第一部分:视频学习心得
1.1绪论
人对人工智能的想象,最终是一个类人的机器人,也就是说人工智能最终会应用到机器人身上。
人工智能发展阶段

人工智能的目标是让机器能像人一样思考、感知,机器学习是实现这一目标的一种方法,深度学习又是这一类方法中更小的一个点。

图灵奖:它是一个专门奖励对计算机事业作出重要贡献的个人的奖项,是计算机界最负盛名、最崇高的一个奖项,有“计算机界的诺贝尔奖”之称,其名称取自计算机科学的先驱、英国科学家艾伦·麦席森·图灵(Alan M. Turing)。

人工智能有三个层面:计算智能、感知智能和认知智能。
人工智能的方式:逻辑演绎、归纳总结。
知识工程VS机器学习:知识工程因为是由专家团队来设计规则,所以结果容易解释,但是难保证一致性、准确性;机器学习准确率高,但结果不容易解释。

1.2深度学习概述
深度学习尚处于“鹦鹉智能”阶段
深度学习的“不能”
·算法输出不稳定,容易被“攻击”。
·模型复杂度高,难以纠错和调试。
·模型层级复合程度高,参数不透明。
·端到端训练方式对数据依赖性强,模型增量性差。
·专注直观感知类问题,对开放性推理问题无能为力。
·人类知识无法有效引入进行监督,机器偏见难以避免。

M-P神经元
它是按照生物神经元的结构和工作原理构造出来的一个抽象和简化了的模型,实际上就是对单个神经元的一种建模。

激活函数的用途:
没有激活函数相当于矩阵相乘,只能拟合线性函数,激活函数f的存在可以使神经网络有非线性拟合能力。

修正线性单元ReLU函数 relu(z)= max(0,z)可以解决饱和区问题
单层感知器——首个可以学习的人工神经网络
单层感知器只能解决线性问题(线性分类),解决不了非线性分类(如异或XOR逻辑)问题。
可以将复杂的逻辑单元转化成简单的逻辑单元组合来解决,比如单层感知器能实现与或非逻辑,将这些与或非组合起来就可以构成多层感知器,即线性分类任务组合后可以解决非线性分类任务。可以理解为第一层感知器其实是做了一个空间变换,从变换之后的空间角度看就是线性可分的问题了。
隐层
无隐层——不能解决非线性分类问题,如异或。
单隐层——可解决非线性分类问题,但分界面仍是连续的。
双隐层——分界面可任意形状,复杂度由单元数目确定。
如果一个隐层包含足够多的神经元,三层前馈神经网络(输入-隐层-输出)能以任意精度逼近任意预定的连续函数。此为万有逼近定理。
神经网络
就是利用矩阵的线性变换和激活函数的非线性变换,将原始输入空间的非线性分类问题转化到线性可分的空间里,所以神经网络最后一层用一个简单的线性分类器就可以解决了。
增加层数——增加激活函数的次数,即增加非线性转换次数。
增加节点数——增加维度,即增加线性转换能力。
“瘦高”? “矮胖”?
在神经元总数相当的情况下,增加网络深度比增加宽度能带来更强的网络表示能力、更高的准确率。所以,“瘦高”√,“矮胖”× 。
神经网络的参数学习:误差反向传播

深层神经网络的问题:梯度消失
即误差在反向传播过程中出现消失的情况。
梯度
多元函数f(x,y)在每个节点都可以有多个方向。
每个方向都可计算导数,称为方向导数。
梯度是一个向量,方向是最大方向导数的方向;模为最大方向导数的值。
误差通过梯度传播,利用这个回传的误差更新这个神经元。

