快速起步的Apache Flink,远比我们看到的更强大,难怪阿里会选择它
最近因为工作需要,接触了大数据计算引擎Flink。
目前开源大数据计算引擎有很多选择,流计算如Storm,Flink,Kafka Stream等,批处理如Spark,Hive,Pig,Flink等。而同时支持流处理和批处理的计算引擎,只有两种选择:一个是Apache Spark,一个是Apache Flink。
据了解,基于Apache Flink在阿里巴巴搭建的平台于2016年正式上线,并从阿里巴巴的搜索和推荐这两大场景开始实现。目前阿里巴巴所有的业务,包括阿里巴巴所有子公司都采用了基于Flink搭建的实时计算平台。
关于Flink DataStream 常用算子 Map、FlatMap、Filter、KeyBy、Reduce,下面简单对其小结下:
1、FlatMap
举例,一行变多行,将一个句子(一行)分割成多个单词(多行)
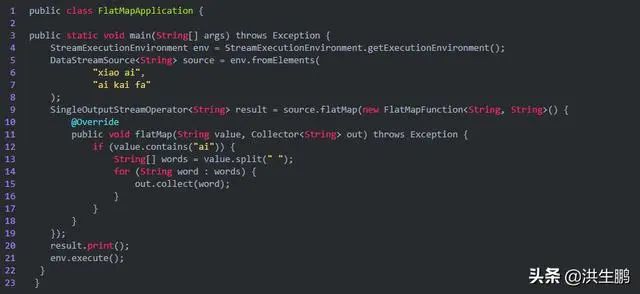
输出结果:
4> xiao
5> ai
4> ai
5> kai
5> fa
2、Filter
过滤出需要的数据,可以做数据清洗
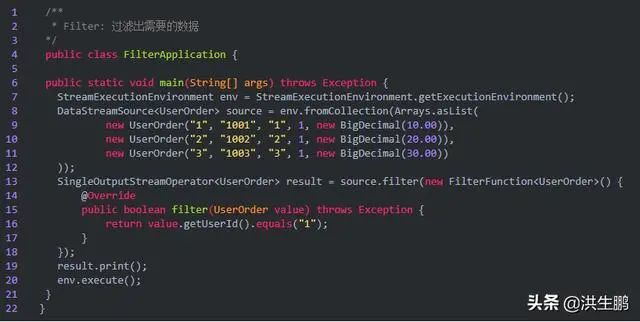
输出结果:
//2> UserOrder [userId=1, orderId=1001, itemId=1, itemNumber=1, price=10]
3、KeyBy
按指定的Key对数据重分区。将同一Key的数据放到同一个分区
分区结果和KeyBy下游算子的并行度强相关。如下游算子只有一个并行度,不管怎么分,都会分到一起。
对于POJO类型,KeyBy可以通过keyBy(fieldName)指定字段进行分区。
对于Tuple类型,KeyBy可以通过keyBy(fieldPosition)指定字段进行分区。
对于一般类型,如上, KeyBy可以通过keyBy(new KeySelector {...})指定字段进行分区。
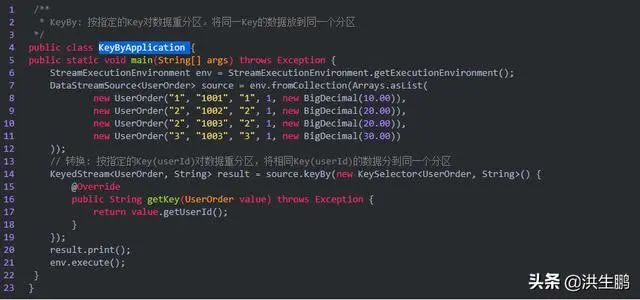
输出结果:
//6> UserOrder [userId=1, orderId=1001, itemId=1, itemNumber=1, price=10]
//4> UserOrder [userId=3, orderId=1003, itemId=3, itemNumber=1, price=30]
//3> UserOrder [userId=2, orderId=1002, itemId=2, itemNumber=1, price=20]
//3> UserOrder [userId=2, orderId=1003, itemId=2, itemNumber=1, price=20]
4、Map
map可以理解为映射,对每个元素进行一定的变换后,映射为另一个元素。
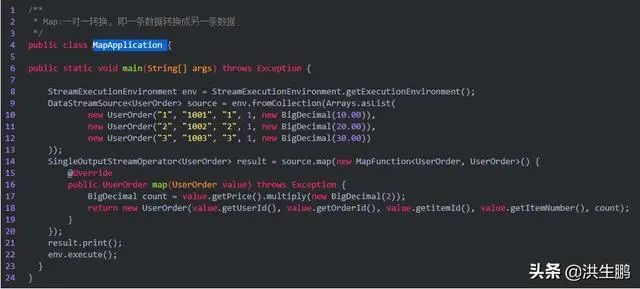
输出结果
// 10> UserOrder [userId=2, orderId=1002, itemId=2, itemNumber=1, price=40]
// 11> UserOrder [userId=3, orderId=1003, itemId=3, itemNumber=1, price=60]
// 9> UserOrder [userId=1, orderId=1001, itemId=1, itemNumber=1, price=20]
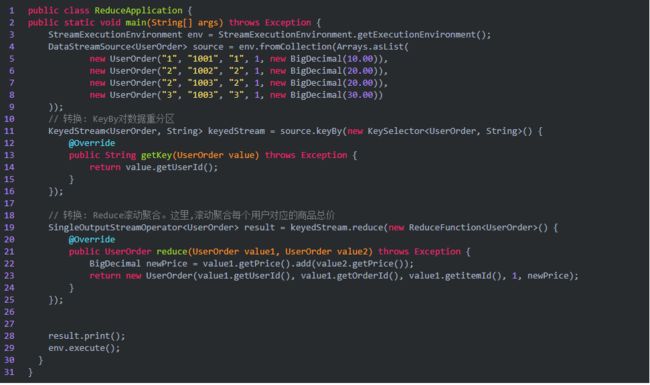
5、Reduce
基于ReduceFunction进行滚动聚合
Reduce: 基于ReduceFunction进行滚动聚合,并向下游算子输出每次滚动聚合后的结果。注意: Reduce会输出每一次滚动聚合的结果。
快速起步的Apache Flink,这远比我们看到的更强大,难怪阿里当初会选择它。
-END-
作者:洪生鹏 技术交流、媒体合作、品牌宣传请加作者微信: hsp-88ios
猜你喜欢
知名公司面试题:谈谈你对volatile关键字的理解

更多惊喜,请长按二维码识别关注