旷视 好玩的Thunder Net ,一个超轻量型的检测网络
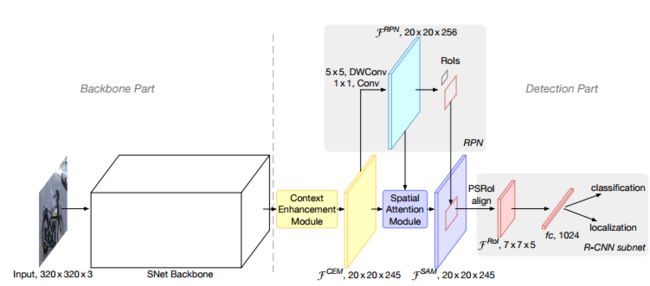
网络结果如下:
本质将(RPN+FPN)进行了结合
提出:1)ShuffleNetV1/V2 限制了骨干网络的感受野
Mobilenetv1/ShuffleNetV1/V2 中采用了3*3的深层可分离卷积,此处用5*5+1*1代替,提高感受野,并且速度不会降
2)ShuffleNetV2 和MobileNetV2 中缺乏浅层信息
提出有益观点:
1)大感受野的骨干网络重要
2)当浅层信息十分丰富时,可以使深层的特征区分更加分明(更加容易学习)(因此,此处引用了几个改进的FPN)
3)避免小骨干大检测这种头轻脚重的状况,引起骨干网络和检测网络间的不平衡,导致计算量增加且易过拟合
4)提出了,训练图片的尺寸应该与骨干网络大小相匹配,过大过小都不好。(即大网络配大图片效果优于大网络小图片,小网络小图片效果优于小网络大图片)
5)作者提出,一个广大的卷积5层固然能够有效提高识别精度,但早期的通道信息操作更有利于定位。
这里,作者用了 1. 一个CEM操作(编译版本的FPN)增加特征图反馈, 2.一个SAM(一个注意力机制)间RPN返回的结果作为先验对CEM输出的通道信息作一个加权(作者说:分类正确时,其低维的通道信息对Local影响很大)
检测网络部分:
一.RPN:用5*5+1*1*256的策略代替原来3*3*256的卷积,增加感受野
二.上下文信息增强策略(Context Enhancement Module)
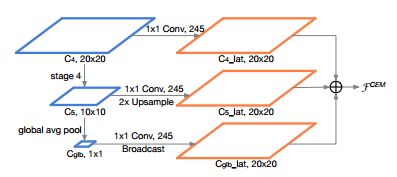
原论文Light-Head R-CNN 中,使用了GCN(全局卷积网络),提高了感受野,但同时也增加了了计算量
我们使用FPN的策略(进行小小的改造),改名(CEM:Context Enhancement Module),如上图利用多尺度融合和GAP代 替了GCN网络,获得全局信息同时亦获得大量的局部信息。
1)骨干输出:20*20(即![]() ,320/16=20)
,320/16=20)
2)进行卷积核上采样
3)特征图融合,输出为20*20
三.Spatial Attention Module ![]()
注意力机制: 我们期望,输入ROI模块时,背景特征信息占比少(不被关注)
此处利用SAM模块,将RPN学习到的信息对输出特征图重新加权(由于RPN主要做二分了工作,其能有效区别前景和背景信息)
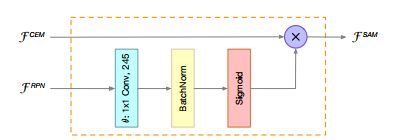
将RPN信息 进行sigmoid 放置在(0,1)分布区间,(这里利用了sigmoid斜率的一个小技巧:偏离小的其对于损失结果影响较大),与CEM网络结果进行惩罚加权
![]()
骨干网络部分:
作者将改造的ShufflenetV2 称之为 SNET

