Coursera 机器学习(by Andrew Ng)课程学习笔记 Week 6(二)——误差分析与数据集偏斜处理
此系列为 Coursera 网站机器学习课程个人学习笔记(仅供参考)
课程网址:https://www.coursera.org/learn/machine-learning
参考资料:http://blog.csdn.net/quiet_girl/article/details/70842146
一、垃圾邮件分类
1.1 输入特征
我们从邮件中选出若干特征词,例如:deal、buy、discount、Andrew,now……这些词我们不需要手动选择,可以遍历数据集选出频率最高的 n 个词,一般在 10000∼50000 之间。我们用特征向量 x 来表示邮件, xj 表示上面特征词 wordj 是否出现在邮件里。
1.2 如何提高分类器的性能
- 收集更多的数据,如可以利用一个叫“Honey Pot”项目创建一些假的邮件地址,并泄露给发垃圾邮件的人,这样就可以收到大量的垃圾邮件,这些邮件可以当做训练集中的数据使用。
- 找出基于路由信息的更复杂的特征(路由信息在邮件的header中)。
- 寻找邮件主题内容的更复杂的特征,如:“discount”和“discounts”是否是同一个特征?“deal”和“Dealer”是否是同一个特征?以及标点符号特征。
- 找出更复杂的算法来探测拼写错误,如m0rtgage,medlcine,w4tches等。
虽然我们知道有这些方法,但是具体哪些方法有效,这个很难说清楚,需要根据实际情况考虑。
二、误差分析
在解决机器学习问题时,我们推荐的方法是:
- Start with a simple algorithm, implement it quickly, and test it early on your cross validation data.
- Plot learning curves to decide if more data, more features, etc. are likely to help.
- Manually examine the errors on examples in the cross validation set and try to spot a trend where most of the errors were made.
举例说明
交叉验证集中一共有500个数据,其中发现有100个数据被错误分类,通过手动检测这100个错误分类的邮件,我们需要去思考以下问题:
- 这些邮件是什么类型的(type)?
- 哪些特征可以帮助我们更好的分类这些邮件?
(1)假如我们发现在这100个错误分类的邮件中,分类如下:
Phrama:12
Replica/fake:4
Steal passwords:53
Other:31
我们发现Steal passwords(窃取密码)的这种邮件较多,那么我们需要把时间主要花费在这个上面来研究是否通过设计特征或者其他的方法来减小Steal passwords邮件的误分类率。
(2)假如我们发现在这100个错误分类的邮件中,
Deliberate misspellings(m0rgage,medlcine,etc.):5
Unusual email routing:16
Unusual(Spamming) punctuation:32
我们发现拼写错误的比较少,因此我们没有必要把时间耗费在研究拼写错误上面。
这种分析不同类型的误差分析的方法是一种手动检测的过程,检测算法可能会犯的错误,这能够帮助你找到更为有效的改进算法的思路。这也解释了为什么要先实现一种快速即使不太完美的算法。我们真正想要的是找出这种算法最难分类的邮件类型。而对于不同的机器学习算法 它们所遇到的问题一般总是相同的。通过实现一些快速简单的算法,能够更快地找到错误所在,并且快速找出算法难以处理的实例,这样你就能把精力集中在这些真正的问题上。
我们知道了面对较高的误分类率我们应该怎么做,那么我们怎样衡量这么做是否有用呢?这就需要引入数值评估的内容了。
因为我们不能直接看出我们的方法对提高系统性能是否有帮助,唯一的办法就是利用量化的数值评估。
比如,我们来衡量词干提取器有没有作用:
若在使用词干提取器之前误差率为5%,使用词干提取器之后误差率为3%,则说明提取器是有作用的(在后续学习中,这个评判数据还需要一些处理)。
一般来说,我们建议在交叉验证集上进行误差分析,而不是在测试集上。
三、数据集偏斜(Skewed Class)
以我们之前提到的肿瘤恶性与良性检测问题为例。患有癌症为 1 ,没有患癌症为 0 。假如我们在测试集上进行测试,结果只有 1% 的误分类率,看起来结果好像不错,但如果测试集中真正患有癌症的病人只有 0.50% ,这个结果就不太理想了。这个例子中,正样本的数量远远大于负样本,这种情况我们称之为偏斜类(Skewed Class)。对于这种情况,原来的误分类率不能再作为算法好坏的度量标准。下面我们会介绍如何解决这个问题。
3.1 查准率\召回率(Precision/Recall)
对于二分类问题,原始类为正样本(positive)和负样本(negative),预测后结果也有两种,最后的结果一共有 4 种情况:
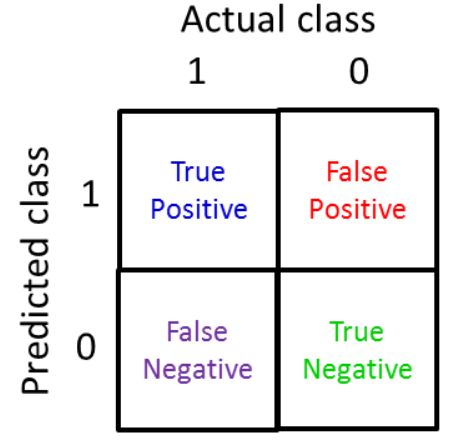

查准率和召回率越高,算法性能越好。
3.2 F Score
如果一个算法的查准率和召回率都很高,我们可以判断这个算法表现很好,但有时,我们需要控制这两个数值的相对平衡。下面我们介绍一个有效的方法。
仍然以肿瘤良性与恶性为例。之前我们的预测结果如下:

如果我们希望在更确定的情况下再判断患者得了癌症,因为这是一个坏消息,误诊可能造成患者的恐慌。这样的话,我们可以把临界值 0.5 改为 0.7 ,这样就可以得到较高的查准率,但召回率相对会降低。
如果我们希望保证癌症患者及时得到医治,不放过任何一个可能病例,我们需要把临界值降低,比如改为 0.3 。这样会得到较高的召回率,但查准率相对会降低。
那么我们可不可以自动选取临界值呢?
如下面几个算法(可能算法相同,临界值不同),我们如何判断哪个更好?
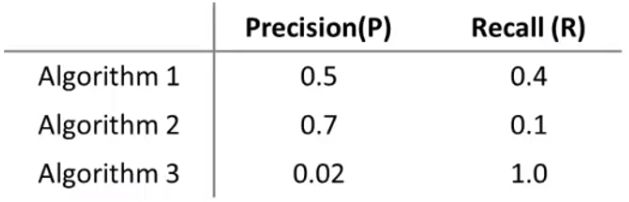
可能会有人想到求平均值 Average=P+R2 ,看哪个更高。但显然这并不是一个很好的解决办法。因为按平均值来看,算法3是最高的,但这不是我们希望的。一般来说,我们用 F1Score 值来评估:
我们可以看分子是查准率和召回率的乘积,这就要求两者的值都比较高。
如果 P=0 或者 R=0 ,则 F1Score=0 ;
如果 P=1 和 R=1 ,则 F1Score=1 。
F1Score 的值在 0 、 1 之间,值越高说明算法的性能越好。