(含源码)「自然语言处理(NLP)」Question Answering(QA)论文整理(五)
来源: AINLPer 微信公众号(每日更新…)
编辑: ShuYini
校稿: ShuYini
时间: 2020-07-21
引言: 本次整理的论文还是主要偏向于Open-Domain QA,其中主要涉及到增强Ranker-Reader、SearchQA的大型数据集、PullNet集成框架、改进的加权抽样训练策略、开放QA中的Bert模型优化等。
本次论文获取方式:
1、关注AINLPer 微信公众号(每日更新…)回复:QA005
2、知乎主页–ShuYini
1、TILE: Evidence Aggregation for Answer Re-Ranking in Open-Domain Question Answering
Author: Shuohang Wang , Mo Yu , Jing Jiang , Wei Zhang
Paper: https://arxiv.org/pdf/1711.05116v2.pdf
Code: https://github.com/shuohangwang/mprc
论文简述: 在这篇论文中,提出了两个利用多篇文章来产生答案的模型。两者都使用了一种答案重新排序的方法,该方法重新排序由现有的最先进的QA模型生成候选答案。本文提出了两种方法,即基于强度的重新排序和基于覆盖的重新排序,以利用来自不同文章的汇总证据来更好地确定答案。本文模型在三个公开的开放域QA数据集:Quasar-T、SearchQA和TriviaQA的开放域版本上取得了最先进的结果


2、TILE: R 3 R^3 R3: Reinforced Reader-Ranker for Open-Domain Question Answering
Author: Shuohang Wang , Mo Yu , Xiaoxiao Guo , Zhiguo Wang , Tim Klinger
Paper: https://arxiv.org/pdf/1709.00023v2.pdf
Code: https://github.com/shuohangwang/mprc
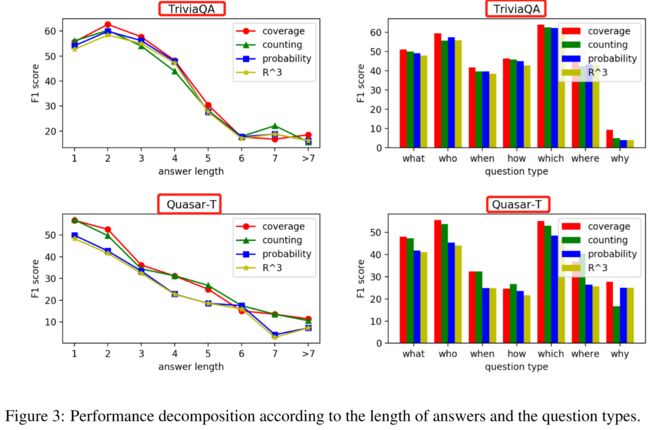
论文简述: 本文提出了一种基于两种算法创新的新型开放域质量保证系统——增强Ranker-Reader。文中首先提出了一个带有排名组件的开放域QA新管道,该组件根据生成给定问题的基本真实答案的可能性对检索到的文章进行排名。其次,提出了一种基于强化学习的排序器与答案生成阅读者模型联合训练的新方法。实验结果,本文方法显著地改善了多个开放域QA数据集的现状。



3、TILE: SearchQA: A New Q&A Dataset Augmented with Context from a Search Engine
Author: Matthew Dunn , Levent Sagun , Mike Higgins , V. Ugur Guney , Volkan Cirik , Kyunghyun Cho
Paper: https://arxiv.org/pdf/1704.05179v3.pdf
Code: https://github.com/nyu-dl/SearchQA
论文简述: 本文公开发布了一个名为SearchQA的大型数据集,用于机器理解或问答。它由超过140k个问题-答案对组成,每个对平均有49.6个片段。SearchQA的每个问答上下文元组都带有额外的元数据。我们在SearchQA上进行人工评估,并测试了两种基本方法,一种是简单的单词选择,另一种是基于深度学习的。
4、TILE: Reading Wikipedia to Answer Open-Domain Questions
Author: Danqi Chen , Adam Fisch , Jason Weston , Antoine Bordes
Paper: https://arxiv.org/pdf/1704.00051v2.pdf
Code: https://github.com/facebookresearch/ParlAI
论文简述: 本文提出利用维基百科作为唯一的知识来源来解决开放领域的问题:任何事实性问题的答案都是维基百科文章的一个文本范围。大规模机器阅读的任务结合了文档检索(查找相关文章)和机器理解文本(从这些文章中识别答案)的挑战。我们的方法结合了一个基于二元哈希和TF-IDF匹配的搜索组件和一个多层递归神经网络模型,该模型训练用来检测维基百科段落中的答案。


5、TILE: PullNet: Open Domain Question Answering with Iterative Retrieval on Knowledge Bases and Text
Author: Haitian Sun , Tania Bedrax-Weiss , William Cohen
Paper: https://www.aclweb.org/anthology/D19-1242.pdf
Code: None
论文简述: 本文PullNet是一个集成的框架,用于(1)学习检索以及(2)利用异构信息进行推理以找到最佳答案。PullNet使用一个{迭代}过程来构造一个包含与问题相关信息的特定于问题的子图。在每个迭代中,使用一个graph convolutional network (graph CNN)来识别子图节点,这些子图节点通过对语料库和/或知识库进行检索操作来展开。子图完成后,使用另一个图CNN从子图中提取答案。这个检索和推理过程允许我们使用大型KBs和语料库回答多跳问题。



