c++学习课件(四)——线程、make和cmake
c++学习课件(四)——线程、make和cmake
- 一、线程
- 1. 创建线程
- 2. join 和 detach
- 3. 传递参数
- 4. 获取线程id 和 休眠
- 1. 获取线程id
- 2. 线程休眠
- 5. 结束线程
- 6. 并发访问
- 7. 线程同步
- 1. 使用互斥量处理同步
- 2. 面向对象重构
- 3. lock_guard
- 4. unique_guard
- 5. 条件变量
- 二、make和cmake
- 1. make
- 1. 关于程序编译
- 2. makefile 的规则
- 3. makefile 入门
- 2. cmake : make
- 1. CmakeList.txt 解释 : makefile
- 2. 子工程创建
- 3. 变量
- 3. 导入第三方依赖
- 1. 什么是库
- 2. 使用命令生成库
- 3. 导入动态库
- 1 . 导入头文件
- 2. 导入库文件
- 上一篇[C++学习课件(三)](https://blog.csdn.net/weixin_43755186/article/details/105989181)
一、线程
线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务
60年代,在OS中能拥有资源和独立运行的基本单位是进程,然而随着计算机技术的发展,进程出现了很多弊端,一是由于进程是资源拥有者,创建、撤消与切换存在较大的时空开销,因此需要引入轻型进程;二是由于对称多处理机(SMP)出现,可以满足多个运行单位,而多个进程并行开销过大。
因此在80年代,出现了能独立运行的基本单位——线程(Threads)
一般来说一个程序就对应一个进程, 有的程序为了让主进程的压力减小,一般也会开启别的进程。
Android 守护进程 , : 天气类的软件…
1. 创建线程
要想使用线程,需要导入头文件
#include,并且线程并不是linux默认的库,所以需要在cmakelist里面添加这行代码set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -pthread")
#include 2. join 和 detach
join 的意思是让主线程等待子线程执行结束后,在进行下一步,意思是让主线程挂起。
#include detach的意思将本线程从调用线程中分离出来,允许本线程独立执行,从此和主线程再也没有任何关系。(但是当主进程结束的时候,即便是detach()出去的子线程不管有没有完成都会被强制杀死) 。
#include 3. 传递参数
往线程里面执行的函数传递参数,最长使用的办法就是
bind机制 , 这里以在线程内部构建学生对象,从外部传递姓名和年纪数据。
#include 4. 获取线程id 和 休眠
1. 获取线程id
每一个线程在执行的时候,都有自己的一个标识id, 只有在少数情况下,线程的id会变得与众不同。通过
t.get_id()获取线程对一个的id, 也可以使用get_id()获取当前线程的id。
#include 2. 线程休眠
让线程休眠,等待一段时间然后继续执行,这样的场景在开发的时候经常会出现,在 c++中,让线程休眠,如果是在windows可以使用
windows.h头文件中的Sleep函数 , 如果是linux 系统,可以使用#include里面的usleep函数 或者 也可以使用this_thread::里面的sleep_for函数 .