出现梯度消失的情况时,虽然最后几层可以做一个更新,但是这样一种损失传递到最前面可能已经看不到了,可以忽略了,这就造成前面几层的参数基本上没有变化,只是最后几层有变化。虽然最后一层的参数变了,但是从前边传递过来的输入仍然是一个非常混乱的输入,也就是说上一次的训练是没有帮助的,再训练下去也不会有进一步的改善。可通过预训练加微调、更换激活函数等方式来解决梯度消失的问题。
1.3PyTorch基础
PyTorch是一个python优先的深度学习框架,主要提供以下两个高级功能:
·GPU加速的张量计算(Tensor Computation)功能
·构建在反向自动求导系统上的深度神经网络功能
如何利用PyTorch完成实验
·加载数据
·构建模型
·计算损失
·参数优化
第二部分:代码练习
2.1图像处理基本练习
1.下载并显示图像
!wget https://raw.githubusercontent.com/summitgao/ImageGallery/master/yeast_colony_array.jpg
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
import skimage
from skimage import data
from skimage import io
colony = io.imread('yeast_colony_array.jpg')
print(type(colony))
print(colony.shape)

plt.subplot(121)
plt.imshow(colony[:,:,:])
plt.title('3-channel image')
plt.axis('off')
# Plot one channel only
plt.subplot(122)
plt.imshow(colony[:,:,0])
plt.title('1-channel image')
plt.axis('off');

2.读取并改变图像像素值
# Get the pixel value at row 10, column 10 on the 10th row and 20th column
camera = data.camera()
print(camera[10, 20])
# Set a region to black
camera[30:100, 10:100] = 0
plt.imshow(camera, 'gray')

# Set the first ten lines to black
camera = data.camera()
camera[:10] = 0
plt.imshow(camera, 'gray')

# Set to "white" (255) pixels where mask is True
camera = data.camera()
mask = camera < 80
camera[mask] = 255
plt.imshow(camera, 'gray')

# Change the color for real images
cat = data.chelsea()
plt.imshow(cat)

# Set brighter pixels to red
red_cat = cat.copy()
reddish = cat[:, :, 0] > 160
red_cat[reddish] = [255, 0, 0]
plt.imshow(red_cat)
# Set brighter pixels to red
red_cat = cat.copy()
reddish = cat[:, :, 0] > 160
red_cat[reddish] = [255, 0, 0]
plt.imshow(red_cat)

# Change RGB color to BGR for openCV
BGR_cat = cat[:, :, ::-1]
plt.imshow(BGR_cat)

3.转换图像数据类型
from skimage import img_as_float, img_as_ubyte
float_cat = img_as_float(cat)
uint_cat = img_as_ubyte(float_cat)
4.显示图像直方图
img = data.camera()
plt.hist(img.ravel(), bins=256, histtype='step', color='black');

5.图像分割
# Use colony image for segmentation
colony = io.imread('yeast_colony_array.jpg')
# Plot histogram
img = skimage.color.rgb2gray(colony)
plt.hist(img.ravel(), bins=256, histtype='step', color='black');

# Use thresholding
plt.imshow(img>0.5)
```
###6.Canny算子用于边缘检测
```python
from skimage.feature import canny
from scipy import ndimage as ndi
img_edges = canny(img)
img_filled = ndi.binary_fill_holes(img_edges)
# Plot
plt.figure(figsize=(18, 12))
plt.subplot(121)
plt.imshow(img_edges, 'gray')
plt.subplot(122)
plt.imshow(img_filled, 'gray')

7.改变图像的对比度
# Load an example image
img = data.camera()
plt.imshow(img, 'gray')

from skimage import exposure
# Contrast stretching
p2, p98 = np.percentile(img, (2, 98))
img_rescale = exposure.rescale_intensity(img, in_range=(p2, p98))
plt.imshow(img_rescale, 'gray')