6、TILE: Ranking and Sampling in Open-Domain Question Answering
Author: Yanfu Xu , Zheng Lin , Yuanxin Liu , Rui Liu , Weiping Wang , Dan Meng
Paper: https://www.aclweb.org/anthology/D19-1245.pdf
Code: None
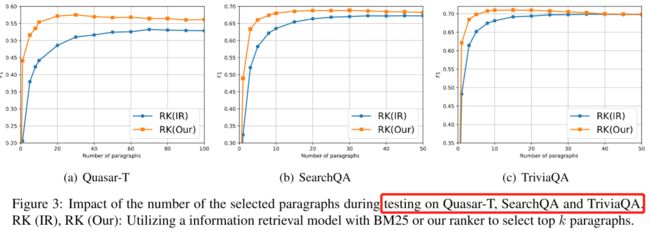
论文简述: 在本文首先介绍了一个利用分段-问题和分段-段落相关性来计算每个段落的置信度的排序模型。在此基础上,我们设计了一种改进的加权抽样训练策略,以减少噪声和干扰段落的影响。在三个公共数据集(Quasar-T、SearchQA和TriviaQA)上进行的实验表明了本文模型的优势。



7、TILE: Language Models as Knowledge Bases?
Author: Fabio Petroni , Tim Rocktschel , Sebastian Riedel , Patrick Lewis , Anton Bakhtin
Paper: https://www.aclweb.org/anthology/D19-1250.pdf
Code: https://github.com/facebookresearch/LAMA
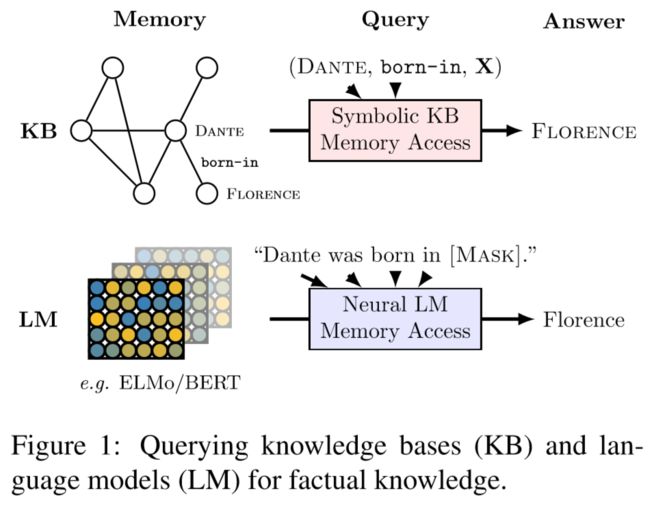
论文简述: 本文深入分析了在一系列最先进的预训练语言模型中已经存在(没有微调)的关系知识。我们发现:(1)在没有微调的情况下,BERT相比于传统的NLP方法包含了相关知识,但是传统NLP方法可以访问知识库;(2)BERT在基于监督基线的开放域问题回答方面也做得非常好,(iii)通过标准语言模型的预训练方法,某些类型的事实知识比其他类型的知识更容易学习。这些模型在不进行任何微调的情况下调用事实知识的能力表现出惊人地优势,这表明它们作为无监督的开放域QA系统的潜力。

8、TILE: Multi-passage BERT: A Globally Normalized BERT Model for Open-domain Question Answering
Author: Zhiguo Wang , Patrick Ng , Xiaofei Ma , Ramesh Nallapati , Bing Xiang
Paper: https://www.aclweb.org/anthology/D19-1599.pdf
Code: None
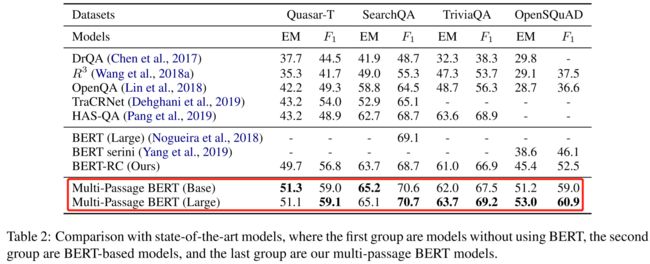
论文简述: BERT模型已成功地应用于开放域QA任务。然而,以往的工作是通过观察与独立训练实例相同的问题对应的段落来训练BERT,这可能会导致不同段落的答案得分存在不可比性。为了解决这个问题,本文提出了一个多通道的BERT模型来对同一问题的所有段落的答案得分进行全局标准化,这种变化使得我们的QA模型能够通过使用更多的段落找到更好的答案。此外,我们还发现,通过滑动窗口将文章拆分成100字的段落,可以将性能提高4%。通过利用一个通道ranker来选择高质量的通道,多通道BERT获得额外的2%提高。

Attention
更多自然语言处理相关知识,还请关注 AINLPer公众号,极品干货即刻送达。