#include 5. 结束线程
线程的退出,手段还是很多的,但是万般手段中,建议使用的只有一个。
1、自行手动退出(函数返回、条件标记 false 、抛出异常等等)(建议使用)
2、通过调用ExitThread函数,线程将自行撤消(最好不使用该方法)。
3、同一个进程或另一个进程中的线程调用TerminateThread函数(应避免使用该方法)。
4、ExitProcess和TerminateProcess函数也可以用来终止线程的运行(应避免使用该方法)。
#include 6. 并发访问
由于
cout对象并不会产生互斥 , 让线程有先有后,所以在多线程场景下,输出的结果并不是我们想要的,显得杂乱无章。这时候可以使用mutex来控制互斥
#include 7. 线程同步
如果有多个线程要同时访问一个变量或对象时,如果这些线程中既有读又有写操作 , 或者同时写入 ,就会导致变量值或数据出现混乱,从而导致程序异常。
举个例子,机器人的两只手臂同时从工作台上搬离积木,完美的情况是前后交错执行,不会有空着手臂回去的情况,但是有时也会发生一些特殊的情况,比如此时工作台上只剩下最后一块积木了,两只手臂同时执行搬离的操作,此时就会有一只手臂空着回来了。多线程同步就是要解决这类问题。
为了解决这类多线程并发的问题,必须使用同步来处理。在c++里面常用互斥量来处理线程的同步问题,除了互斥量之外,还有使用
信号量、临界区、事件等。
1. 使用互斥量处理同步
#include
#include 2. 面向对象重构
接下来使用面向对象的方式,实现两个机械臂从工作台上搬运积木的场景。需要有盒子类、工作台类、左机械臂类、右机械臂类。
1. 盒子类
只需要表示盒子即可,所以盒子类中并没有任何成员变量
class Box{};
2. 工作台类
工作台包含存放盒子的队列,在构造函数中,对队列进行初始化 , 即默认工作台上有10个盒子。并且对外提供把盒子搬走的函数,为了方便打印日志,需要提供一个名字,表示当前是谁在搬运盒子。
//工作台
class WorkTable{
queue<Box> q ; //队列用于存储盒子
mutex m; //互斥元
public:
WorkTable() {
cout << "执行工作台的构造函数~!" <<endl;
for (int i = 0; i < 10; ++i) {
q.push(Box());
}
}
~WorkTable(){
cout << "执行工作台的析构函数~!" <<endl;
}
//搬离盒子
void moveOut(string name){
//上锁
m.lock();
if(!q.empty() ){
usleep(1000 * 500);
q.pop(); //从队列中弹出盒子
cout << name << " 搬走了一个盒子,剩余" << q.size() << endl;
}
//解锁
m.unlock();
}
};
3. 机械臂
机械臂类中包含一个工作台的引用,为了避免产生拷贝,该引用使用指针类型,并且提供一个循环移动盒子的函数,实际上其内部是通过指针去调用工作台的搬运盒子函数而已。并且未来为了能够应对左臂和右臂休眠时间的差异性,所以要求在移动盒子的函数中传递进来手臂的名称以及休眠的时间。
class Hand{
WorkTable * wt;
public:
Hand(WorkTable *wt) : wt(wt) {}
~Hand() {
delete wt;
}
//移动盒子
void moveBox(string name ,long time){
while(1){
wt->moveOut(name);
usleep(time);
}
}
};
4. main函数
main函数提供两个线程,分别对应执行左臂和右臂的moveBox函数,为了使线程能够完整运行,需要使用join函数阻塞线程。
int main() {
//构建工作台
WorkTable wt;
//构建father和 son对象
Hand leftHand(&wt);
Hand rightHand(&wt);
thread t1(bind(&LeftHand::moveBox , &leftHand , "right" , 1000 * 100));
thread t2(bind(&rightHand::moveBox , &RightHand, "left" , 1000 * 50));
t1.join();
t2.join();
return 0;
}
3. lock_guard
一般来说不建议直接调用
mutex的成员函数lock或者unlock来执行加锁解锁的操作,这要求程序员必须准确的知道在什么位置进行解锁操作。c++ 提供了一个模板类 lock_guard ,可以对mutex进行包装,在执行lock_guard的构造时进行加锁操作,执行lock_guard析构时进行解锁操作
#include 4. unique_guard
unique_guard拥有lock_guard的所有功能,并且内部还提供了加锁和解锁的操作,以便对加锁的粒度进行细化,而lock_guard的加锁范围通常是一个范围区域(比如函数) 。unique_lock对于锁的管理比较灵活.它不像lock_guard一样.必须要求他管理的锁在他初始化的时候必须加锁.而是可以自己灵活的.想加锁.就加锁.值得注意的是,条件变量需要和
unique_guard搭配使用。
#include 5. 条件变量
条件变量时从
condition_variable直接翻译过来的,条件变量可以很好的管理多线程的并发操作。条件变量可以让线程达到某个条件的时候进入等待状态, 当条件变成对立面的时候线程继续执行。条件的变更可以依赖其他线程来完成,使用条件变量,需要引入#include
如:搬运到银行存款和取款的操作,孩子去银行取款,如果余额不足时,将会进入等待状态(无需每次都去轮询账户) , 父亲执行完存款操作后,通知孩子可以去取款了。
- 使用普通的休眠手段能处理
下面的例子是父亲往账户里面存钱,儿子从账户里面取钱。不管是谁,存钱和取钱都需要耗费一些时间,所以都需要让线程休眠。
#include - 使用条件变量实现
上面的实现手法,看似没有什么错误。但仍有些缺陷 : 即孩子的取钱操作,不知道休眠多久合适,休眠时间过长,则让自己等待的时间过长,休眠的时间太短,则有可能取钱的时候,账户里面的钱还不够。那么能否有一种机制,父亲把钱存够了之后,通知孩子去取即可呢?
