Pytorch入门+实战系列七:图片风格迁移和GAN
Pytorch官方文档:https://pytorch.org/docs/stable/torch.html?
1. 写在前面
今天开始,兼顾Pytorch学习, 如果刚刚接触深度学习并且想快速搭建神经网络完成任务享受快感,当然是Keras框架首选,但是如果想在深度学习或人工智能这条路上走的更远,只有Keras就显得有点独木难支,这时候我们需要一个更加强大的框架,这里我想学习Pytorch,它代码通俗易懂,接近Python原生,学起来也容易一些,所以接下来会整理自己在快速入门Pytorch道路上的所见所得,这个系列会有8篇理论+实战的文章,也是我正在学习的B站上的Pytorch入门实战课程,我会把学习过程的笔记和所思所想整理下来,也希望能帮助更多的人进军Pytorch。想要快速学习Pytorch,最好的秘诀就是手握官方文档,然后不断的实战加反思。
如果想真正的理解知识,那么最好的方式就是用自己的话再去描述一遍, 通过这个系列,我相信能够打开Pytorch的大门,去眺望一个新的世界。
今天是本系列课程的第六节课, 快要接近尾声了, 这个视频听到现在才隐约的发现, 对初学者可能并不是太友好, 因为有些知识老师都是默认我们都已经学会了, 然后就直接上代码了, 可是宝宝们是真心没有这些基础啊,所以这节课听完了之后迷迷糊糊, 所以去研究了一下老师写的代码, 跑了其中的两个实验, 这里就整理一下收获吧, 这节课主要包括两块的内容, 第一块是图片风格迁移, 这个还是挺有意思的, 给定两张图片, 一张是内容, 一张是风格, 然后让我们把内容的那张图片的风格换成后面那张图像的风格。 我这个由于没有找到他们的图片, 就自己截了两个图试了一下, 也能运行成功, 所以这个系列的这些代码其实我们都可以作为以后任务的迁移使用, 万一以后我们也需要做图片的风格迁移呢? 就可以在这次网络的基础上进行改进。 关于这个任务, 简单整理一下训练原理, 虽然这里面使用了VGG19, 但是并没有训练,而是当做了特征提取器, 所以这里又发现了一个新的知识, 就是可以拿现成的网络作为特征提取器, 而不训练网络本身。
第二块的内容是GAN, 生成对抗网络了, 这块知识如果想懂就需要先有些生成对抗的知识, 我之前整理过一篇理论和keras版本的DCGAN, 这里无非是改成了Pytorch版本, 而这次依然是两个任务,使用生成对抗网络生成手写数字和DCGAN生成人脸, 第二个任务由于数据太大, 没有跑, 把代码的逻辑过了一遍,重点还是思想吧,尤其是在卷积网络中各个数据维度的变化, 我们得要学会如果通过各种卷积或者逆卷积, 采样或者上采样等操作把一些数据从原始维度变成我们想要的维度, 这个在以后自己搭建神经网络的时候非常重要。 所以这次的任务就可以帮助到我们分析维度和学习这些操作。收获就是看了一个DCGAN的Pytorch版本, 并加深了对网络的进一步理解。 虽然生成对抗现在不知道应该怎么用到别的任务上, 但只要有机会, 还是学学吧, 万一以后用到呢? 哈哈。
大纲如下:
- 图片风格迁移
- GAN(生成对抗)
- DCGAN
Ok, let’s go!
