《动手学深度学习》Task07:优化算法进阶;word2vec;词嵌入进阶
Task07:优化算法进阶;word2vec;词嵌入进阶
1.优化算法进阶
Momentum
在 Section 11.4 中,我们提到,目标函数有关自变量的梯度代表了目标函数在自变量当前位置下降最快的方向。因此,梯度下降也叫作最陡下降(steepest descent)。在每次迭代中,梯度下降根据自变量当前位置,沿着当前位置的梯度更新自变量。然而,如果自变量的迭代方向仅仅取决于自变量当前位置,这可能会带来一些问题。对于noisy gradient,我们需要谨慎的选取学习率和batch size, 来控制梯度方差和收敛的结果。


- Supp: Preconditioning



指数加权移动平均(exponential moving average)


实现:
def get_data_ch7():
data = np.genfromtxt('/home/kesci/input/airfoil4755/airfoil_self_noise.dat', delimiter='\t')
data = (data - data.mean(axis=0)) / data.std(axis=0)
return torch.tensor(data[:1500, :-1], dtype=torch.float32), \
torch.tensor(data[:1500, -1], dtype=torch.float32)
features, labels = get_data_ch7()
def init_momentum_states():
v_w = torch.zeros((features.shape[1], 1), dtype=torch.float32)
v_b = torch.zeros(1, dtype=torch.float32)
return (v_w, v_b)
def sgd_momentum(params, states, hyperparams):
for p, v in zip(params, states):
v.data = hyperparams['momentum'] * v.data + hyperparams['lr'] * p.grad.data
p.data -= v.data
d2l.train_ch7(sgd_momentum, init_momentum_states(),
{'lr': 0.02, 'momentum': 0.5}, features, labels)
d2l.train_ch7(sgd_momentum, init_momentum_states(),
{'lr': 0.02, 'momentum': 0.9}, features, labels)
d2l.train_ch7(sgd_momentum, init_momentum_states(),
{'lr': 0.004, 'momentum': 0.9}, features, labels)
d2l.train_pytorch_ch7(torch.optim.SGD, {'lr': 0.004, 'momentum': 0.9},
features, labels)
AdaGrad


%matplotlib inline
import math
import torch
import sys
sys.path.append("/home/kesci/input")
import d2lzh1981 as d2l
def adagrad_2d(x1, x2, s1, s2):
g1, g2, eps = 0.2 * x1, 4 * x2, 1e-6 # 前两项为自变量梯度
s1 += g1 ** 2
s2 += g2 ** 2
x1 -= eta / math.sqrt(s1 + eps) * g1
x2 -= eta / math.sqrt(s2 + eps) * g2
return x1, x2, s1, s2
def f_2d(x1, x2):
return 0.1 * x1 ** 2 + 2 * x2 ** 2
def get_data_ch7():
data = np.genfromtxt('/home/kesci/input/airfoil4755/airfoil_self_noise.dat', delimiter='\t')
data = (data - data.mean(axis=0)) / data.std(axis=0)
return torch.tensor(data[:1500, :-1], dtype=torch.float32), \
torch.tensor(data[:1500, -1], dtype=torch.float32)
features, labels = get_data_ch7()
def init_adagrad_states():
s_w = torch.zeros((features.shape[1], 1), dtype=torch.float32)
s_b = torch.zeros(1, dtype=torch.float32)
return (s_w, s_b)
def adagrad(params, states, hyperparams):
eps = 1e-6
for p, s in zip(params, states):
s.data += (p.grad.data**2)
p.data -= hyperparams['lr'] * p.grad.data / torch.sqrt(s + eps)
d2l.train_ch7(adagrad, init_adagrad_states(), {'lr': 0.1}, features, labels)
RMSProp