二、make和cmake
1. make
make,常指一条计算机指令 ,可以从一个名为Makefile的文件中获得如何构建程序的依赖关系。通常项目的编译规则就定义在makrfile 里面,比如: 规定先编译哪些文件,后编译哪些文件… 当编写一个程序时,可以为它编写一个makefile文件,不过在windows下的很多IDE 工具,内部都集成了这些编译的工作,只需要点击某一个按钮,一切就完成了。换算到手动操作的话,就需要编写一个makefile文件,然后使用make命令执行编译和后续的安装。
1. 关于程序编译
- 预编译
a. 把头文件合并过来
b. 把宏都替换一下
#define AGE 18
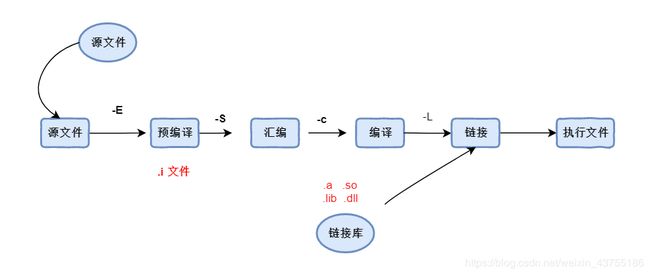
2. makefile 的规则
如果项目的文件很多,那么makefile的内容也会很多,但是最核心的规则即是下面的几行语句。
target: 表示生成目标文件
prerequisites: 生成目标文件依赖的文件
command: 表示命令,也就是从右到左的命令是什么。
- **makefile语法 : **
目标: 依赖的文件
执行的命令
target ... : prerequisites ...
command
target ... : prerequisites ...
command
...
...
- 示例
这是一个简单的makefile文件内容,表示最终要构建出一个main.o 文件, 根据两个源文件main.cpp 和 a.cpp构建 , 最后的那一行表示执行构建的真正命令。
main.o : main.cpp a.cpp
g++ -std=c++11 main.cpp
- 只想编译
target: 表示生成目标文件 main.o , 文件的编译来源是 main.cpp g++: 表示编译 c++代码 , 如果编译c代码,使用 cc(其实就是 gcc) 编译。
-c: 表示只编译,不会生成执行程序。
main.o : main.cpp
g++ -c main.cpp
3. makefile 入门
在编写makefile的时候,可以指定最终生成的程序名称,并且可以由多个目标文件组合生成。
heima : main.o stu.o
g++ -o heima main.o stu.o
main.o : main.cpp
stu.o : stu.cpp
- 清空目标
在完成程序构建后,除了生成真正执行的程序文件之外,还生成了中间临时文件 , 那么可以在makefile文件的最后,清除这些文件。 需要手动执行
make clean命令
heima : main.o stu.o
g++ -o heima main.o stu.o
clean:
rm heima main.o stu.o
更为稳健的做法是
.PPHONY表示clean是一个伪目标 , “伪目标”并不是一个文件,只是一个标签,由于“伪目标”不是 文件,所以make无 法生成它的依赖关系和决定它是否要执行。我们只有通过显式地指明这个“目标”才能让其 生效。
.PHONY : clean
clean :
-rm heima main.o stu.o
2. cmake : make
cmake 其实是一个工具,类似的工具有
GNU MakeQT的qmake, 微软的MS nmake… 每一种开发工具,为了便于使用,都有自己的一套编译规则,项目编译的规则。cmake : cmakelist.txt
qmake : aa.pro
nmaeke :
make :makefile
, 在每一种标准下写一次makefile . 为了解决这些问题,Cmake应运而生。
- 允许开发者编写一种平台无关的 CMakeList.txt 文件来定制整个编译流程
- 然后再根据目标用户的平台进一步生成所需的本地化 Makefile 和工程文件,如 Unix 的 Makefile 或 Windows 的 Visual Studio 工程。从而做到“Write once, run everywhere”。
1. CmakeList.txt 解释 : makefile
对于简单的项目,
CmakeList.txt的内容非常简单,只有简单的几行。
# 表示cmake的最低版本
cmake_minimum_required (VERSION 2.6)
# 表示目前编译的项目
project (day07)
# 表示当前编译使用c++14版本来编译程序
set(CMAKE_CXX_STANDARD 14)
