PDF文件中交叉引用流对象(cross-reference stream)的解析方法
PDF文件中交叉引用流对象(cross-reference stream)的解析方法
1 介绍
在PDF-1.5版本[1]之前,对象的交叉引用信息是存储在交叉引用表(cross-reference table)中的。在PDF-1.5版本之后,引进了交叉引用流(cross-reference stream)对象,可以用它来存储对象的交叉引用信息,就像交叉引用表的功能一样。
采用交叉引用流对象存储对象的交叉引用信息至少有以下几点好处:
1) 存储的信息更紧凑,并且可以引入压缩算法进行压缩
2) 提供了访问存储于对象流(ObjectStreams)中的被压缩的对象的功能
3) 提供了将来的可扩展的交叉引用流的表项类型,以便存储更多不同信息
交叉引用流对象在PDF文件中的偏移位置,由关键字startxref 指出;而相应的交叉引用表则由关键字xref指出。交叉引用流对象的类型为XRef, 也即其对象类型具有如下形式:”/Type /XRef”
下述的片段就是一个交叉引用流对象例子:
41 0 obj
<Filter/FlateDecode/DecodeParms<</Columns 7/Predictor 12>>/Length111/Root 1 0 R /Info 11 0 R /ID[<88009A03A92CE346AF48303D7897A1B6>
x渃b ??仈 ##?g``??恇?褸?孡`?@
?>0?4
壷?髆哤 ?Ue?蟘x 瓈?伱緂P>L??#?‑凐?濽?
endstream
endobj
可以看到此对象需要进行”FlateDecode”解码,并且之后还要进行PNG的过滤器再解码(由DecodeParms参数指出),才能得到最终的数据。
2 解析
交叉引用流对象通常在存储之前都会进行压缩,而为了提高压缩率,会进行数据的预处理,这个预处理就称为过滤(filter)。读取时再进行反向的处理,如下图所示:
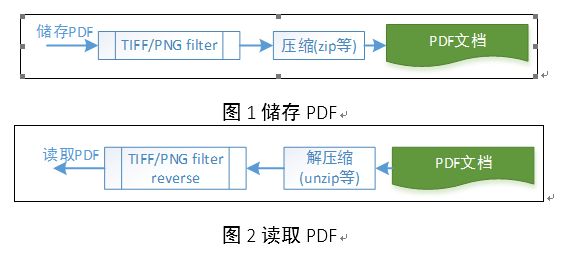
2.1 压缩/解压缩
对于压缩/解压缩的处理,可以采用开源的zlib库[2]进行处理,其中的压缩算法称为”deflate”, 解压缩算法称为” inflate”,这里不再详细说明。
2.2 Filter处理
当PDF文件中的对象(Object)指示采用LZWDecode或者FlateDecode进行解压缩时,在解码参数中的Predictor指示了解压缩完成后,再对数据进行的filter过滤器处理算法。常用的过滤器算法有TIFF和PNG两大类。在文档《PDF Reference, Sixth Edition, version 1.7》中的3.3.3节的”TABLE 3.8Predictor values“中,说明了不同的Predictor值对应的filter类型及算法。如下图:
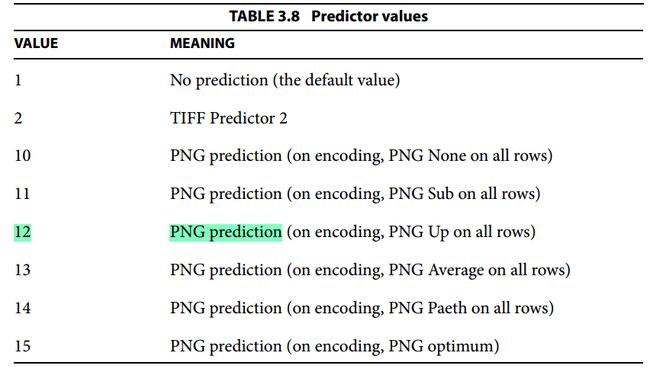
图3 Predictor值对应的filter
2.3 PNG Filter
PNG filter过滤器算法可以在W3C网页上[3]查到。这里以”Predictor12”也即PNG Up的过滤器算法为例简单介绍如下:
由于PNG Filter是针对图片进行处理的,因此输入的数据也必须指定为”行x列”的形式。从网页介绍可知,PNGfilter有5种,即:0-None, 1-Sub, 2-Up, 3-Average, 4-Paeth。过滤器是作用在输入数据的每一行的每个字节(byte)上的,并且每一行可以独立的指定不同的过滤器。为了做到这点,在过滤时会在每一行数据的最前面插入一个字节表明采用的过滤器类型;在数据解码时则需要将此字节去除。
换言之,如果原始数据为rows 行,columns列,那么经过过滤器之后的数据为rows行,columns+1列,并且第一列的字节指示了此行采用的过滤器算法。
图4 PNG filter 执行结果
这里以读取第一节的数据(/Filter/FlateDecode/DecodeParms<</Columns 7/Predictor 12>>)为例进行举例说明:
/Filter/FlateDecode:说明对steam和endstream之间的数据用zlib的inflate解压缩。
/DecodeParms<</Columns 7/Predictor 12>>:解压缩后的数据还需要进行PNG Filter Up算法的反向处理(因为是读取)
Zlib的inflate算法是现成的,这里不介绍。PNG filter算法比较简单,我们自己来实现它。
“/Columns 7”说明图像宽度为7像素(当然这里不是图像,只是借用而已)。
“/Colors x” 参数未出现,默认值为1,代表每个像素一种颜色。
“/BitsPerComponent”参数未出现,默认值为8,代表每种颜色8比特表示。
“/Predictor 12”表面数据经过了PNG的Up filter算法处理。
于是每一行的字节数为:Columns x Colors x BitsPerComponent /8bit = 7x1x8/8 = 7字节。也即图像宽度为7字节。经过zlib解压缩后的数据行宽度为7+1=8字节。
下图为up filter的反向处理源代码示例:

其它的PNG Filter算法可以同样的完成。
3 结论
PDF-1.5之后可以采用交叉引用流对象来替代交叉引用表,使得存储PDF和更高效,但是也带来了解析上的复杂性。通过本文例子可以很方便的进行交叉引用流对象进行解析。
参考文献
[1] PDF Reference, Sixth Edition, version1.7[EB/OL].https://wwwimages2.adobe.com/content/dam/Adobe/en/devnet/pdf/pdfs/pdf_reference_1-7.pdf.
[2] zlib[EB/OL]. http://www.zlib.net/.
[3] Filter Algorithms[EB/OL].https://www.w3.org/TR/PNG-Filters.html.