%matplotlib inline
import math
import torch
import sys
sys.path.append("/home/kesci/input")
import d2lzh1981 as d2l
def rmsprop_2d(x1, x2, s1, s2):
g1, g2, eps = 0.2 * x1, 4 * x2, 1e-6
s1 = beta * s1 + (1 - beta) * g1 ** 2
s2 = beta * s2 + (1 - beta) * g2 ** 2
x1 -= alpha / math.sqrt(s1 + eps) * g1
x2 -= alpha / math.sqrt(s2 + eps) * g2
return x1, x2, s1, s2
def f_2d(x1, x2):
return 0.1 * x1 ** 2 + 2 * x2 ** 2
alpha, beta = 0.4, 0.9
d2l.show_trace_2d(f_2d, d2l.train_2d(rmsprop_2d))
def get_data_ch7():
data = np.genfromtxt('/home/kesci/input/airfoil4755/airfoil_self_noise.dat', delimiter='\t')
data = (data - data.mean(axis=0)) / data.std(axis=0)
return torch.tensor(data[:1500, :-1], dtype=torch.float32), \
torch.tensor(data[:1500, -1], dtype=torch.float32)
features, labels = get_data_ch7()
def init_rmsprop_states():
s_w = torch.zeros((features.shape[1], 1), dtype=torch.float32)
s_b = torch.zeros(1, dtype=torch.float32)
return (s_w, s_b)
def rmsprop(params, states, hyperparams):
gamma, eps = hyperparams['beta'], 1e-6
for p, s in zip(params, states):
s.data = gamma * s.data + (1 - gamma) * (p.grad.data)**2
p.data -= hyperparams['lr'] * p.grad.data / torch.sqrt(s + eps)
d2l.train_ch7(rmsprop, init_rmsprop_states(), {'lr': 0.01, 'beta': 0.9},
features, labels)
AdaDelta

实现:
def init_adadelta_states():
s_w, s_b = torch.zeros((features.shape[1], 1), dtype=torch.float32), torch.zeros(1, dtype=torch.float32)
delta_w, delta_b = torch.zeros((features.shape[1], 1), dtype=torch.float32), torch.zeros(1, dtype=torch.float32)
return ((s_w, delta_w), (s_b, delta_b))
def adadelta(params, states, hyperparams):
rho, eps = hyperparams['rho'], 1e-5
for p, (s, delta) in zip(params, states):
s[:] = rho * s + (1 - rho) * (p.grad.data**2)
g = p.grad.data * torch.sqrt((delta + eps) / (s + eps))
p.data -= g
delta[:] = rho * delta + (1 - rho) * g * g
d2l.train_ch7(adadelta, init_adadelta_states(), {'rho': 0.9}, features, labels)
d2l.train_pytorch_ch7(torch.optim.Adadelta, {'rho': 0.9}, features, labels)
Adam

%matplotlib inline
import torch
import sys
sys.path.append("/home/kesci/input")
import d2lzh1981 as d2l
def get_data_ch7():
data = np.genfromtxt('/home/kesci/input/airfoil4755/airfoil_self_noise.dat', delimiter='\t')
data = (data - data.mean(axis=0)) / data.std(axis=0)
return torch.tensor(data[:1500, :-1], dtype=torch.float32), \
torch.tensor(data[:1500, -1], dtype=torch.float32)
features, labels = get_data_ch7()
def init_adam_states():
v_w, v_b = torch.zeros((features.shape[1], 1), dtype=torch.float32), torch.zeros(1, dtype=torch.float32)
s_w, s_b = torch.zeros((features.shape[1], 1), dtype=torch.float32), torch.zeros(1, dtype=torch.float32)
return ((v_w, s_w), (v_b, s_b))
def adam(params, states, hyperparams):
beta1, beta2, eps = 0.9, 0.999, 1e-6
for p, (v, s) in zip(params, states):
v[:] = beta1 * v + (1 - beta1) * p.grad.data
s[:] = beta2 * s + (1 - beta2) * p.grad.data**2
v_bias_corr = v / (1 - beta1 ** hyperparams['t'])
s_bias_corr = s / (1 - beta2 ** hyperparams['t'])
p.data -= hyperparams['lr'] * v_bias_corr / (torch.sqrt(s_bias_corr) + eps)
hyperparams['t'] += 1
d2l.train_ch7(adam, init_adam_states(), {'lr': 0.01, 't': 1}, features, labels)
d2l.train_pytorch_ch7(torch.optim.Adam, {'lr': 0.01}, features, labels)
2.word2vec
我们在“循环神经网络的从零开始实现”一节中使用 one-hot 向量表示单词,虽然它们构造起来很容易,但通常并不是一个好选择。一个主要的原因是,one-hot 词向量无法准确表达不同词之间的相似度,如我们常常使用的余弦相似度。
Word2Vec 词嵌入工具的提出正是为了解决上面这个问题,它将每个词表示成一个定长的向量,并通过在语料库上的预训练使得这些向量能较好地表达不同词之间的相似和类比关系,以引入一定的语义信息。基于两种概率模型的假设,我们可以定义两种 Word2Vec 模型:
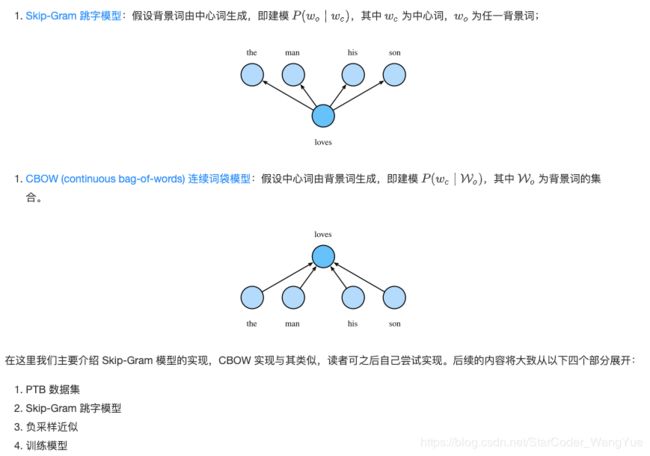
- PTB 数据集
简单来说,Word2Vec 能从语料中学到如何将离散的词映射为连续空间中的向量,并保留其语义上的相似关系。那么为了训练 Word2Vec 模型,我们就需要一个自然语言语料库,模型将从中学习各个单词间的关系,这里我们使用经典的 PTB 语料库进行训练。PTB (Penn Tree Bank) 是一个常用的小型语料库,它采样自《华尔街日报》的文章,包括训练集、验证集和测试集。我们将在PTB训练集上训练词嵌入模型。
载入数据集
with open('/home/kesci/input/ptb_train1020/ptb.train.txt', 'r') as f:
lines = f.readlines() # 该数据集中句子以换行符为分割
raw_dataset = [st.split() for st in lines] # st是sentence的缩写,单词以空格为分割
print('# sentences: %d' % len(raw_dataset))
# 对于数据集的前3个句子,打印每个句子的词数和前5个词
# 句尾符为 '' ,生僻词全用 '' 表示,数字则被替换成了 'N'
for st in raw_dataset[:3]:
print('# tokens:', len(st), st[:5])
建立词语索引
counter = collections.Counter([tk for st in raw_dataset for tk in st]) # tk是token的缩写
counter = dict(filter(lambda x: x[1] >= 5, counter.items())) # 只保留在数据集中至少出现5次的词
idx_to_token = [tk for tk, _ in counter.items()]
token_to_idx = {tk: idx for idx, tk in enumerate(idx_to_token)}
dataset = [[token_to_idx[tk] for tk in st if tk in token_to_idx]
for st in raw_dataset] # raw_dataset中的单词在这一步被转换为对应的idx
num_tokens = sum([len(st) for st in dataset])
'# tokens: %d' % num_tokens
- 二次采样

