WIN10+CUDA10.1环境下Keras-YoloV3训练教程(超简单!)
WIN10+CUDA10.1环境下Keras-YoloV3训练教程
- 环境配置
- 准备过程
- 数据集标注过程
- 数据集准备过程:
- 一
- 二
- 训练过程
- 测试过程
- 最后
环境配置
CUDA和Keras的安装可以参考我的上一篇博客这是链接。
需要注意的是,Tensorflow有GPU和CPU两个版本。
如果我们同时安装了CPU和GPU版本,此时安装Keras,会默认安装CPU的版本的Keras,无法使用GPU进行加速训练。
解决方法就是先卸载Tensorflow,只用pip安装GPU版本,然后再pip安装Keras即可。
准备过程
数据集标注过程
Keras版本YOLOV3使用的VOC格式的数据集,也就是标注文件后缀为xml,我们使用LabelImg标注即可
注:Windows下EXE闪退的,直接pip安装labelImg,然后在scipy文件夹内找到EXE即可
如果是Github上下载的文件夹形式,在cmd中运行下列命令
pyrcc5 -o libs/resources.py resources.qrc
python labelImg.py
主界面:

按键说明:
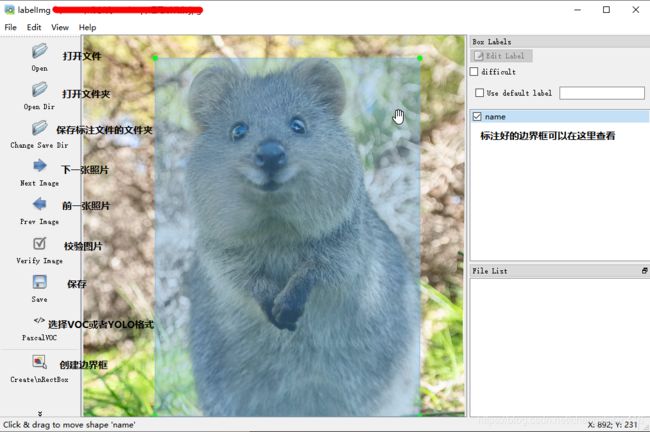
标注好大概是这个样子

数据集准备过程:
一
在keras-yolo3-master文件夹创建VOCdevkit文件夹,并在里面创建JPEGImages,ImageSets,Annotations三个子文件夹。
JPEGImages:将训练用的照片放在这里
Annotations:将标注好的xml文件放在这里
在VOCdevkit文件夹内创建一个python文件
运行以下代码为后面的训练生成训练集,验证集,测试集的路径:
import os
import random
trainval_percent = 0.8
train_percent = 0.8
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/trainval.txt', 'w')
ftest = open('ImageSets/test.txt', 'w')
ftrain = open('ImageSets/train.txt', 'w')
fval = open('ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
在ImageSets文件夹内就可以看到

二
之后在keras-yolo3-master\model_data文件夹内找到voc_classes.txt文件
将里面的名称修改为数据集内类别的名称,注意顺序要一样
在keras-yolo3-master文件夹内创建一个python文件
运行以下代码即可生成训练所需的txt文件
import xml.etree.ElementTree as ET
from os import getcwd
sets=['train','val','test']
classes = ["类别1", "类别2", "类别n"]
def convert_annotation(image_id, list_file):
in_file = open('VOCdevkit/Annotations/%s.xml'%(image_id))
tree=ET.parse(in_file)
root = tree.getroot()
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (int(xmlbox.find('xmin').text), int(xmlbox.find('ymin').text), int(xmlbox.find('xmax').text), int(xmlbox.find('ymax').text))
list_file.write(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id))
wd = getcwd()
for image_set in sets:
image_ids = open('VOCdevkit/ImageSets/%s.txt'%(image_set)).read().strip().split()
list_file = open('%s.txt'%(image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/JPEGImages/%s.jpg'%(wd,image_id))
convert_annotation(image_id, list_file)
list_file.write('\n')
list_file.close()
在keras-yolo3-master文件夹内会生成train.txt,val.txt,test.txt
至此,准备过程就完成啦
训练过程
训练可以有三种方式:
1.在keras-yolo3-master文件夹内运行cmd,输入python train.py即可 (推荐)
2.使用IDLE打开train.py运行 (不推荐,训练过程会输出大量信息(不会覆盖形成进度条),即使GPU,CPU强劲,训练也会越来越慢)
3.使用pycharm打开train.py运行 (个人不到万不得已不会使用pycharm,缓存太大了)
测试过程
在keras-yolo3-master文件夹内运行cmd,
输入python yolo_video.py --image测试图片
输入python yolo_video.py --input 视频文件相对路径测试视频
最后
如果哪里写的有问题或者还有不足,可以留言提提意见,我会马上修改!