显著性检测2018(ECCV, CVPR)【part-1】
1.《Salient Object Detection Driven by Fixation Prediction》
ASNet 网络结构图如下:
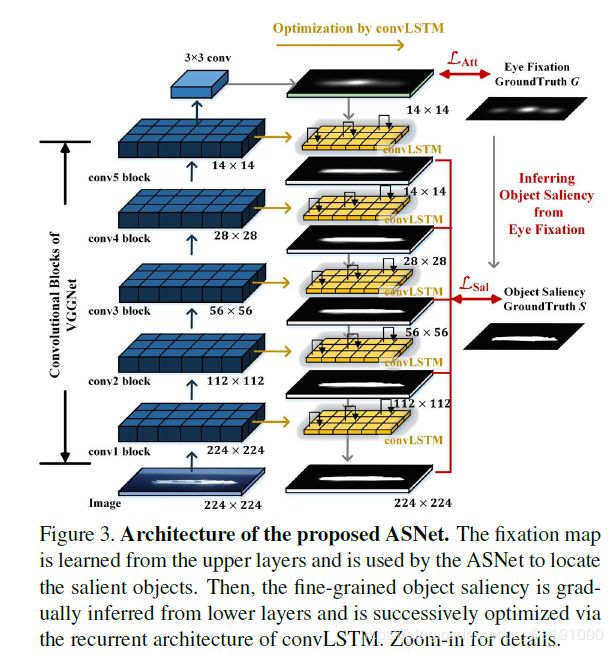
其中,具体的模块连接实现如下图:

(1)创造性地将Fixation Prediction任务和Salient Object Detection任务结合起来,通过左边特征提取器top-layer(全局语义信息丰富)得到Fixation Map,并用于指引Salient Map的预测。具体的,采用top-down形式,从上到下不断融合low-level信息优化Salient Map. (ConvLSTM应用于静态图上可有助于迭代优化保留显著特征)
(2)FP部分损失函数为Kl散度(类似于交叉熵损失)

SOD部分根据其评价指标Precision, Recall, F-Measure-scores, MAE,创造性地提出相对应的损失函数,加强模型训练。具体的,SOD损失函数如下:

其中,第一部分为SOD常见损失,Weighted Cross-Entropy,后四部分为相应新提出的损失函数


(3)FP和SOD任务合二为一,相互促进,二者的数据集都可用来训练ASNet. 但是,不是所有的数据集都有两者任务的label。如图:
所以,具体训练时,加入yA和yS,二者均取值0或1.用来标记当前训练图片是否有FP或SOD的label.
评估指标得分:
| DataSet | F-Score | MAE |
|---|---|---|
| ECCSD | 0.928 | 0.043 |
| HKU-IS | 0.920 | 0.035 |
| PASCAL-S | 0.857 | 0.072 |
2.《A Bi-directional Message Passing Model for Salient Object Detection》
BMPM网络结构图如下:
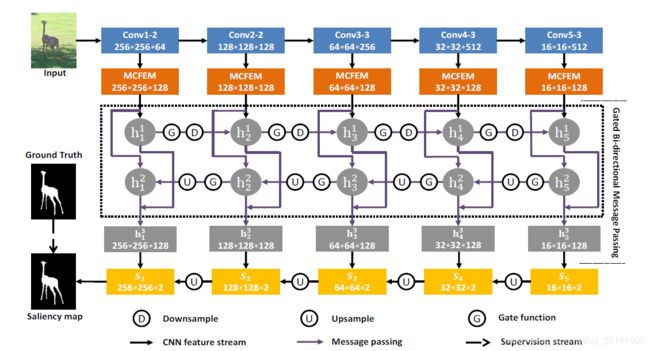
主要创新点在于提出两个模块实现 Multi-Scale 和 Multi-Level。
(1)Multi-scale Context-aware Feature Extraction Module (MCFEM模块),对特征提取backbone的每一个level做4次空洞卷积(空洞率为1,3,5,7),以此改变感受野的大小进而获取Multi-scale特征。 卷积核尺寸为3*3,32个。将4次卷积结果(即4个尺寸特征)concatenate,得到128维特征。
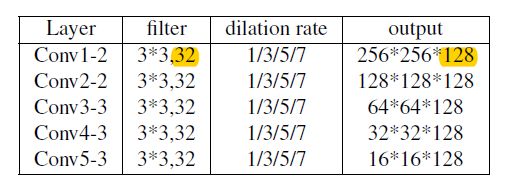
(2)Gated Bi-directional Message Passing Module (GBMPM模块)
本文最大创新点即在于提出该双向特征流通模块,高层语义特征可以传给低层,低层空间特征也可丰富高层信息,使得每个level的特征都丰富起来。门控网络还可在流通过程中实现特征的选择。
(3)采用top-down形式预测显著图,每个level都给出预测,并且高层的预测叠加到低层上,最低层的预测S1即为显著图最终预测结果。采用交叉熵损失函数计算最终预测图和ground truth损失。