2. 图片风格迁移
这块我们先从任务出发, 结合一张图片的内容和另一张图片的风格, 生成一张新的图片:

图片风格迁移的论文https://arxiv.org/pdf/1508.06576.pdf, 感兴趣的可以看一下, 由于这里是实战课, 所以直接分析一下这种应该怎么做, 简单说一下思想哈, 也就是下面代码的一个过程, 首先我们会有两张图片(这两张图片是真正用的截图工具截的), 左边的叫做content, 中间的叫做style, 我们要做一个这样的事情, 就是生成一张新图片, 这张图片呢, 既有左边图片的内容, 也有中间图片的风格, 就是右边的这个图片。
那么怎么才能做这个事情呢? 这里是这样做的, 首先先拷贝一张和左边图像一样的图片, 这样就保证了内容, 但是我们知道图片是像素组成的, 而像素就是三维张量嘛? 我们首先把这张图片经过神经网络之后, 把内容特征提取出来, 然后分别与内容图片和风格图片产生一种差异上的损失,从而来更新这个张量, 注意这里不是更新网络的参数了, 网络在这里作为了一个特征提取器, 我们更新的参数是这张图片的像素值, 经过多少轮之后, 就会发现, 这个张量就会既有左边图像的内容, 也有中间图像的风格, 神不神奇? 有了这个过程, 下面的代码理解起来就比较好理解了。
下面开始写代码:第一步依然是导入所有的包:
from __future__ import division
from torchvision import models
from torchvision import transforms
from PIL import Image
import argparse
import torch
import torchvision
import torch.nn as nn
import numpy as np
import torchvision.utils as vutils
import matplotlib.pyplot as plt
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
这里又使用了torchvision这个工具包, 这个包在处理图像的时候非常重要, 这里面封装好了对图像的一系列预处理操作和一些模型, 在torchvision中,有三个主要的模块:
torchvision.transforms: 常用的图像预处理方法, 比如标准化,中心化,旋转,翻转等操作trochvision.datasets:常用的数据集的dataset实现, MNIST, CIFAR-10, ImageNet等torchvision.models: 常用的模型预训练, AlexNet, VGG, ResNet, GoogLeNet等。
这里我们好像都用到了,关于各种图像的预处理方法, 我之前的博客里面有总结, 这里就不多说了, 我们下一步就是导入数据集, 这里在课堂上产生了一个疑问, 就是两张图片维度并不是一致的, 但看代码好像是一致的啊, 这次也搞明白了原因:
def load_image(image_path, transform=None, max_size=None, shape=None):
image = Image.open(image_path) # 读入图片, 下面是一些图片的预处理操作
if max_size:
scale = max_size / max(image.size)
size= np.array(image.size) * scale
#print(size) [400. 306.78733032]
image = image.resize(size.astype(int), Image.ANTIALIAS) # 改变图片大小
if shape:
image = image.resize(shape, Image.LANCZOS) # Image.LANCZOS是插值的一种方式
if transform:
#print(image) # PIL的JpegImageFile格式(size=(W,H))
image = transform(image).unsqueeze(0)
#print(image.shape) # [C, H, W]
return image.to(device)
transform = transforms.Compose([
transforms.ToTensor(), #将numpy数组或PIL.Image读的图片转换成(C,H, W)的Tensor格式且/255归一化到[0,1.0]之间
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]) # 来自ImageNet的mean和variance
content = load_image("1.png", transform, max_size=400)
style = load_image("2.png", transform, shape=[content.size(2), content.size(3)])
print(content.shape, style.shape) # torch.Size([1, 3, 306, 400]) torch.Size([1, 3, 400, 306])
这行代码里面的最后我们看两张图片的shape, 会发现后面的两维是转置的关系, 这个要注意, 一开始疑问就是明明上面style那行代码设置的shape是content的第2维和第3维啊, 怎么真实情况变了? 这里我调试了一下, 发现问题出现在了transformes.ToTensor()和PIL.Image上, load_image函数里面用的是Image读取的图片, 这个格式是PTL.Image格式的,这个是size=(W, H), 也就是宽度在前, 高度在后, 而经过了ToTensor()之后, 是(C, H, W)的三维张量, 高度在前宽度在后了, 所以才会有后面这两张图片的转置关系, 当然这个的输入也正是这样的, 并不是出现了错误。