# Equalization
img_eq = exposure.equalize_hist(img)
plt.imshow(img_eq, 'gray')

# Adaptive Equalization
img_adapteq = exposure.equalize_adapthist(img, clip_limit=0.03)
plt.imshow(img_adapteq, 'gray')

# Display results
def plot_img_and_hist(img, axes, bins=256):
"""Plot an image along with its histogram and cumulative histogram.
"""
img = img_as_float(img)
ax_img, ax_hist = axes
ax_cdf = ax_hist.twinx()
# Display image
ax_img.imshow(img, cmap=plt.cm.gray)
ax_img.set_axis_off()
ax_img.set_adjustable('box')
# Display histogram
ax_hist.hist(img.ravel(), bins=bins, histtype='step', color='black')
ax_hist.ticklabel_format(axis='y', style='scientific', scilimits=(0, 0))
ax_hist.set_xlabel('Pixel intensity')
ax_hist.set_xlim(0, 1)
ax_hist.set_yticks([])
# Display cumulative distribution
img_cdf, bins = exposure.cumulative_distribution(img, bins)
ax_cdf.plot(bins, img_cdf, 'r')
ax_cdf.set_yticks([])
return ax_img, ax_hist, ax_cdf
fig = plt.figure(figsize=(16, 8))
axes = np.zeros((2, 4), dtype=np.object)
axes[0, 0] = fig.add_subplot(2, 4, 1)
for i in range(1, 4):
axes[0, i] = fig.add_subplot(2, 4, 1+i, sharex=axes[0,0], sharey=axes[0,0])
for i in range(0, 4):
axes[1, i] = fig.add_subplot(2, 4, 5+i)
ax_img, ax_hist, ax_cdf = plot_img_and_hist(img, axes[:, 0])
ax_img.set_title('Low contrast image')
y_min, y_max = ax_hist.get_ylim()
ax_hist.set_ylabel('Number of pixels')
ax_hist.set_yticks(np.linspace(0, y_max, 5))
ax_img, ax_hist, ax_cdf = plot_img_and_hist(img_rescale, axes[:, 1])
ax_img.set_title('Contrast stretching')
ax_img, ax_hist, ax_cdf = plot_img_and_hist(img_eq, axes[:, 2])
ax_img.set_title('Histogram equalization')
ax_img, ax_hist, ax_cdf = plot_img_and_hist(img_adapteq, axes[:, 3])
ax_img.set_title('Adaptive equalization')
ax_cdf.set_ylabel('Fraction of total intensity')
ax_cdf.set_yticks(np.linspace(0, 1, 5))
fig.tight_layout()
plt.show()

2.2pytorch基础练习
PyTorch是一个python库,它主要提供了两个高级功能:
·GPU加速的张量计算
·构建在反向自动求导系统上的深度神经网络
1.定义数据
定义数据一般用torch.tensor,tensor的意思是张量,是数字的总称
tensor支持各种类型的数据,如:
torch.float16,torch.float32, torch.float64,
torch.int8, torch.int16, torch.int32, torch.int64 等
创建tensor也有多种方法,如:zeros,rand,arrange,normal等
import torch
# 可以是一个数
x = torch.tensor(666)
print(x)
![]()
# 可以是一维数组(向量)
x = torch.tensor([1,2,3,4,5,6])
print(x)
![]()
# 可以是任意维度的数组(张量)
x = torch.ones(2,3,4)
print(x)
# 创建一个空张量
x = torch.empty(5,3)
print(x)

数据是随机的
# 创建一个随机初始化的张量
x = torch.rand(5,3)
print(x)
```
```python
# 创建一个全0的张量,里面的数据类型为 long
x = torch.zeros(5,3,dtype=torch.long)
print(x)

# 基于现有的tensor,创建一个新tensor,
# 从而可以利用原有的tensor的dtype,device,size之类的属性信息
y = x.new_ones(5,3)
#tensor new_* 方法,利用原来tensor的dtype,device
print(y)

z = torch.randn_like(x, dtype=torch.float)
# 利用原来的tensor的大小,但是重新定义了dtype
print(z)

2.定义操作
利用Tensor进行各种计算的都是Function
有基本运算、布尔运算、线性运算
# 创建一个 2x4 的tensor
m = torch.Tensor([[2, 5, 3, 7],
[4, 2, 1, 9]])
print(m.size(0), m.size(1), m.size(), sep=' -- ')
![]()
# 返回 m 中元素的数量
print(m.numel())
![]()
# 返回 第0行,第2列的数
print(m[0][2])
![]()
# 返回 第1列的全部元素
print(m[:, 1])
![]()
# 返回 第0行的全部元素
print(m[0, :])
![]()
# Create tensor of numbers from 1 to 5
# 注意这里结果是1到4,没有5
v = torch.arange(1, 5)
print(v)
![]()
# Add a random tensor of size 2x4 to m
m + torch.rand(2, 4)
![]()
# 转置,由 2x4 变为 4x2
print(m.t())
print(m.transpose(0, 1))