# 表示项目的执行程序, 括号中的day07 表示最终生成的执行程序名称, 后面的表示程序的源码文件
add_executable(day07 main.cpp stu.cpp)
2. 子工程创建
clion创建出来的工程师单一独立的工程,在同一窗口下,不允许创建两个工程,但是允许通过创建子工程。并且随着idea家族主推的项目和模块的理念,子工程的创建也符合了这一特征。每一个子工程都需要有自己的
cmaklist.txt并且在外部主工程的cmakelist.txt中注册子工程。
- 子工程的cmakelist.txt
add_executable(bb bb.cpp)
- 主工程的cmakelist.txt
cmake_minimum_required(VERSION 3.14)
project(AA)
set(CMAKE_CXX_STANDARD 14)
# 主工程标注子目录
add_subdirectory(BB)
add_executable(aa aa.cpp)
3. 变量
在cmakelist.txt 中,也可以定义变量。以方便未来能继续使用这份数据。需要注意的是,变量也可以做增量设置,有点类似容器中的追加的意思。
set(AGE 18) #定义一个变量AGE 值:18
set(CMAKE_CXX_STANDARD 14) # 定义一个变量CMAKE_CXX_STANDARD 名称14
set(AGE ${AGE} 19);
- 输出变量数据
# 输出警告信息
message(WARNING "这是警告信息")
# 输出正常
message(STATUS "这是正常输出")
set(AGE ${AGE} 19);
message(STATUS ${AGE})
3. 导入第三方依赖
在C/C++中,项目最终都会分成两个部分内容,一个是
头文件( .h )一部分是源文件( .cpp )。 如果要编写好的功能给其他程序使用,通常会把源文件打包形成一个动态链接库文件( .so .dll ) 文件 。 值得注意的是,头文件一般不会打包到链接库中,因为头文件仅仅只是声明而已。 链接库也增加了代码的重用性、提高编码的效率,也可看看成是对源码的一种保护。
1. 什么是库
库是写好的现有的,成熟的,可以复用的源代码。现实中每个程序都要依赖很多基础的底层库,不可能每个人的代码都从零开始,因此库的存在意义非同寻常 。 本质上来说库是一种可执行代码的二进制形式,可以被操作系统载入内存执行。库有两种:
静态库(.a、.lib)和动态库(.so、.dll)
windows`上对应的是 `.lib` `.dll
linux` 上对应的是 `.a` `.so
- 静态链接库
静态库最终需要和使用的源程序,打包到一起形成一个新的可执行程序。这就使得有关程序运行依赖的库已经在程序中包含,即便到了客户机上,也能够运行。静态库对程序的更新、部署和发布页会带来麻烦。如果静态库liba.lib更新了,所以使用它的应用程序都需要重新编译、发布给用户。 linux下的静态库文件是 .a 而windows的静态库文件是.lib
- 动态链接库
动态库在程序编译时并不会被连接到目标代码中,而是在程序运行是才被载入。不同的应用程序如果调用相同的库,那么在内存里只需要有一份该共享库的实例,规避了空间浪费问题。动态库在程序运行是才被载入,也解决了静态库对程序的更新、部署和发布页会带来麻烦。用户只需要更新动态库即可,增量更新。
2. 使用命令生成库
一般来说,只会把源码打包到库当中,而头文件则会被排除在外。 假设现在有一个
heima.h头文件 和 对应的源文件heima.cpp
**-fPIC **:( Position-Independent Code) 作用于编译阶段,告诉编译器产生与位置无关代码(Position-Independent Code),则产生的代码中,没有绝对地址,全部使用相对地址,故而代码可以被加载器加载到内存的任意位置,都可以正确的执行。这正是共享库所要求的,共享库被加载时,在内存的位置不是固定的。
-shared: 生成共享目标文件。通常用在建立共享库使用
//linux
g++ -fPIC -shared heima.cpp -o heima2.so
windows
g++ -fPIC -shared heima.cpp -o heima2.dll
3. 导入动态库
导入动态库是c/c++ 开发中必不可少的一个环节,由于clion使用cmake来管理项目。
