的需求,同时兼具优异的查询性能。
阿里巴巴实时计算应用
下面介绍一下阿里内部平台的实时计算应用:
一个是阿里云的StreamCompute,在这个平台上可以开发写SQL,可以对数据进行分析。去开发写SQL去描述他们想要做一件什么事情,然后他能自己看见结果,能展现出来结果,可以发布也可以运维。我们后面还会做一个实时计算的报表分析,很多用户不仅需要实时计算对数据进行清理以外可能还需要数据有一定的展示功能,有一定的前端分析功能。
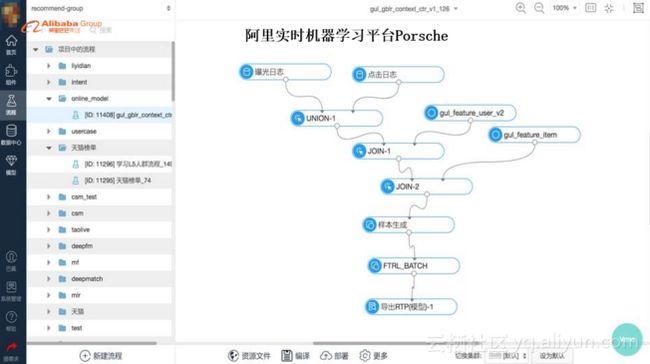
另一个是阿里实时机器学习平台Porsche,还没有推到云上,但内部已经在广泛的用了。SQL基本上可以描述成点、边、框这种托拉拽的形式。机器学习用户只需要理解他要做一件什么事情,我们把各种算法抽象好,抽象成一个个模块,他用拼接起来就好了。
本文由云栖志愿小组smile小太阳整理编辑,审核程弢
活动相关文章
浙江大学杨洋:社交网络中的群体用户行为分析与表示学习
蚂蚁金服西亭:智能金融的技术挑战与方案
阿里云朱金童:深度揭秘ET大脑
阿里巴巴阿外:客服全链路智能解决方案
阿里巴巴少杰:大数据处理实践
阿里巴巴iDST杨森:智能决策在电商平台的应用
阿里巴巴布民:图计算是生产力