评估指标得分:
| DataSet | F-Score(max) | MAE |
|---|---|---|
| ECSSD | 0.928 | 0.044 |
| HKU-IS | 0.920 | 0.038 |
| PASCAL-S | 0.862 | 0.074 |
| SOD | 0.851 | 0.106 |
| DUTS-test | 0.850 | 0.049 |
3.《Progressive Attention Guided Recurrent Network for Salient Object Detection》
PAGR网络结构图如下:
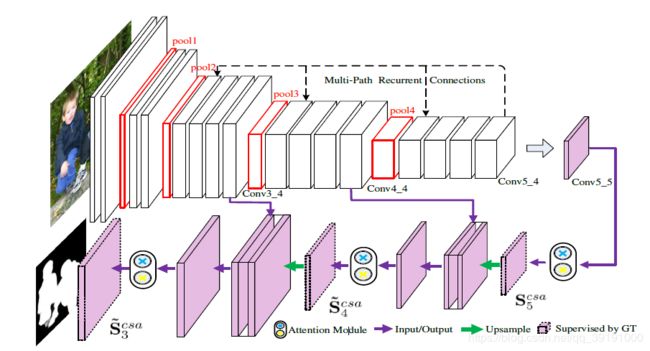
(1)top-down形式,使用注意力机制指导融合Multi-level特征,逐步优化显著预测图
(2)采取多路循环反馈机制,将top layer 特征传给shallower layers,不断优化网络
具体的:
【1】注意力模块(联合channel-wise 和 spatial attention )如下:

【2】逐步注意力指导模块(Progressive Attention Guidance Module)

顶层(L层)的注意力操作后的特征上采样与低一层(L-1层)特征相加融合,融合后的L-1层特征再经过注意力模块和上采样后与L-2层特征融合……以此类推。每层都根据注意力后的特征预测显著图(受到Ground Truth 监管)。
自上而下通过注意力机制不断融合高层和低层特征,越往下得到越优的显著图预测效果。将最后一级(S3)输出的预测图作为最终预测结果。
【3】多路循环反馈指导模块(MultiPath Recurrent Guidance Module)

该模块不是独立的模块,上图只是为了更好的解释。实际上,就是在完成一次模型预测(t=1)后,通过图1的虚线进行反馈,(t=2)反馈操作具体为产生灰色模块,与原本网络模型相应模块相加然后继续前馈传播,得到新的显著图预测。依次可不断循环迭代执行t=3,4,5……不断优化网络和预测结果。
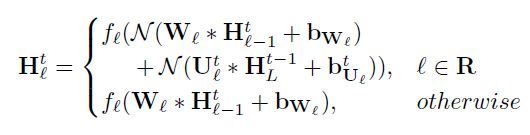
作者通过实验证明,图1的连接方法(连接Conv5-1,4-1,3-1),循环1次,即T=2,有最优预测结果输出。
评估指标得分:
| DataSet | F-Score | MAE |
|---|---|---|
| ECSSD | 0.891 | 0.064 |
| HKU-IS | 0.886 | 0.048 |
| THUR15K | 0.729 | 0.070 |
| PASCAL-S | 0.803 | 0.092 |
| DUT-OMRON | 0.711 | 0.072 |
| DUTS | 0.788 | 0.055 |
4.《Reverse Attention for Salient Object Detection》
RAS网络结构图如下:

(1)同样是top-down形式不断融入低层特征,优化显著图预测输出。每个level给出的预测都受Ground Truth的监管。不同的是融合方法,参用基于反向注意模块的残差学习方法融合补充低层特征。
采用残差学习方式:即L-1层显著图=L层显著图+补充特征。该方法方便实现特征补充,同时保证L-1层显著图不会比L层差。补充特征由反向注意力模块+卷积操作实现。
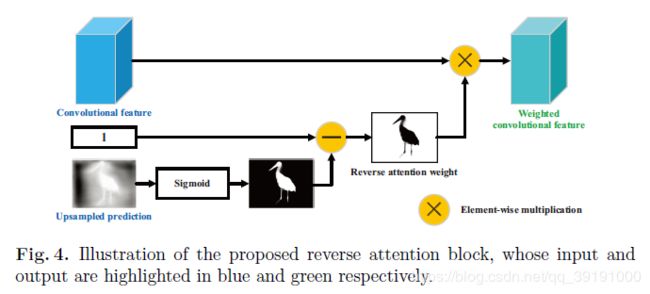
反向注意力模块如下:参用Erase的思想,将高层的显著部分擦掉,即将显著图黑白反转,得到反向注意力权重(注意非显著部分)并与特征相乘,获得Weighted convolutional feature.
这样做的原因是:残差学习方式确保了高层的显著部分可以通过skip-connection直接保存,所以该模块应该在高层非显著部分进行补充特征的找寻。因为有Ground Truth的监管学习,最终会补充那些本属于显著部分却没有被高层找到的边缘部分特征信息,从而进一步优化该层的显著预测图。
评估指标得分:
| DataSet | F-Score(max) | MAE |
|---|---|---|
| ECSSD | 0.918 | 0.059 |
| HKU-IS | 0.913 | 0.045 |
| MSRA-B | 0.931 | 0.036 |
| PASCAL-S | 0.834 | 0.104 |
| DUT-OMRON | 0.786 | 0.062 |
| SOD | 0.844 | 0.124 |
5.《PiCANet: Learning Pixel-wise Contextual Attention for Saliency Detection》
提出了Global 和 Local 两个PiCANet模块,用于整合全局和局部上下文信息,融入到原有UNet网络中,提升整体效果。