# returns a 1D tensor of steps equally spaced points between start=3, end=8 and steps=20
torch.linspace(3, 8, 20)

from matplotlib import pyplot as plt
# matlabplotlib 只能显示numpy类型的数据,下面展示了转换数据类型,然后显示
# randn 是生成均值为 0, 方差为 1 的随机数
# 下面是生成 1000 个随机数,并按照 100 个 bin 统计直方图
plt.hist(torch.randn(1000).numpy(), 100);
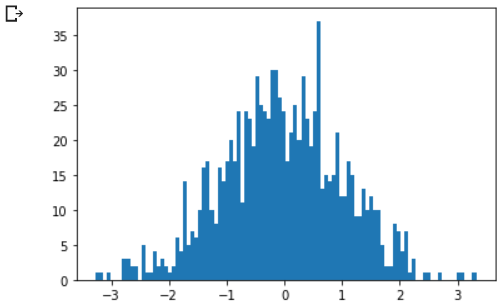
# 数据非常非常多的时候,正态分布会体现的非常明显
plt.hist(torch.randn(10**6).numpy(), 100);

```python
# 创建两个 1x4 的tensor
a = torch.Tensor([[1, 2, 3, 4]])
b = torch.Tensor([[5, 6, 7, 8]])
# 在 0 方向拼接 (即在 Y 方各上拼接), 会得到 2x4 的矩阵
print( torch.cat((a,b), 0))
![]()
# 在1方向拼接(即在 X 方各上拼接), 得到 1x8 的矩阵
print( torch.cat((a,b), 1))
![]()
2.3螺旋数据分类
!wget https://raw.githubusercontent.com/Atcold/pytorch-Deep-Learning/master/res/plot_lib.py
import random
import torch
from torch import nn, optim
import math
from IPython import display
from plot_lib import plot_data, plot_model, set_default
# 因为colab是支持GPU的,torch 将在 GPU 上运行
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('device: ', device)
# 初始化随机数种子。神经网络的参数都是随机初始化的,
# 不同的初始化参数往往会导致不同的结果,当得到比较好的结果时我们通常希望这个结果是可以复现的,
# 因此,在pytorch中,通过设置随机数种子也可以达到这个目的
seed = 12345
random.seed(seed)
torch.manual_seed(seed)
N = 1000 # 每类样本的数量
D = 2 # 每个样本的特征维度
C = 3 # 样本的类别
H = 100 # 神经网络里隐层单元的数量
![]()
X = torch.zeros(N * C, D).to(device)
Y = torch.zeros(N * C, dtype=torch.long).to(device)
for c in range(C):
index = 0
t = torch.linspace(0, 1, N) # 在[0,1]间均匀的取10000个数,赋给t
# 下面的代码不用理解太多,总之是根据公式计算出三类样本(可以构成螺旋形)
# torch.randn(N) 是得到 N 个均值为0,方差为 1 的一组随机数,注意要和 rand 区分开
inner_var = torch.linspace( (2*math.pi/C)*c, (2*math.pi/C)*(2+c), N) + torch.randn(N) * 0.2
# 每个样本的(x,y)坐标都保存在 X 里
# Y 里存储的是样本的类别,分别为 [0, 1, 2]
for ix in range(N * c, N * (c + 1)):
X[ix] = t[index] * torch.FloatTensor((math.sin(inner_var[index]), math.cos(inner_var[index])))
Y[ix] = c
index += 1
print("Shapes:")
print("X:", X.size())
print("Y:", Y.size())

# visualise the data
plot_data(X, Y)

1.构建线性模型分类
learning_rate = 1e-3
lambda_l2 = 1e-5
# nn 包用来创建线性模型
# 每一个线性模型都包含 weight 和 bias
model = nn.Sequential(
nn.Linear(D, H),
nn.Linear(H, C)
)
model.to(device) # 把模型放到GPU上
# nn 包含多种不同的损失函数,这里使用的是交叉熵(cross entropy loss)损失函数
criterion = torch.nn.CrossEntropyLoss()
# 这里使用 optim 包进行随机梯度下降(stochastic gradient descent)优化
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=lambda_l2)
# 开始训练
for t in range(1000):
# 把数据输入模型,得到预测结果
y_pred = model(X)
# 计算损失和准确率
loss = criterion(y_pred, Y)
score, predicted = torch.max(y_pred, 1)
acc = (Y == predicted).sum().float() / len(Y)
print('[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f' % (t, loss.item(), acc))
