【笔记】串的模式匹配算法
- 一BF算法
- BF算法思想
- BF算法实现C语言
- 二KMP算法
- KMP算法思想
- next函数的算法
- KMP算法的实现C语言
- 三模式匹配应用举例
串的模式匹配也称为子串的定位操作,即查找子串在主串中出现的位置。设有主串S和子串T,如果在主串S中找到一个与子串T相相等的串,则返回串T的第一个字符在串S中的位置。其中,主串S又称为目标串,子串T又称为模式串。本文主要介绍两种常用的模式匹配算法,即朴素模式匹配算法——BF算法和改进算法——KMP算法。
一、BF算法
1.BF算法思想
BF算法思想是从主串 S=“s0s1…sn−1” 的第pos个字符开始与模式串 T=“t0t1…tm−1” 的第一个字符比较,如果相等则继续逐个比较后续字符;否则从主串的下一个字符开始重新与模式串T的第一个字符比较,依此类推。如果在主串S中存在与模式串T相等的连续字符序列,则匹配成功,函数返回模式串T中第一个字符在主串中S中的位置;否则函数返回-1表示匹配失败。
假设主串为S=“ababcabcacbab”,模式串T=“abcac”,S的长度为n=13,T的长度为m=5。用变量i表示主串S中当前正在比较字符的下标,变量j表示子串T中当前正在比较字符的下标。模式匹配过程如下图所示。

BF算法简单且容易理解,并且进行某些文本处理时,效率也比较高;然后在有些情况下,则效率很低。下面分析其时间复杂性。设串S长度为n,串T长度为m。匹配成功的情况下,考虑两种极端情况:
- 最好情况下
在最好情况下,每趟不成功的匹配都发生在第一对字符比较时。例如:
s=“aaaaaaaaaabc”,t=“bc”
设匹配成功发生在 si 处,则字符比较次数在前面i-1趟匹配中共比较了i-1次,第i趟成功的匹配共比较了m次,所以总共比较了i-1+m次,所有匹配成功的可能共有n-m+1种。设从 si 开始与t串匹配成功的概率为 pi ,在等概率的情况下 pi=1n−m+1 ,因此最好情况下平均比较的次数是1n−m+1∑i=1n−m+1(i−1+m)=12(n+m)
即最好情况下的时间复杂性是 O(n+m) 。
- 最坏情况下
在最坏情况下,每趟匹配不成功的匹配都发生在t的最后一个字符。例如:
s=“aaaaaaaaaaab”,t=“aaab”
设匹配成功发生在 si 处,则在前面i-1趟匹配中共比较了(i-1)*m次,第i趟成功的匹配共比较了m次,所以总共比较了i*m次,共需要进行n-m+1趟比较。因此最坏情况下,的平均比较次数是1n−m+1∑i=1n−m+1im=m(n−m+2)2
即最坏情况下的时间复杂性是 O(n∗m) 。
2.BF算法实现(C语言)
假设串采用顺序存储方式存储,则BF匹配算法如下:
int B_FIndex(SeqString S,int pos,SeqString T)
/*BF模式匹配算法。在主串S中的第pos个位置开始查找子串T,如果找到返回子串在主串的位置;否则,返回-1*/
{
int i,j;
i=pos-1;
j=0;
while(ilength&&jlength)
{
if(S.str[i]==T.str[j]) /*如果串S和串T中对应位置字符相等,则继续比较下一个字符*/
{
i++;
j++;
}
else /*如果当前对应位置的字符不相等,则从串S的下一个字符开始,T的第0个字符开始比较*/
{
i=i-j+1;
j=0;
}
}
if(j>=T.length) /*如果在S中找到串T,则返回子串T在主串S的位置*/
return i-j+1;
else
return -1;
} 在BF算法中,即使主串与模式串已有多个字符经过比较相等,只要有一个字符不相等,就需要将主串的比较位置回退。
二、KMP算法
KMP算法在BF算法的基础上有较大的改进,可在O(m+n)时间数量级上完成串的模式匹配,主要是消除了主串指针的回退,使算法效率有了很大程度的提高。
1.KMP算法思想