(1)Global PiCANet
使用ReNet, 具体的,在水平和竖直方向均使用双向LSTM(biLSTM),以此捕获4个方向的信息,进而使每个像素拥有全局上下文环境。
对ReNet网络的输出的feature map,reshape为D个channel,D=W×H(即像素点总数),这样每个像素位置的特征向量,都是该像素对全局像素的响应关系。于是:通过softmax就可得到针对当前像素,全局像素的对应响应权重(关联程度)。

进而通过attention value 与对应全局特征相乘,更新当前像素的特征:

(2)Local PiCANet
通过卷积操作使得感受野大小为局部大小(W~×H~),来实现局部信息相关性的捕获。同上,reshpae 相关性特征channel 为 D~ =W~×H~, 然后softmax得到attention map,与对应特征相乘更新当前像素点特征。
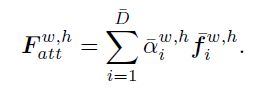
(3)完整的显著性检测网络基于UNet,并加入上述PiCANet模块。

采用深度监管策略,每个Decoder都给出预测,并于Ground Truth计算交叉熵loss.
总结:
除了各自的创新之外,上述5篇论文还有一些可以对比分析的共同点和不同点。这5篇论文都是基于FCN模型的,采取bottom-up给出high-level预测,top-down形式不断融合低层特征优化显著图预测输出。其中1,3,4,5篇论文皆采用Ground Truth中间监督策略,优化指导每层显著图的预测结果,第2篇论文仅用Ground Truth对最终的显著预测图计算损失进行优化。
不同的是高低层特征的融合方法。第1篇:参用ConvLSTM; 第2篇:采用双向信息传播;第3篇:采用注意力机制;第4篇:采用基于反向注意(Erase)的残差学习 第5篇加入关注全局和局部信息的PiCANet模块。
6.《Detect Globally, Refine Locally: A Novel Approach to Saliency Detection》
DGRL网络
创新点:提出global Recurrent Localization Network(RLN) 给出initial saliency map, 然后通过local Boundary Refinement Network (BRN)修正局部边界信息。
(1)Recurrent Localization Network [包括an inception-like Contextual Weighting Module (CWM) and a Recurrent Module (RM)].

a. CWM

为了获得Multi-Scale-Context信息, 使用3个不同卷积核大小的context filters. 经过处理后将结果concate起来,送入卷积层,得到 channel=1的上下文权重响应参数Mk.
![]()
经过softmax, 得到最终响应图。
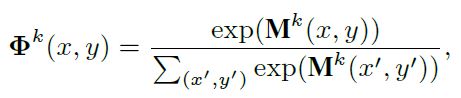
然后对其上采样作用于对于特征上(element-wise production),完成特征更新。©代表第c个channel. 即以channel为单位进行相乘更新特征。
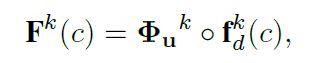
b. RM
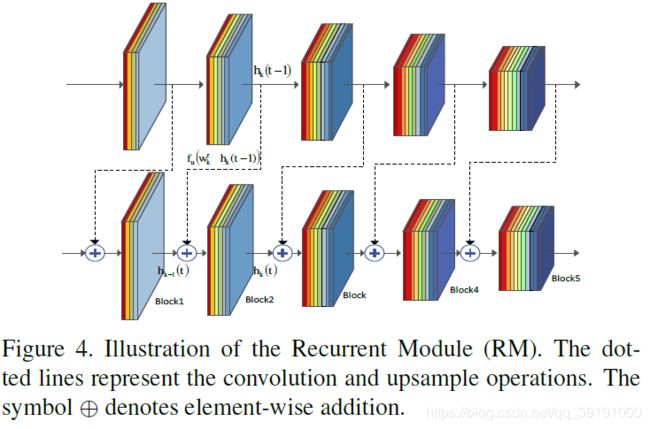
每个block的输入特征由前一个block的当前步的输出特征+该block上一步的输出特征组成。 Wf 和 Wr 代feed-forward 和 recurrent 权重参数。其中, Wf 每步采用共享参数策略, Wr则为每步独立学习,以更优的借助CWM的响应图修正特征。

(2)local Boundary Refinement Network (BRN)

将original input image 和RLN给出的saliency map concate 起来送入BRN模块。对每个位置,BRN产生一个propagation coefficient vector, flat为 n×n 方形。对每个像素位置i, 通过其邻居像素(n×n)与propagation coeffcient Vi相乘求和,更新当前像素i.

相比于initial saliency map, 修正后的saliency map就其外观表面来看不应修改太多,所以作者对BRN模块做了一定的初始化限制,详情参加论文。