display.clear_output(wait=True)
# 反向传播前把梯度置 0
optimizer.zero_grad()
# 反向传播优化
loss.backward()
# 更新全部参数
optimizer.step()
![]()
print(y_pred.shape)
print(y_pred[10, :])
print(score[10])
print(predicted[10])

# Plot trained model
print(model)
plot_model(X, Y, model)

print(model)输出模型有两层
·第一层输入为2,输出为100
·第二层输入为100,输出为3
2.构建两层神经网络分类
learning_rate = 1e-3
lambda_l2 = 1e-5
# 这里可以看到,和上面模型不同的是,在两层之间加入了一个 ReLU 激活函数
model = nn.Sequential(
nn.Linear(D, H),
nn.ReLU(),
nn.Linear(H, C)
)
model.to(device)
# 下面的代码和之前是完全一样的,这里不过多叙述
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=lambda_l2) # built-in L2
# 训练模型,和之前的代码是完全一样的
for t in range(1000):
y_pred = model(X)
loss = criterion(y_pred, Y)
score, predicted = torch.max(y_pred, 1)
acc = ((Y == predicted).sum().float() / len(Y))
print("[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f" % (t, loss.item(), acc))
display.clear_output(wait=True)
# zero the gradients before running the backward pass.
optimizer.zero_grad()
# Backward pass to compute the gradient
loss.backward()
# Update params
optimizer.step()
![]()
# Plot trained model
print(model)
plot_model(X, Y, model)

sigmoid激活函数的缺点:
1.计算量大,反向传播求梯度误差时,求导涉及除法。
2.反向传播容易出现梯度消失。
解决方法:
RELU函数代替sigmoid函数。
ReLu函数的优点:
·可以使网络训练更快。
·增加网络的非线性。
·防止梯度消失。
·使网格具有稀疏性。
2.4回归分析
!wget https://raw.githubusercontent.com/Atcold/pytorch-Deep-Learning/master/res/plot_lib.py
import random
import torch
from torch import nn, optim
import math
from IPython import display
from plot_lib import plot_data, plot_model, set_default
from matplotlib import pyplot as plt
set_default()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
seed = 1
random.seed(seed)
torch.manual_seed(seed)
N = 1000 # 每类样本的数量
D = 1 # 每个样本的特征维度
C = 1 # 类别数
H = 100 # 隐层的神经元数量
X = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1).to(device)
y = X.pow(3) + 0.3 * torch.rand(X.size()).to(device)
print("Shapes:")
print("X:", tuple(X.size()))
print("y:", tuple(y.size()))
--2020-07-25 04:46:46-- https://raw.githubusercontent.com/Atcold/pytorch-Deep-Learning/master/res/plot_lib.py
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 151.101.0.133, 151.101.64.133, 151.101.128.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|151.101.0.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 4399 (4.3K) [text/plain]
Saving to: ‘plot_lib.py.1’
plot_lib.py.1 100%[===================>] 4.30K --.-KB/s in 0s
2020-07-25 04:46:47 (61.1 MB/s) - ‘plot_lib.py.1’ saved [4399/4399]
Shapes:
X: (100, 1)
y: (100, 1)
# 在坐标系上显示数据
plt.figure(figsize=(6, 6))
plt.scatter(X.cpu().numpy(), y.cpu().numpy())
