python 爬取微博部分评论
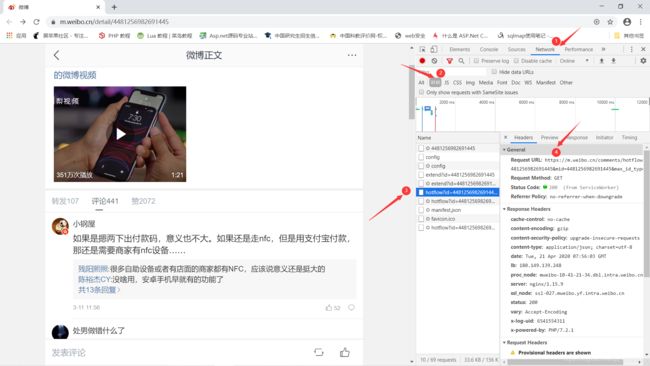
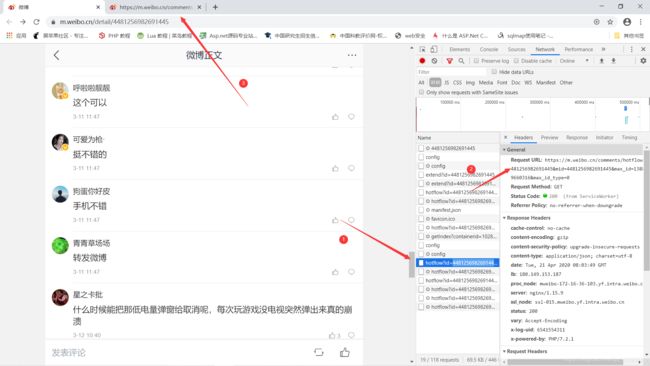
应朋友需求,帮忙爬取一下微博有关Apple pay的评论,我本来也就刚学爬虫,我先查了一下,相关的博文还不少,既然有参考,那一个可以操作操作吧,遇到问题解决问题,至少大方向是正确的,本着这个想法,我答应了朋友。我是参考这篇博文(点击跳转)写的,但是也有所不同,我也是通过手机端的微博网站(点击跳转)进行操作,这是我要爬取的网页(https://m.weibo.cn/detail/4481256982691445)F12分析网页,将滚动条向下滚动,发现新的文章会在底部加载,原来微博的热门文章加载方式是Ajax加载的,那我们就不能在网页源码中找标签了,我们点击如下图所示的network标签,找找请求地址(过程如下图过程)
然后对其进行抓取,json解析,便可以得到想到的信息,我只保存了用户名和评论内容,这就完成了一部分评论的爬取,就在我以为我要结束战斗的时候,我发现我找不到后面评论的地址,准确的说是下图这样的???
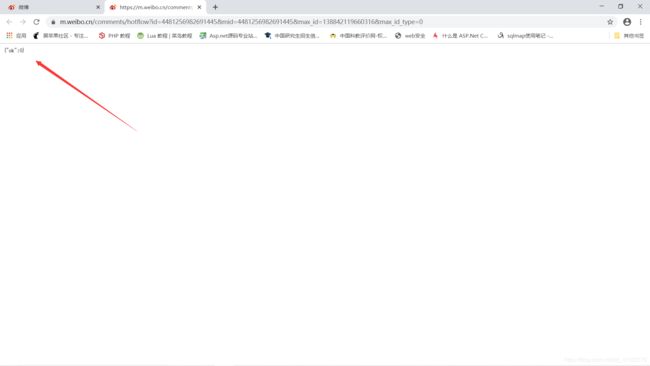
这有什么内容给我抓吗???难道不应该和第一个返回的内容一样吗???

