HBASE memstore(跳跃表)底层结构,,实现过程和原理,MSLAB对memstore的GC优化
目录
跳跃表:
定义
查找
插入
删除
MSLAB
memstoreGC问题
MLSAB相关配置
Chunk Pool配置
hbase系统中一张表会被水平切分成多个region。每个region负责自己区域的数据读写请求。hbase针对每个列簇都将数据保存在store。每个store由一个memstore和多个hfile组成。
因为memstore底层的存储结构是跳跃表(ConcurrentSkipListMap)。我们先理解一下跳跃表的知识。
跳跃表
跳跃表是一种能高效实现插入,删除,查找的内存数据结构。与红黑树以及二分法相比,跳跃表的优势在于实现简单,可以实现更高的并发性。在redis(zset),kafka hbase等都把跳跃表作为一种维护有序数据集合的基础数据结构。
跳跃表的基础是链表。但是由于链表的查找复杂度太高,因为链表在查询的时候,需要逐个元素的查找,所以,跳跃表在链表的基础上避免了依次查找元素,那么查找复杂度将降低了很多。
定义:
- 跳跃表由多条分层的链表组成。
- 每条链表的元素都是有序的。
- 每条链表都有两个元素 +∞ (正无穷大)和-∞(负无穷大).分别表示链表的头部和尾部。
- 跳跃表的高度定义为水平链表的层数。
如图所示: 6层的跳跃表
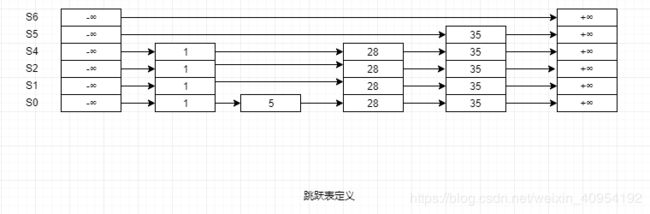
查找跳跃表
- 如果发现查找的currentNode后续节点的值小于等于待查询的值,则沿着这条链表向后查询。
- 如果后续节点大于要查找的值,则切换到当前节点的下层链表继续查找,接着上层查找到的节点继续查找
- 直到查找到待查询值为止。
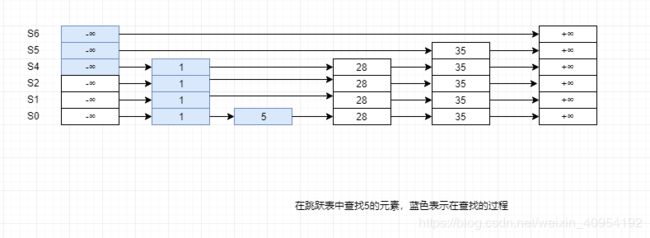
插入跳跃表
- 需要按照上述的查找过程找到待插入元素的前驱和后继。
- 根据随机算法生成一个高度值。
public void randomHeight(double p){
int height = 0;
while (random.nextDouble() < p ) height ++;
return height +1;
}3. 将待插入节点按照高度值生成一个垂直节点(这个节点的层数正好等于高度值),之后插入到跳跃表的多条链表中
这里分两种情况讨论:
1.如果height大于跳跃表的高度,那么跳跃表的高度被提升为height.同时需要更新头部节点和尾部节点的指针指向。
2.如果height小于等于跳跃表的高度,那么需要更新待插入元素前驱和后继的指针指向。

删除跳跃表
删除操作和查找类似,这里不做阐述。
好了,接下来进入正题
这里要说一下,LSM树是一种磁盘数据的索引结构,本质和B+树一样,不同的是 LSM对写入请求更加友好。LSM树的索引一般由两部分组成。一部分是内存部分,一部分是磁盘部分。内存部分采用跳跃表来维护一个有序的KV集合,也就是memstore.
在实际实现过程中,hbase的memstore其实是由两个ConcurrentSkipListMap构成。写入操作(包括更新删除)会将数据写入ConcurrentSkipListMapA,当ConcurrentSkipListMapA中数据量超过一定阈值之后会创建一个新的ConcurrentSkipListMapB来接收用户新的请求。之前写满的ConcurrentSkipListMapA会执行异步的flush操作落盘形成Hfile.