当然我们也可以看一下归一化之后的这两张图片长啥样子:
unloader = transforms.ToPILImage() # reconvert into PIL image
plt.ion()
def imshow(tensor, title=None):
image = tensor.cpu().clone() # we clone the tensor to not do changes on it
image = image.squeeze(0) # remove the fake batch dimension
image = unloader(image)
plt.imshow(image)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
plt.figure()
imshow(style[0], title='Style')
imshow(content[0], title='Image')
结果如下:
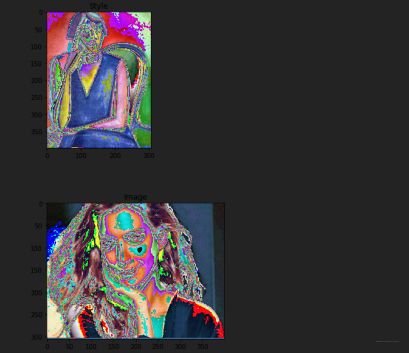
哈哈, 已经变得和鬼一样了,但是没办法, 人家神经网络喜欢呐。 下面我们就迁移一个VGG神经网络来作为特征提取器, 提取图片的内容:
class VGGNet(nn.Module):
def __init__(self):
super(VGGNet, self).__init__()
self.select = ['0', '5', '10', '19', '28'] # 这个地方是选择vgg19的某些层出来
self.vgg = models.vgg19(pretrained=True).features # 这个地方是拿出vgg19的前面部分, 后面的分类器舍弃掉
def forward(self, x):
features = []
for name, layer in self.vgg._modules.items():
x = layer(x)
if name in self.select:
features.append(x)
return features
target = content.clone().requires_grad_(True)
optimizer = torch.optim.Adam([target], lr=0.003, betas=[0.5, 0.999])
vgg = VGGNet().to(device).eval() # 注意, 这个VGG已经是不训练状态了
这里的重点就是target就是我们最终的目标, 而初始化就是content的复制, 只不过requires_grad设置为了true, 就是可训练, 而下面的优化器的目标正是target,而不是model.parameters()了, 这是第一次见这种写法。 上面网络的搭建部分, 是直接用了Vgg19网络, 但是把分类器给舍弃掉了, 如果仔细看看Vgg19的源码的话,整个网络是分为两个部分的, 一个features, 是特征提取部分, 另一部分是分类部分, 好多经典网络都是这么写的。 这里只用前者即可, 并且只选择了某些层出来。
我们下面就看看这个target经过vgg之后, 提取到了什么东西:
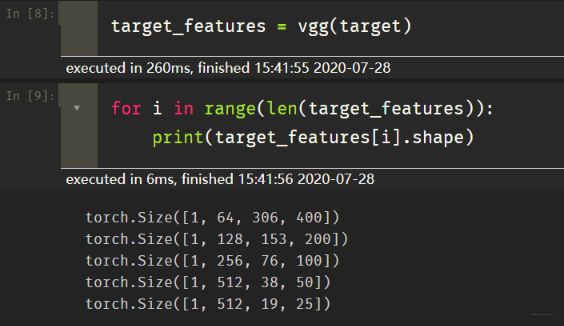
会发现, 经过那五层之后, 会提取到五个张量, 大小是上面那样子, 接下来就是训练了。
训练是这样的思路, 我们分别让contet, target, style经过vgg网络就都会得到上面的5个张量, 这也就是他们各自的特征, 然后我们对于每一层的特征, 我们就会计算损失, 损失函数是PPT上直接给出的,

所以这里写代码的时候, 就按照这个损失函数进行的计算, 有了损失, 优化器就可以更新target的张量内容了, 训练代码如下:
total_step = 2000
style_weight = 100.
for step in range(total_step):
target_features = vgg(target)
content_features = vgg(content)
style_features = vgg(style)
style_loss = 0
content_loss = 0
for f1, f2, f3 in zip(target_features, content_features, style_features): # 对于每一层特征, 下面开始计算损失
content_loss += torch.mean((f1-f2)**2) # 内容损失
_, c, h, w = f1.size() # [c, h, w]
f1 = f1.view(c, h*w) #[c, h*w]
f3 = f3.view(c, h*w) # [c, h*w]
# 计算gram matrix
f1 = torch.mm(f1, f1.t()) # [c, c]
f3 = torch.mm(f3, f3.t()) # [c, c]
style_loss += torch.mean((f1-f3)**2)/(c*h*w) # 风格损失
loss = content_loss + style_weight * style_loss # 总的损失
# 更新target
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 10 == 0:
print("Step [{}/{}], Content Loss: {:.4f}, Style Loss: {:.4f}"
.format(step, total_step, content_loss.item(), style_loss.item()))
训练过程这里就不用看了,如果训练正常,应该是内容损失会越来越大, 风格损失会越来越小, 下面看一下最后结果:
denorm = transforms.Normalize((-2.12, -2.04, -1.80), (4.37, 4.46, 4.44)) # 反归一化
img = target.clone().squeeze()
img = denorm(img).clamp_(0, 1) # 控制到0-1
plt.figure()
imshow(img, title='Target Image')
结果如下:

所以效果还是不错的, 这个可以换成自己的图片玩一玩哈哈。 主要是图片风格迁移的原理和训练过程要明白, 不训练网络本身, 而是在训练目标图片
3. 生成对抗网络
关于生成对抗网络, 这里需要有一些先修内容, 你真的了解生成式对抗网络GAN的工作原理吗?(白话+数学公式推导)先修知识已经放这里了, 看懂了理论之后, 才能明白下面究竟在干啥。
简单的说一下生成对抗的原理哈, 这其实就是通过生成器和判别器的互相较量而让彼此互相变强的故事。 一开始呢, 我是有一个弱智生成器, 一个弱智判别器, 生成器负责生成图片, 判别器负责判断生成器生成图片的真假, 这两个其实都是神经网络, 训练过程和之前的一样, 只不过是两个在互相训练而已。 判别器就是一个二分类的网络, 负责判断给定给定的图片是真的还是假的, 所以训练判别器的时候, 是先用一批真实的图片进行训练, 然后当生成器生成的假图片来了之后,我们就希望判别器立刻认出来是假的。 这样第一次迭代之后就可以训练出一个不错的判别器来。至少当前生成器生成的图片我都能看出是假的来了。
生成器说, 那不行啊, 判别器那小子在进化, 我如果不努力就没有退路了, 现在的伪装让他一眼就拆穿了呀, 于是乎, 生成器也开始训练, 他的目标就是让判别器看不出是假的来, 怎么看不出来? 那就用真实的标签进行计算损失啊, 这样训练出来之后, 当前的判别器就没法认出生成器的图片来了, 起到了以假乱真的效果, 所以第一个epoch之后, 判别器和生成器都进行了一个进化。 这样进行若干个epoch, 就会训练出一个比较不错的生成器来搞事情了。
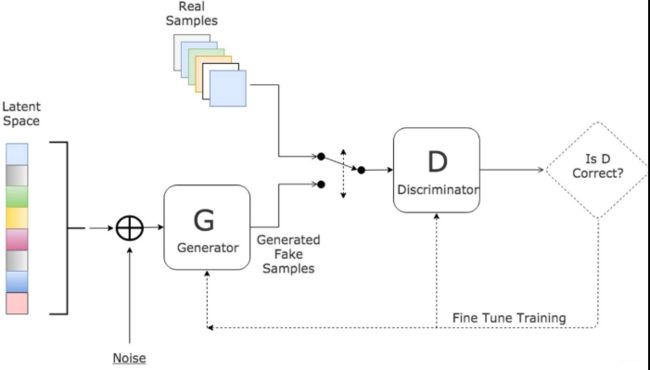
原理差不多就是这样, 其实挺简单的这个东西, 下面看看代码会更能看出互相较量的感觉, 我们先搭建两个神经网络来作为生成器和鉴别器吧:
image_size = 784 # 手写数字识别的大小
hidden_size = 256
# 判别器 作用是识别图片的真假(是否是手写数字图片) 这里其实用的全连接网络做的
D = nn.Sequential(
nn.Linear(image_size, hidden_size),
nn.LeakyReLU(0.2),
nn.Linear(hidden_size, hidden_size),
nn.LeakyReLU(0.2),
nn.Linear(hidden_size, 1),
nn.Sigmoid()
)
latent_size = 64
# 生成器(负责生成假的图片) 也是一个全连接神经网络
G = nn.Sequential(
nn.Linear(latent_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, image_size),
nn.Tanh()
)
D = D.to(device)
G = G.to(device)
loss_fn = nn.BCELoss()
d_optimizer = torch.optim.Adam(D.parameters(), lr=0.0002)
g_optimizer = torch.optim.Adam(G.parameters(), lr=0.0002)
两个生成器就是两个神经网络,并且及其普通, 没有什么神秘的, 有了这个, 我们还要导入数据, 数据这里用的就是torchvision.dataset里面的手写数字识别数据集:
batch_size=32
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.5),
std=(0.5))
])
mnist_data = torchvision.datasets.MNIST("./mnist_data", train=True, download=True, transform=transform)
dataloader = torch.utils.data.DataLoader(dataset=mnist_data,
batch_size=batch_size,
shuffle=True)
这里重点看一下图像的输入如何进行预处理的。
看一下大小和图片:
next(iter(dataloader))[0].shape # 这个0维表示的是image, 1维表示的是类别 torch.Size([32, 1, 28, 28])
plt.imshow(next(iter(dataloader))[0][3][0], cmap=plt.cm.gray) # cmap控制显示的颜色
结果:

这个已经是很熟悉了吧, 有了数据, 下面就可以进行网络的训练过程: 具体的都写上注释了, 再结合原理, 应该很好理解
def reset_grad(): # 这里是梯度清零操作
d_optimizer.zero_grad()
g_optimizer.zero_grad()
total_step = len(dataloader)
num_epochs = 50
for epoch in range(num_epochs):
for i, (images, _) in enumerate(dataloader): # _代表的是图片的真实类别, 但是我们这里不需要, 只需要判别器判别真假即可
batch_size = images.size(0) # 32
images = images.reshape(batch_size, image_size).to(device) # [32, 28, 28]