plt.axis('equal');

建立线性模型(两层之间没有激活函数)
learning_rate = 1e-3
lambda_l2 = 1e-5
# 建立神经网络模型
model = nn.Sequential(
nn.Linear(D, H),
nn.Linear(H, C)
)
model.to(device) # 模型转到 GPU
# 对于回归问题,使用MSE损失函数
criterion = torch.nn.MSELoss()
# 定义优化器,使用SGD
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=lambda_l2) # built-in L2
# 开始训练
for t in range(1000):
# 数据输入模型得到预测结果
y_pred = model(X)
# 计算 MSE 损失
loss = criterion(y_pred, y)
print("[EPOCH]: %i, [LOSS or MSE]: %.6f" % (t, loss.item()))
display.clear_output(wait=True)
# 反向传播前,梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
![]()
# 展示模型与结果
print(model)
plt.figure(figsize=(6,6))
plt.scatter(X.data.cpu().numpy(), y.data.cpu().numpy())
plt.plot(X.data.cpu().numpy(), y_pred.data.cpu().numpy(), 'r-', lw=5)
plt.axis('equal');

回归结果
# 这里定义了2个网络,一个 relu_model,一个 tanh_model,
# 使用了不同的激活函数
relu_model = nn.Sequential(
nn.Linear(D, H),
nn.ReLU(),
nn.Linear(H, C)
)
relu_model.to(device)
tanh_model = nn.Sequential(
nn.Linear(D, H),
nn.Tanh(),
nn.Linear(H, C)
)
tanh_model.to(device)
# MSE损失函数
criterion = torch.nn.MSELoss()
# 定义优化器,使用 Adam,这里仍使用 SGD 优化器的化效果会比较差
optimizer_relumodel = torch.optim.Adam(relu_model.parameters(), lr=learning_rate, weight_decay=lambda_l2)
optimizer_tanhmodel = torch.optim.Adam(tanh_model.parameters(), lr=learning_rate, weight_decay=lambda_l2)
# 开始训练
for t in range(1000):
y_pred_relumodel = relu_model(X)
y_pred_tanhmodel = tanh_model(X)
# 计算损失与准确率
loss_relumodel = criterion(y_pred_relumodel, y)
loss_tanhmodel = criterion(y_pred_tanhmodel, y)
print(f"[MODEL]: relu_model, [EPOCH]: {t}, [LOSS]: {loss_relumodel.item():.6f}")
print(f"[MODEL]: tanh_model, [EPOCH]: {t}, [LOSS]: {loss_tanhmodel.item():.6f}")
display.clear_output(wait=True)
optimizer_relumodel.zero_grad()
optimizer_tanhmodel.zero_grad()
loss_relumodel.backward()
loss_tanhmodel.backward()
optimizer_relumodel.step()
optimizer_tanhmodel.step()
plt.figure(figsize=(12, 6))
def dense_prediction(model, non_linearity):
plt.subplot(1, 2, 1 if non_linearity == 'ReLU' else 2)
X_new = torch.unsqueeze(torch.linspace(-1, 1, 1001), dim=1).to(device)
with torch.no_grad():
y_pred = model(X_new)
plt.plot(X_new.cpu().numpy(), y_pred.cpu().numpy(), 'r-', lw=1)
plt.scatter(X.cpu().numpy(), y.cpu().numpy(), label='data')
plt.axis('square')
plt.title(non_linearity + ' models')
dense_prediction(relu_model, 'ReLU')
dense_prediction(tanh_model, 'Tanh')

Tanh是Sigmoid的变形,与sigmoid不同的是,tanh是0均值的。因此,实际应用中,tanh会比sigmoid更好。
使用ReLU激活函数收敛较快;使用Tanh激活函数,一开始收敛慢随后收敛也逐渐达到较好效果。
使用ReLU得到的SGD的收敛速度会比sigmoid/tanh快很多。是因为相比于sigmoid/tanh,ReLU只需要一个阈值就可以得到激活值,而不用去算一大堆复杂的运算。