MSLAB
memstoreGC问题
因为memstore本质上可以被称为写缓存。所以涉及到内存,少不了GC问题。因为一个regionServer由多个Region组成。每个region根据列簇又包含多个memstore.这些memstore是共享内存的。不同region的数据写入对应的memstore,但是对于JVM来说,实则所有的memstore数据都是混在一起写入的Heap.所以假设某个region上对应的memstore执行flush,那么内存就会产生碎片问题。
为了优化内存碎片带来的FullGC,hbase采用了MSLAB内存管理方式。
- 每个memstore会实例化得到一个MemStoreLAB对象。
- MemStoreLAB会申请一个2M大小的Chunk数组,同时维护一个Chunk偏移量。该偏移量初始值为0.
- 当memStore有新的KV数据插入时,通过KeyValue.getBuffer()得到data数组,并将data数组复制到Chunk数组中,并增加偏移量为=之前偏移量+data.length
- 当前Chunk数组满了之后,在调用 new Byte[2*1024*1024]申请一个新的Chunk数组
这样子2M的Chunk的数据在内存中是在一起的,以至于相比之前,flush之后残留的内存碎片更加粗粒度化。
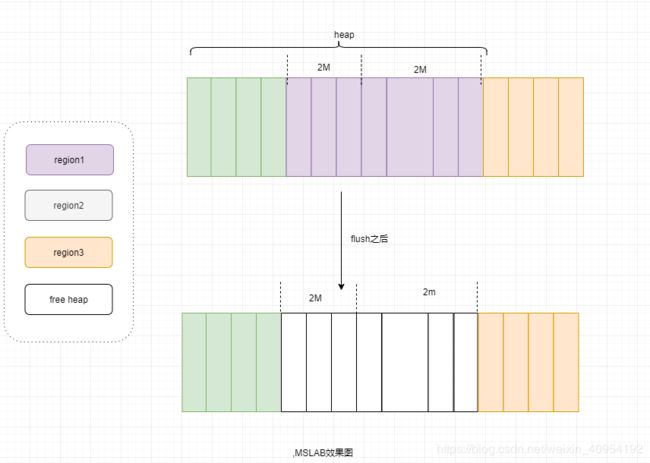
经过MSLAB优化之后,系统因为memstore内存碎片触发的Full Gc次数明显降低。但是还是有一些小问题,比如一旦Chunk数组写满之后,系统会重新申请一个新的Chunk,新建Chunk对象会在JVM新生代申请新内存。如果申请比较频繁,会导致JVM新生代Eden区满掉,触发ygc。为了解决这个问题,引出了MemStore Chunk Pool。具体步骤如下:
- 系统创建一个Chunk Pool来管理所有未被引用的Chunk.这些Chunk就不会在被JVM当作垃圾回收。
- 如果一个Chunk没有在被引用,将其放入Chunk Pool.
- 如果当前Chunk Pool已经达到了容量最大值,就不会在接受新的Chunk.
- 如果需要申请新的Chunk来存储KV,首先从Chunk Pool中获取,如果能够获取到就重复利用,如果获取不到就申请一个新的Chunk.
MLSAB相关配置
hbase.hregion.memstore.mslab.enabled=true // 开启MSALB
hbase.hregion.memstore.mslab.chunksize=2m // chunk的大小,越大内存连续性越好,但内存平均利用率会降低
hbase.hregion.memstore.mslab.max.allocation=256K // 通过MSLAB分配的对象不能超过256K,否则直接在Heap上分配,256K够大了
Chunk Pool配置
hbase.hregion.memstore.chunkpool.maxsize = [0,1] 0-1之间取值。默认是0,大于0才会开启,表示占比
hbase,hregion,memstore.chunkpool.initialsize=[0,1] 0-1之间取值,默认0,表示初始化时申请多少个chunk放入到chunkPool