real_labels = torch.ones(batch_size, 1).to(device) # 真实的labels
fake_labels = torch.zeros(batch_size, 1).to(device) # 假的labels
outputs = D(images) # 判别器先用真实的图片进行训练
d_loss_real = loss_fn(outputs, real_labels) # 求损失
real_score = outputs # outpus会是0-1之间的数字, 我们希望判别器能够判断出这是真实数字来,所以对于D来说,分数越大越好
# 开始生成fake images
z = torch.randn(batch_size, latent_size).to(device) # 开始随机生成一些像素
fake_images = G(z) # 通过这个就会生成一张图片, 接下来就是用生成器进行判别
outputs = D(fake_images.detach()) # 把生成器生成的图片从计算图上摘下来
d_loss_fake = loss_fn(outputs, fake_labels)
fake_score = outputs # 对于D来说, 这个分数越小越好, 因为这个是假的, 生成器目标就是识别为0
# 开始优化discriminator
d_loss = d_loss_real + d_loss_fake
reset_grad()
d_loss.backward()
d_optimizer.step()
# 开始优化generator 这个优化的目标就是尽可能的让生成器生成更真实的图片, 至少让当前这一代的判别器看不出来
z = torch.randn(batch_size, latent_size).to(device) # 随机生成图片
fake_images = G(z)
outputs = D(fake_images) # 判别器进行辨认
g_loss = loss_fn(outputs, real_labels) # 所以这是生成器的损失, 判别器判别了之后, 想办法让它看成是真的
reset_grad()
g_loss.backward()
g_optimizer.step()
if i % 1000 == 0:
print("Epoch [{}/{}], Step [{}/{}], d_loss: {:.4f}, g_loss: {:.4f}, D(x): {:.2f}, D(G(z)): {:.2f}"
.format(epoch, num_epochs, i, total_step, d_loss.item(), g_loss.item(), real_score.mean().item(), fake_score.mean().item()))
这个最后的效果是这样:
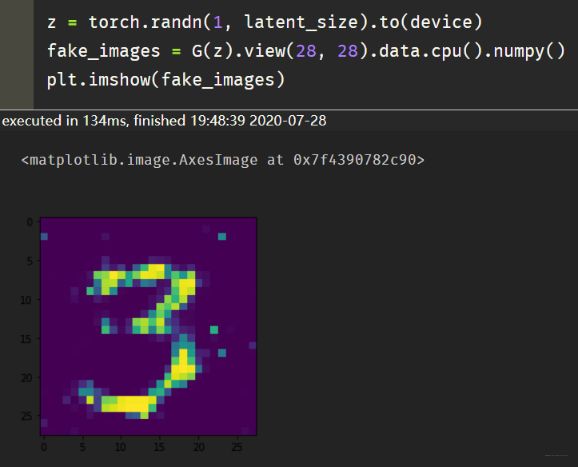
并且这个只训练了50次, 而真实图片张这样:

感觉效果还是可以的。 这里就是又复习了一遍GAN的工作原理, 并基于Pytorch实现了一个简化版本的GAN。
4. DCGAN
关于DGCAN的详细内容, 可以看论文UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS, 既然也是GAN, 所以训练过程和上面基本上是一样的, 无非就是神经网络的架构不像上面那么简单了, 这里用了卷积的一些操作, 生成器里面用到了逆卷积的一些操作。 这里的关键就是弄清楚网络每一步操作之后的数据的维度变化, 尤其是生成器那里, 最终的输出一定要和真实图片的大小对应起来, 这时候判别器才能够进行分类。
下面简单的介绍代码的逻辑过程, 得明白到底再干一个什么样的事情, 这时候再读代码就比较好懂了, 首先是数据部分, 这次用的数据集来自这个网站:图片下载地址, 这是一些人脸的图像, 张下面这样:

大小是[3, 64, 64]的, 所以我们的生成器最终生成的图片就是这么大。看一下生成器结构吧:
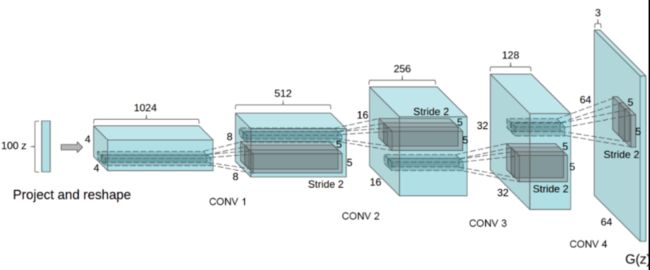
生成器的输入是[100, 1, 1]的一个张量, 我们需要通过一系列的逆卷积操作, 把它变成最后的[3, 64, 64]., 所以待会的代码就是在实现这么一个结构, 不过每一层通道数改了一下, 变成了[512, 256, 128, 64], 其他的没变。 然后就是判别器的定义, 判别器这里也是用了卷积操作, 想办法从输入的[3, 64, 64]通过一些了卷积变成了[1, 1, 1], 然后sigmoid就可以进行二分类了。 有了这个, 训练方式和上面的GAN差不多。 所以这里我们要重点关注的就是这些维度的变化, 究竟什么操作可以使维度进行这样的变化, 这个对以后自己搭建网络的时候有很关键的作用。
好了, 有了上面的过程, 下面的代码理解就很容易了, 首先依然是把图片构建成DataLoader:
image_size=64
batch_size=128
dataroot="celeba/img_align_celeba"
num_workers = 2
dataset = torchvision.datasets.ImageFolder(root=dataroot, transform=transforms.Compose([
transforms.Resize(image_size),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]))
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers)
这个代码读入的过程基本和上面一致, 套路就是ImageFolder里面实现dataset, 当然可以进行一些预处理操作。 然后就是转成DataLoader。