def discard(idx):
'''
@params:
idx: 单词的下标
@return: True/False 表示是否丢弃该单词
'''
return random.uniform(0, 1) < 1 - math.sqrt(
1e-4 / counter[idx_to_token[idx]] * num_tokens)
subsampled_dataset = [[tk for tk in st if not discard(tk)] for st in dataset]
print('# tokens: %d' % sum([len(st) for st in subsampled_dataset]))
def compare_counts(token):
return '# %s: before=%d, after=%d' % (token, sum(
[st.count(token_to_idx[token]) for st in dataset]), sum(
[st.count(token_to_idx[token]) for st in subsampled_dataset]))
print(compare_counts('the'))
print(compare_counts('join'))
- 提取中心词和背景词
def get_centers_and_contexts(dataset, max_window_size):
'''
@params:
dataset: 数据集为句子的集合,每个句子则为单词的集合,此时单词已经被转换为相应数字下标
max_window_size: 背景词的词窗大小的最大值
@return:
centers: 中心词的集合
contexts: 背景词窗的集合,与中心词对应,每个背景词窗则为背景词的集合
'''
centers, contexts = [], []
for st in dataset:
if len(st) < 2: # 每个句子至少要有2个词才可能组成一对“中心词-背景词”
continue
centers += st
for center_i in range(len(st)):
window_size = random.randint(1, max_window_size) # 随机选取背景词窗大小
indices = list(range(max(0, center_i - window_size),
min(len(st), center_i + 1 + window_size)))
indices.remove(center_i) # 将中心词排除在背景词之外
contexts.append([st[idx] for idx in indices])
return centers, contexts
all_centers, all_contexts = get_centers_and_contexts(subsampled_dataset, 5)
tiny_dataset = [list(range(7)), list(range(7, 10))]
print('dataset', tiny_dataset)
for center, context in zip(*get_centers_and_contexts(tiny_dataset, 2)):
print('center', center, 'has contexts', context)
Skip-Gram 跳字模型