KMP算法的基本思想是在每一趟匹配过程中出现字符不等时,不需要回退主串的指针,而是利用已经得到前面“部分匹配”的结果,将模式串向右滑动若干个字符后,继续与主串中的当前字符进行比较。
假设主串S=“ababcabcacbab”,模式串T=“abcac”,KMP算法匹配过程如下左图所示。
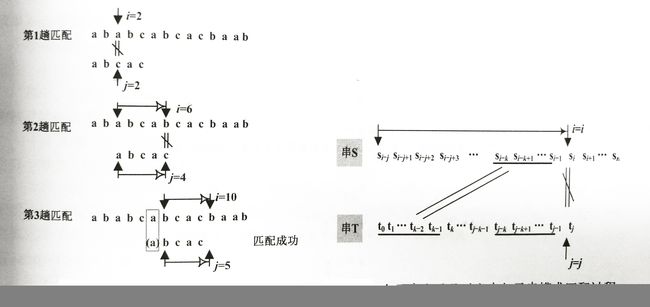
从图中可以看出,KMP算法的匹配次数由BF算法的6趟减少为3趟。在整个KMP算法中,主串i指针没有回退。
下面讨论一般情况。假设主串 S=“s0s1…sn−1” ,模式串 T=“t0t1…tm−1” 。在模式匹配过程中,如果出现字符不匹配的情况,即当 Si≠Tj(0≤i<n,0≤j<m) 时,有
假设子串即模式串存在可重叠的真子串,即
即子串中存在从 t0 开始到 tk−1 与从 tj−k 到 tj−1 的重叠子串。根据上面两个等式,可以得出 “si−ksi−k+1…si−1”=“t0t1…tk−1” ,如上右图所示。
匹配过程中,当主串中的第i+1个字符与模式串中的第j+1个字符不等时,仅需将模式串向右滑动至第k+1个字符与主串中的第i+1个字符对齐,即 si 与 tj 对齐, 此时,模式串中子串 “t0t1…tk−1” 必定与主串中的子串 “si−ksi−k+1…si−1” 相等,因此匹配只需从第i+1个字符与模式串中的第k+1个字符开始比较。
如果令next[j]=k,则next[j]表示当模式串中的第j个字符与主串中的对应的字符不相等时,在模式串中需要重新与主串中与该字符进行比较的字符的位置。模式串中的next函数定义如下:
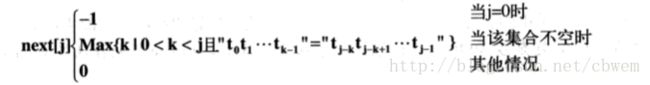
其中第一种情况,next[j]的函数是为了方便算法设计而定义的;第二种情况,如果子串中存在重叠的真子串,则next[j]的取值就是k,即模式串的最长子串的长度;第三种情况,如果模式串中不存在重叠的子串,则从子串的第一个字符开始比较。
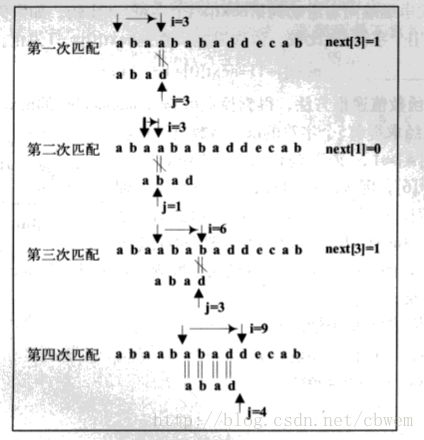
KMP算法的模式匹配过程:如果模式串T中存在真子串 “t0t1…tk−1”=“tj−ktj−k+1…tj−1” ,当模式串T的 tj 与主串S的 si 不相等,则按照next[j]=k将模式串向右滑动,从主串中的 si 与模式串的 tk 开始比较;如果 si=tk ,则主串与模式串的指针各自增1,继续比较下一个字符;如果 si≠tk ,则按照next[next[j]]将模式串继续向右滑动,将主串中的 si 与模式串中的next[next[j]]字符进行比较;如果仍然不相等,则按照以上方法,将模式串继续向右滑动,直到next[j]=-1。这时,模式串不再向右滑动,从 si+1 开始与 t0 进行比较。
利用next函数值的一个模式匹配示例如下图所示。
2.next函数的算法
- 求next函数值
模式串中的next函数值的取值与主串无关,仅与模式串有关,根据模式串next函数定义,next函数值可用递推的方法得到。
设next[j]=k,表示在模式串T中存在以下关系:
其中, 0<k<j ,k为满足等式的最大值,即不可能存在 k′>k 满足以上等式。则计算next[j+1]的值会出现两种情况:
(1)如果 ti=tk ,则表示在模式串T中满足关系 “t0t1…tk”=“tj−ktj−k+1…tj” ,并且不可能存在 k′>k 满足以上等式。因此有next[j+1]=k+1,即next[j+1]=next[j]+1。
(2)如果 ti≠tk ,则表示在模式串T中满足关系 “t0t1…tk”≠“tj−ktj−k+1…tj” 。在这种情况下,可以把求next函数值的问题看成一个模式匹配的问题。目前已经有 “t0t1…tk−1”=“tj−ktj−k+1…tj−1” ,但是 ti≠tk ,把模式串T向右滑动到k’=next[k]。