下面就是网络的搭建, 但是在搭建之前, 我们要定义一个权重初始化的函数:这个也是一种技巧吧, 好的参数初始化方式不仅能保证训练快速, 还可以减少一些意外情况的发生:
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1: # 卷积层的参数初始化
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1: # BatchNorm的参数初始化
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
下面搭建网络, 生成器网络结构就是上面那个, 我在这个过程中详细标注了维度的变化:
nz = 100 # latent vector的大小
ngf = 64 # generator feature map size
ndf = 64 # discriminator feature map size
nc = 3 # color channels
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.main = nn.Sequential(
# input is Z, going into a convolution
# torch.nn.ConvTranspose2d(in_channels, out_channels,
# kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1)
# 输入是[100, 1, 1]
# 卷积逆操作 (In-1) * stride + kernel_size - 2*padding = Out
# 卷积操作 Out = (In+2*padding-kernel_size) / stride + 1
nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False), # 0+4 = 4 [ngf*8, 4, 4]
nn.BatchNorm2d(ngf * 8), # [ngf*8, 4, 4]
nn.ReLU(True), # [ngf*8, 4, 4]
# state size. (ngf*8) x 4 x 4
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False), # (4-1)*2+4-2=8 [ngf*4, 8, 8]
nn.BatchNorm2d(ngf * 4), # [ngf*4, 8, 8]
nn.ReLU(True), # [ngf*4, 8, 8]
# state size. (ngf*4) x 8 x 8
nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False), # (8-1)*2+4-2 = 16
nn.BatchNorm2d(ngf * 2), # [ngf*2, 16, 16]
nn.ReLU(True),
# state size. (ngf*2) x 16 x 16
nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False), # (16-1)*2+4-2 = 32
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# state size. (ngf) x 32 x 32
nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False), # (3, 64, 64)
nn.Tanh()
# state size. (nc) x 64 x 64 这个一定要和真实图片大小对应起来
)
def forward(self, input):
return self.main(input)
# Create the generator
netG = Generator().to(device)
# Apply the weights_init function to randomly initialize all weights
# to mean=0, stdev=0.2.
netG.apply(weights_init)
# Print the model
print(netG)
接下来是判别器:
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
# input is (nc) x 64 x 64
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False), # [ndf, 32, 32]
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False), # [ndf*2, 16, 16]
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False), # [ndf*4, 8, 8]
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False), # [ndf*8, 4, 4]
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*8) x 4 x 4
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False), # [1, 1, 1]
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
# Create the Discriminator
netD = Discriminator().to(device)