1)为了更好的精度:
一.输入图片由224变为320
二. 5*5+1*1*256的策略代替原来3*3*256的卷积,增加感受野
2)为了更快:SNet49中,作者将Conv5将原来的1024通道压缩为512个通道
在SNet146和SNet535中,作者删除了Conv5并在浅层特征提取阶段添加了更多通道。此设计可生成更多位置信息,而无需额外的计算成本
在Shufflenet中,使用了与mobilenet相似的手段(深度可分离卷积操作):
一.块的概念(block)与组的概念(group):
利用了深度可分离卷积+shuffle操作+Resnet中的shourtcut操作:
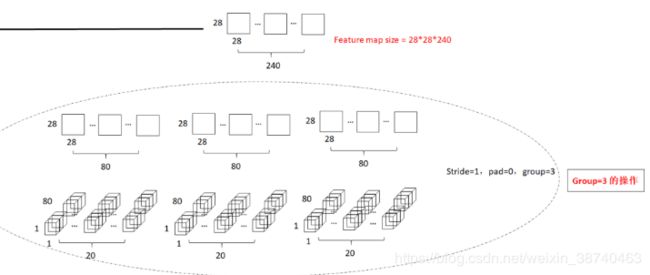
1.深度可分离卷积操作(这里group=3):将28*28*240的输入分为三个28*28*80的部分,(1*1+3*3+1*1操作)最终变为3组 1*1*80的特征图(新通道数为20)
2.shuffle操作:
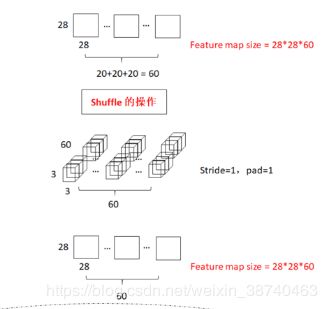
3.Resnet中的shourtcut操作: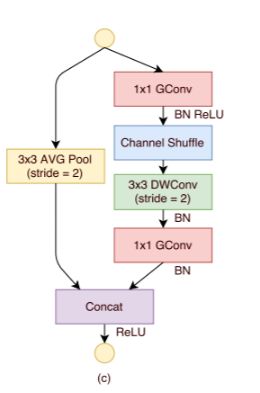
比起传统的shoartcut操作: ,可以减小计算量,使得特征图的大小减半。
,可以减小计算量,使得特征图的大小减半。
2.ShuffleNet V2
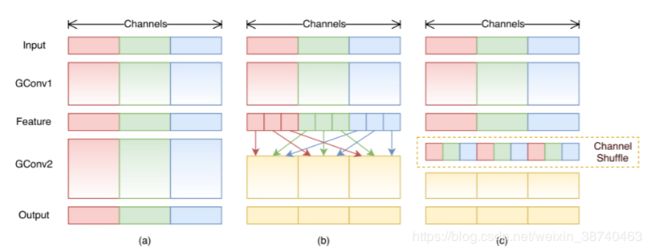
提出:1)FLOPs(float-point operations,乘积数量,与网络结构有关)与损失时间(MAC),决定了训练和预测速度
2)提出了卷积层输入输出通道数、group操作数、网络模型分支数以及Elementwise操作数,这四个因素对内存访问损失时间(MAC)的影响
一.卷积层的输入和输出特征通道数相等时MAC最小,此时模型速度最快
方法:channel split对输入通道对半分
二.过多的group操作会增大MAC,从而使模型速度变慢
方法:channel split替换了group操作
三.模型中的分支数量越少,模型速度越快
方法:将shuffle移到了concat之后(第一个1*1卷积后没有group,shuffle确实不是必须的)
四.减少Elementwise操作,模型速度变快
方法:去掉Elementwise改成concat
原来: 变为:
变为: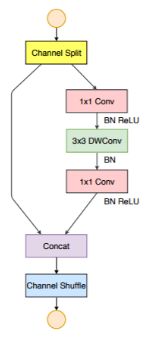
原来: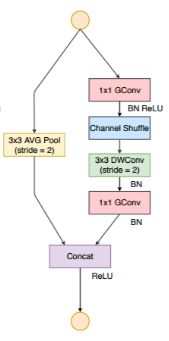 变为:
变为: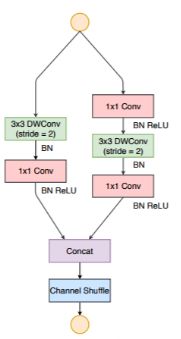
最后提出:
1)MobileNet v1速度较快,由于结构简单
2)IGCV2和IGCV3因为group操作较多,所以整体速度较慢

祝好~!