如果有 tj=tk′ ,则表示模式串中有 “t0t1…tk′”=“tj−k′tj−k′+1…tj” ,因此有next[j+1]=k’+1,即next[j+1]=next[k]+1。
如果有 tj≠tk′ ,则将模式串继续向右滑动到第next[k’]个字符与 tj 比较。如果仍不相等,则将模式串继续向右滑动到下表为next[next[k’]]字符与 tj 比较。依此类推,直到 tj 和模式串中某个字符匹配成功或不存在任何 k′(1<k′<j) 满足 “t0t1…tk′”=“tj−k′tj−k′+1…tj” ,则有next[j+1]=0。
- 改进的求next函数值算法
一般地,在求得next[j]=k后,如果模式串中的 tj=tk ,则当主串中的 si≠tk 时,不必再将 si 与 tk 比较,而是直接与 tnext[k] 比较。因此可以将求next函数值的算法进行修正,即在求得next[j]=k后,判断 tj 是否等于 tk ,如果相等,还需继续将模式串向右滑动,使k’=next[k],判断 tj 是否等于 tk′ ,直到两者不等为止。
3.KMP算法的实现(C语言)
- KMP模式匹配算法
利用模式串T的next函数值求T在主串S中的第pos个字符之后的位置的KMP算法描述如下:
int KMP_Index(SeqString S,int pos,SeqString T,int next[])
/*KMP模式匹配算法。利用模式串T的next函数在主串S中的第pos个位置开始查找子串T,如果找到返回子串在主串的位置;否则,返回-1*/
{
int i,j;
i=pos-1;
j=0;
while(ilength&&jlength)
{
if(j==-1||S.str[i]==T.str[j]) /*如果j=-1或当前字符相等,则继续比较后面的字符*/
{
i++;
j++;
}
else /*如果当前字符不相等,则将模式串向右移动*/
j=next[j];
}
if(j>=T.length) /*匹配成功,返回子串在主串中的位置。否则返回-1*/
return i-T.length+1;
else
return -1;
} - 求next函数值的算法:
int GetNext(SeqString T,int next[])
/*求模式串T的next函数值并存入数组next*/
{
int j,k;
j=0;
k=-1;
next[0]=-1;
while(jlength)
{
if(k==-1||T.str[j]==T.str[k]) /*如果k=-1或当前字符相等,则继续比较后面的字符并将函数值存入到next数组*/
{
j++;
k++;
next[j]=k;
}
else /*如果当前字符不相等,则将模式串向右移动继续比较*/
k=next[k];
}
} 求next函数值的算法时间复杂度是O(m)。一般情况下,模式串的长度比主串的长度要小得多,因此对整个字符串的匹配来说,增加这点事件是值得的。
- 改进的求next函数值的算法:
int GetNextVal(SeqString T,int nextval[])
/*求模式串T的next函数值的修正值并存入数组next*/
{
int j,k;
j=0;
k=-1;
nextval[0]=-1;
while(jif(k==-1||T.str[j]==T.str[k]) /*如果k=-1或当前字符相等,则继续比较后面的字符并将函数值存入到nextval数组*/
{
j++;
k++;
if(T.str[j]!=T.str[k]) /*如果所求的nextval[j]与已有的nextval[k]不相等,则将k存放在nextval中*/
nextval[j]=k;
else
nextval[j]=nextval[k];
}
else /*如果当前字符不相等,则将模式串向右移动继续比较*/
k=nextval[k];
}
} 三、模式匹配应用举例
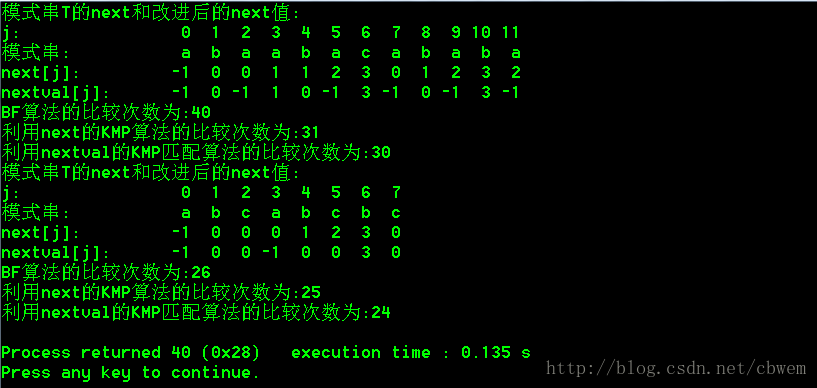