embed = nn.Embedding(num_embeddings=10, embedding_dim=4)
print(embed.weight)
x = torch.tensor([[1, 2, 3], [4, 5, 6]], dtype=torch.long)
print(embed(x))
X = torch.ones((2, 1, 4))
Y = torch.ones((2, 4, 6))
print(torch.bmm(X, Y).shape
def skip_gram(center, contexts_and_negatives, embed_v, embed_u):
'''
@params:
center: 中心词下标,形状为 (n, 1) 的整数张量
contexts_and_negatives: 背景词和噪音词下标,形状为 (n, m) 的整数张量
embed_v: 中心词的 embedding 层
embed_u: 背景词的 embedding 层
@return:
pred: 中心词与背景词(或噪音词)的内积,之后可用于计算概率 p(w_o|w_c)
'''
v = embed_v(center) # shape of (n, 1, d)
u = embed_u(contexts_and_negatives) # shape of (n, m, d)
pred = torch.bmm(v, u.permute(0, 2, 1)) # bmm((n, 1, d), (n, d, m)) => shape of (n, 1, m)
return pred
- 负采样近似

def get_negatives(all_contexts, sampling_weights, K):
'''
@params:
all_contexts: [[w_o1, w_o2, ...], [...], ... ]
sampling_weights: 每个单词的噪声词采样概率
K: 随机采样个数
@return:
all_negatives: [[w_n1, w_n2, ...], [...], ...]
'''
all_negatives, neg_candidates, i = [], [], 0
population = list(range(len(sampling_weights)))
for contexts in all_contexts:
negatives = []
while len(negatives) < len(contexts) * K:
if i == len(neg_candidates):
# 根据每个词的权重(sampling_weights)随机生成k个词的索引作为噪声词。
# 为了高效计算,可以将k设得稍大一点
i, neg_candidates = 0, random.choices(
population, sampling_weights, k=int(1e5))
neg, i = neg_candidates[i], i + 1
# 噪声词不能是背景词
if neg not in set(contexts):
negatives.append(neg)
all_negatives.append(negatives)
return all_negatives
sampling_weights = [counter[w]**0.75 for w in idx_to_token]
all_negatives = get_negatives(all_contexts, sampling_weights, 5)
class MyDataset(torch.utils.data.Dataset):
def __init__(self, centers, contexts, negatives):
assert len(centers) == len(contexts) == len(negatives)
self.centers = centers
self.contexts = contexts
self.negatives = negatives
def __getitem__(self, index):
return (self.centers[index], self.contexts[index], self.negatives[index])
def __len__(self):
return len(self.centers)
def batchify(data):
'''
用作DataLoader的参数collate_fn
@params:
data: 长为batch_size的列表,列表中的每个元素都是__getitem__得到的结果
@outputs:
batch: 批量化后得到 (centers, contexts_negatives, masks, labels) 元组
centers: 中心词下标,形状为 (n, 1) 的整数张量
contexts_negatives: 背景词和噪声词的下标,形状为 (n, m) 的整数张量
masks: 与补齐相对应的掩码,形状为 (n, m) 的0/1整数张量
labels: 指示中心词的标签,形状为 (n, m) 的0/1整数张量
'''
max_len = max(len(c) + len(n) for _, c, n in data)
centers, contexts_negatives, masks, labels = [], [], [], []
for center, context, negative in data:
cur_len = len(context) + len(negative)
centers += [center]
contexts_negatives += [context + negative + [0] * (max_len - cur_len)]
masks += [[1] * cur_len + [0] * (max_len - cur_len)] # 使用掩码变量mask来避免填充项对损失函数计算的影响
labels += [[1] * len(context) + [0] * (max_len - len(context))]
batch = (torch.tensor(centers).view(-1, 1), torch.tensor(contexts_negatives),
torch.tensor(masks), torch.tensor(labels))
return batch
batch_size = 512
num_workers = 0 if sys.platform.startswith('win32') else 4
dataset = MyDataset(all_centers, all_contexts, all_negatives)
data_iter = Data.DataLoader(dataset, batch_size, shuffle=True,
collate_fn=batchify,
num_workers=num_workers)
for batch in data_iter:
for name, data in zip(['centers', 'contexts_negatives', 'masks',
'labels'], batch):
print(name, 'shape:', data.shape)
break
class SigmoidBinaryCrossEntropyLoss(nn.Module):
def __init__(self):
super(SigmoidBinaryCrossEntropyLoss, self).__init__()
def forward(self, inputs, targets, mask=None):
'''
@params:
inputs: 经过sigmoid层后为预测D=1的概率
targets: 0/1向量,1代表背景词,0代表噪音词
@return:
res: 平均到每个label的loss
'''
inputs, targets, mask = inputs.float(), targets.float(), mask.float()
res = nn.functional.binary_cross_entropy_with_logits(inputs, targets, reduction="none", weight=mask)
res = res.sum(dim=1) / mask.float().sum(dim=1)
return res
loss = SigmoidBinaryCrossEntropyLoss()
pred = torch.tensor([[1.5, 0.3, -1, 2], [1.1, -0.6, 2.2, 0.4]])
label = torch.tensor([[1, 0, 0, 0], [1, 1, 0, 0]]) # 标签变量label中的1和0分别代表背景词和噪声词
mask = torch.tensor([[1, 1, 1, 1], [1, 1, 1, 0]]) # 掩码变量
print(loss(pred, label, mask))
def sigmd(x):
return - math.log(1 / (1 + math.exp(-x)))
print('%.4f' % ((sigmd(1.5) + sigmd(-0.3) + sigmd(1) + sigmd(-2)) / 4)) # 注意1-sigmoid(x) = sigmoid(-x)
print('%.4f' % ((sigmd(1.1) + sigmd(-0.6) + sigmd(-2.2)) / 3))
embed_size = 100
net = nn.Sequential(nn.Embedding(num_embeddings=len(idx_to_token), embedding_dim=embed_size),
nn.Embedding(num_embeddings=len(idx_to_token), embedding_dim=embed_size))
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print("train on", device)
net = net.to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
for epoch in range(num_epochs):
start, l_sum, n = time.time(), 0.0, 0
for batch in data_iter:
center, context_negative, mask, label = [d.to(device) for d in batch]
pred = skip_gram(center, context_negative, net[0], net[1])
l = loss(pred.view(label.shape), label, mask).mean() # 一个batch的平均loss
optimizer.zero_grad()
l.backward()
optimizer.step()
l_sum += l.cpu().item()
n += 1
print('epoch %d, loss %.2f, time %.2fs'
% (epoch + 1, l_sum / n, time.time() - start))
train(net, 0.01, 5)
def get_similar_tokens(query_token, k, embed):
'''
@params:
query_token: 给定的词语
k: 近义词的个数
embed: 预训练词向量
'''
W = embed.weight.data
x = W[token_to_idx[query_token]]
# 添加的1e-9是为了数值稳定性
cos = torch.matmul(W, x) / (torch.sum(W * W, dim=1) * torch.sum(x * x) + 1e-9).sqrt()
_, topk = torch.topk(cos, k=k+1)
topk = topk.cpu().numpy()
for i in topk[1:]: # 除去输入词
print('cosine sim=%.3f: %s' % (cos[i], (idx_to_token[i])))
get_similar_tokens('chip', 3, net[0])
3.词嵌入进阶