# Apply the weights_init function to randomly initialize all weights
# to mean=0, stdev=0.2.
netD.apply(weights_init)
# Print the model
print(netD)
这两个里面很值得借鉴的就是应该定义哪些层才会使得维度发生变化, 这个很重要, 每个层之后数据到底怎么变了。下面的训练过程比较简单了:首先是基本配置
lr = 0.0002
beta1 = 0.5
loss_fn = nn.BCELoss()
fixed_noise = torch.randn(64, nz, 1, 1, device=device) # 生成图片过程中加了一点噪声
d_optimizer = torch.optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999))
g_optimizer = torch.optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))
然后是训练过程:
num_epochs = 5
G_losses = []
D_losses = []
for epoch in range(num_epochs):
for i, data in enumerate(dataloader):
# 训练discriminator, maximize log(D(x)) + log(1-D(G(z)))
# 首先训练真实图片
netD.zero_grad()
real_images = data[0].to(device)
b_size = real_images.size(0)
label = torch.ones(b_size).to(device) # 真图片的标签是1
output = netD(real_images).view(-1) # 判别器学习真的图片
real_loss = loss_fn(output, label)
real_loss.backward()
D_x = output.mean().item()
# 然后训练生成的假图片
noise = torch.randn(b_size, nz, 1, 1, device=device)
fake_images = netG(noise) # 生成了假的图片
label.fill_(0) # 假的图片标签是0
output = netD(fake_images.detach()).view(-1)
fake_loss = loss_fn(output, label) # 判别器判断假的图片
fake_loss.backward()
D_G_z1 = output.mean().item()
loss_D = real_loss + fake_loss # 这两个损失加起来才是判别器的损失, 能够正确的辨识真假
d_optimizer.step()
# 训练Generator
netG.zero_grad()
label.fill_(1) # 这里就是把假图片的标签弄成1,判别器进行判别, 从而进化生成器
output = netD(fake_images).view(-1)
loss_G = loss_fn(output, label)
loss_G.backward()
D_G_z2 = output.mean().item()
g_optimizer.step()
if i % 50 == 0:
print("[{}/{}] [{}/{}] Loss_D: {:.4f} Loss_G {:.4f} D(x): {:.4f} D(G(z)): {:.4f}/{:.4f}"
.format(epoch, num_epochs, i, len(dataloader), loss_D.item(), loss_G.item(), D_x, D_G_z1, D_G_z2))
G_losses.append(loss_G.item())
D_losses.append(loss_D.item())
这一块主要也是GAN的训练过程了, 所以不再过多赘述。 其实,之前用keras实现了一个这样的版本, 也放在这里吧, 深度学习框架之Keras感知:快速搭建生成对抗网络(GAN)生成自己想要的图片, 也是DCGAN,所以巧了,如果不会Pytorch, 依然可以实现这个网络来完成自己的一些任务, 而GAN一般在图像生成方面用的多一些。下面看看最终的训练效果:

左边是真实图片, 右边是神经网络生成的图片, 虽然有几个看起来可怕, 但总体效果看起来还是不错的, 像个人吧。有了GAN之后, 就可以多生成一些数据了, 不用再担心图片不够了哈哈。
5. 总结
下面简单总结一下这节课的内容, 这节课围绕着图像进行展开, 做了两个任务, 一个是图片风格迁移, 在这个任务里面看到了网络作为提取器的作用, 而训练过程只是在更新图片的参数, 揭开了图片风格迁移的神秘面纱, 第二个任务是GAN, 有了GAN, 就可以生成一些图片来帮助自己任务的完成, 先是搭建了一个简单的GAN网络进行手写数字识别的生成, 然后是用Pytorch实现了DCGAN生成了一些人脸图片。 这里面重点学到的是卷积和逆卷积的维度操作, 也加深了对GAN的细节了解。 还学到了对神经网络某些层参数进行初始化的技巧。
所以这节课收获还是蛮大的, 后面还有两节课, 又回到了NLP上面去, 是讲机器翻译和对话系统的, 主要会通过Pytorch实现seq2seq+Attention的网络机制, 这个还是非常有用的, 继续Rush
本节课的代码链接:https://github.com/zhongqiangwu960812/DeepLearningProjects/tree/master/PytorchCourse