经过我不断的试探,我发现后续的链接有时候进去和第一个一样,有时候就只有一个 {“ok”:0} ,是因为生存周期或者微博的反扒吗???一脸懵逼,我尝试这解析了其他的好多链接
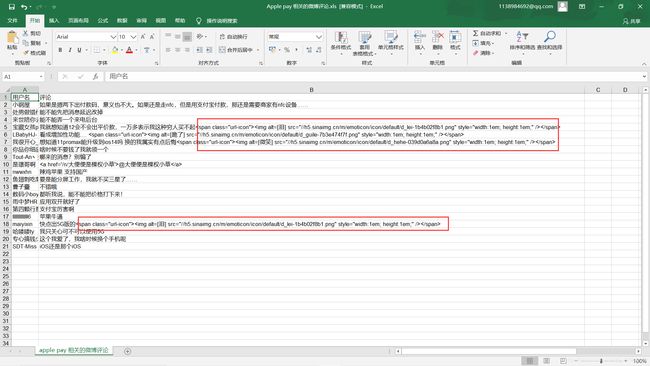
好吧,我也不知道是什么,但好像也不是我要的东西,中午吃完饭到晚上十点(上午在爬其他东西,早上八点开始坐在电脑前,脖子真的是顶不住了)第二天又折腾了会儿,最后也没整出来,就爬取了20条评论,数据处理还没有很到位,先把暂时做到的记录下来,等我以后小有所成了,再回头解决这些问题,再更新博客。
下面是这次不健全的源码和截图:
import requests
import re
from bs4 import BeautifulSoup
import json
import pprint
import xlwt
baseurl = "https://m.weibo.cn/comments/hotflow?id=4481256982691445&mid=4481256982691445&max_id_type=0"
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36",
"Cookie": "_s_tentry=-; Apache=3958831490543.6704.1587343450165; SINAGLOBAL=3958831490543.6704.1587343450165; ULV=1587343450843:1:1:1:3958831490543.6704.1587343450165:; login_sid_t=0be2e3881f12e4dcb4a4695106c23cba; cross_origin_proto=SSL; ALF=1618891479; SSOLoginState=1587355480; SUB=_2A25zmW8IDeRhGeBL71MU9SrPyj2IHXVQ78fArDV8PUNbmtANLRfVkW9NRwc3uGNzYUzlugq_gPwOKZ4J_315YIcN; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5u.wTEvOFxVbauopN-VWqC5JpX5KzhUgL.FoqfSh2fSKB0eK22dJLoIEXLxKqL1hnL1K2LxKnL1h5L1h5LxK-L1hnLBoMLxK-LB.-LB--LxK-L12BL1-2t; SUHB=0gHy5N40LXOuK9; wvr=6; UOR=,,graph.qq.com; webim_unReadCount=%7B%22time%22%3A1587355736838%2C%22dm_pub_total%22%3A0%2C%22chat_group_client%22%3A0%2C%22chat_group_notice%22%3A0%2C%22allcountNum%22%3A41%2C%22msgbox%22%3A0%7D",
}
global username
global text
username = []
text = []
savepath = ".\\Apple pay 相关的微博评论.xls"
def get_comment(data): #获取用户名和评论内容分别存入username[],text[]
#response = requests.get(url, headers=head)
#data = json.loads(response.text)
#print(data["data"]["data"])
#print(type(data["data"]["data"]))
#print(len(data["data"]["data"]))
print("\n--------调用get_comment()----------\n")
for item in data["data"]["data"] :
#print(item["id"],item["text"],sep = "\t",end = "\n")
#print(item["user"],end = "\n")
#print(item["user"]["screen_name"],item["text"],sep = "\t",end = "\n")
username.append(item["user"]["screen_name"])
item["text"].replace(u'(\ud83d[\ude00-\ude4f])|', '.');
text.append(item["text"])
#for x in username:
# print(x)
#def geturllist(url):
# response = requests.get(url, headers=head)
# data = json.loads(response.text)
# pprint.pprint(data["data"])
def save(username,text):
book = xlwt.Workbook(encoding = "utf-8",style_compression = 0)
sheet = book.add_sheet("apple pay 相关的微博评论",cell_overwrite_ok = True)
col = ("用户名","评论")
for i in range(2):
sheet.write(0,i,col[i])
for i in range(len(data["data"]["data"])):
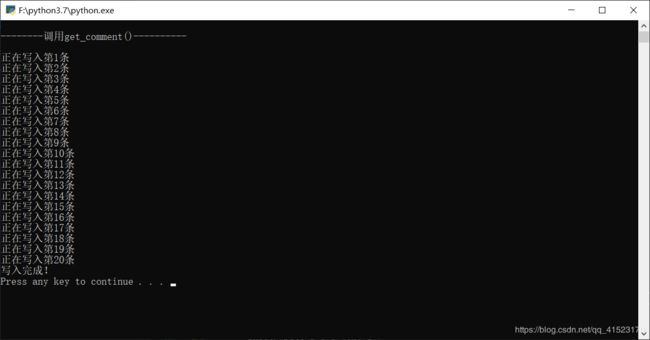
print("正在写入第%d条"%(i+1))
sheet.write(i+1,0,username[i])
sheet.write(i+1,1,text[i])
book.save(savepath)
print("写入完成!")
url = baseurl
#print(url)
response = requests.get(url, headers=head)
data = json.loads(response.text)
get_comment(data)
save(username,text)