编程比较BF算法和KMP算法的效率。例如主串S=“cabaadcabaababaabacabababab”,模式串T=“abaabacababa”,统计BF算法和KMP算法在匹配过程中的比较次数,并输出模式串的next函数值与nextval函数值。
- 主函数
/*包含头文件*/
#include- BF算法
int B_FIndex(SeqString S,int pos,SeqString T,int *count)
/*BF模式匹配算法。在主串S中的第pos个位置开始查找子串T,如果找到返回子串在主串的位置;否则,返回-1*/
{
int i,j;
i=pos-1;
j=0;
*count=0; /*count保存主串与模式串的比较次数*/
while(iif(S.str[i]==T.str[j]) /*如果串S和串T中对应位置字符相等,则继续比较下一个字符*/
{
i++;
j++;
}
else /*如果当前对应位置的字符不相等,则从串S的下一个字符开始,T的第0个字符开始比较*/
{
i=i-j+1;
j=0;
}
(*count)++;
}
if(j>=T.length) /*如果在S中找到串T,则返回子串T在主串S的位置*/
return i-j+1;
else
return -1;
} - KMP算法
int KMP_Index(SeqString S,int pos,SeqString T,int next[],int *count)
/*KMP模式匹配算法。利用模式串T的next函数在主串S中的第pos个位置开始查找子串T,如果找到返回子串在主串的位置;否则,返回-1*/
{
int i,j;
i=pos-1;
j=0;
*count=0; /*count保存主串与模式串的比较次数*/
while(ilength&&jlength)
{
if(j==-1||S.str[i]==T.str[j]) /*如果j=-1或当前字符相等,则继续比较后面的字符*/
{
i++;
j++;
}
else /*如果当前字符不相等,则将模式串向右移动*/
j=next[j];
(*count)++;
}
if(j>=T.length) /*匹配成功,返回子串在主串中的位置。否则返回-1*/
return i-T.length+1;
else
return -1;
}
int GetNext(SeqString T,int next[])
/*求模式串T的next函数值并存入数组next*/
{
int j,k;
j=0;
k=-1;
next[0]=-1;
while(jlength)
{
if(k==-1||T.str[j]==T.str[k]) /*如果k=-1或当前字符相等,则继续比较后面的字符并将函数值存入到next数组*/
{
j++;
k++;
next[j]=k;
}
else /*如果当前字符不相等,则将模式串向右移动继续比较*/
k=next[k];
}
}
int GetNextVal(SeqString T,int nextval[])
/*求模式串T的next函数值的修正值并存入数组next*/
{
int j,k;
j=0;
k=-1;
nextval[0]=-1;
while(jlength)
{
if(k==-1||T.str[j]==T.str[k]) /*如果k=-1或当前字符相等,则继续比较后面的字符并将函数值存入到nextval数组*/
{
j++;
k++;
if(T.str[j]!=T.str[k]) /*如果所求的nextval[j]与已有的nextval[k]不相等,则将k存放在nextval中*/
nextval[j]=k;
else
nextval[j]=nextval[k];
}
else /*如果当前字符不相等,则将模式串向右移动继续比较*/
k=nextval[k];
}
}
朴素的BF算法也是常用的算法,毕竟它不需要计算next函数值。KMP算法在模式串与主串存在许多部分匹配的情况下,其优越性才会显示出来。
- 测试结果