GloVe 模型


KNN求近义词
def knn(W, x, k):
'''
@params:
W: 所有向量的集合
x: 给定向量
k: 查询的数量
@outputs:
topk: 余弦相似性最大k个的下标
[...]: 余弦相似度
'''
cos = torch.matmul(W, x.view((-1,))) / (
(torch.sum(W * W, dim=1) + 1e-9).sqrt() * torch.sum(x * x).sqrt())
_, topk = torch.topk(cos, k=k)
topk = topk.cpu().numpy()
return topk, [cos[i].item() for i in topk]
def get_similar_tokens(query_token, k, embed):
'''
@params:
query_token: 给定的单词
k: 所需近义词的个数
embed: 预训练词向量
'''
topk, cos = knn(embed.vectors,
embed.vectors[embed.stoi[query_token]], k+1)
for i, c in zip(topk[1:], cos[1:]): # 除去输入词
print('cosine sim=%.3f: %s' % (c, (embed.itos[i])))
get_similar_tokens('chip', 3, glove)
def get_analogy(token_a, token_b, token_c, embed):
'''
@params:
token_a: 词a
token_b: 词b
token_c: 词c
embed: 预训练词向量
@outputs:
res: 类比词d
'''
vecs = [embed.vectors[embed.stoi[t]]
for t in [token_a, token_b, token_c]]
x = vecs[1] - vecs[0] + vecs[2]
topk, cos = knn(embed.vectors, x, 1)
res = embed.itos[topk[0]]
return res
get_analogy('man', 'woman', 'son', glove)
参考文献:
https://www.kesci.com/org/boyuai/project/5e47c7ac17aec8002dc5652a
https://www.kesci.com/org/boyuai/project/5e48088d17aec8002dc5f4ab
https://www.kesci.com/org/boyuai/project/5e48089f17aec8002dc5f4d0