导入依赖库,需要导入两个部分的内容:头文件和源文件。源文件一般已经被打成了.so文件,所以实际上就是导入头文件和 导入.so文件。
1 . 导入头文件
头文件一般会放置在一个文件夹include中,可以把这个文件夹拷贝到工程内部,也可以放置在外部磁盘上,只需要指定地址找到它即可。
include_directories("3rdparty/heima/include")
2. 导入库文件
如果只导入了头文件,而没有到实现文件,那么会抛出异常,比如:xxx未定义之类的错误。导入so文件
值得注意的是:如果是在windows系统下,需要把dll所在的文件夹,加入到运行环境中。
- 直接和执行程序关联
# 导入头文件
include_directories("3rdparty/heima/include")
# 添加执行程序
add_executable(main main.cpp)
#给程序关联上so文件
target_link_libraries(main ${PROJECT_SOURCE_DIR}/3rdparty/heima/lib/libitcast.so)
- 添加多个依赖库
# 导入头文件
include_directories("3rdparty/heima/include")
# 导入另一个库的头文件
include_directories("3rdparty/itcast/include")
# 添加执行程序
add_executable(main main.cpp)
#给程序关联上so文件
target_link_libraries(main ${PROJECT_SOURCE_DIR}/3rdparty/heima/lib/libheima.so)
target_link_libraries(main ${PROJECT_SOURCE_DIR}/3rdparty/itcast/lib/libitcast.so)
- 还可以使用变量的方式声明,再引用
# 导入头文件
include_directories("3rdparty/heima/include")
# 导入另一个库的头文件
include_directories("3rdparty/itcast/include")
# 添加执行程序
add_executable(main main.cpp)
#使用变量声明
set(ITCAST_LIB ${PROJECT_SOURCE_DIR}/3rdparty/itcast/lib/libitcast.so)
set(ITHEIMA_LIB ${PROJECT_SOURCE_DIR}/3rdparty/heima/lib/libheima.so)
#给程序关联上so文件
target_link_libraries(main ${ITCAST_LIB})
target_link_libraries(main ${ITHEIMA_LIB})
- 使用find_library 查找库文件
在知道地址路径的情况下可以使用find_library来查找库文件,相比于前面的直接设置,find_library还可以设置查找的规则。
# 导入头文件
include_directories("3rdparty/heima/include")
# 导入另一个库的头文件
include_directories("3rdparty/itcast/include")
#find_library ( name1 [path1 path2 ...])
# 查找库文件,第一个ITCASTLIB 表示变量名,即找到之后用这个变量来存着库文件
# 第二个icast 表示要查找的库名称。 cmake具有隐式命名的规则, libaa.so , 那么此处只需要写aa即可
# 第三个 HINTS 也可以写成PATHS 表示指定路径的意思
# 第四个 后面写的就是地址,表示到这个地址去查找库文件, 地址可以写多个。
find_library(ITCASTLIB itcast HINTS ${PROJECT_SOURCE_DIR}/3rdparty/google/itcast/lib)
find_library(HEIMALIB heima HINTS ${PROJECT_SOURCE_DIR}/3rdparty/google/heima/lib)
# 添加执行程序
add_executable(main main.cpp)
target_link_libraries(main ${ITCASTLIB} ${HEIMALIB})