大数据之搭建HIVE数据仓库分析系统(Hadoop第四篇)
前言:
前面的文章介绍了Hadoop的HDFS,YARN,SSH设置,本篇将承接上面的配置,继续介绍Hadoop相关的HIVE工具,本篇将从HIVE的介绍,下载,安装,启动,测试等一连串进行截图讲解,本篇采用Mysql做元数据测试,希望大家喜欢。
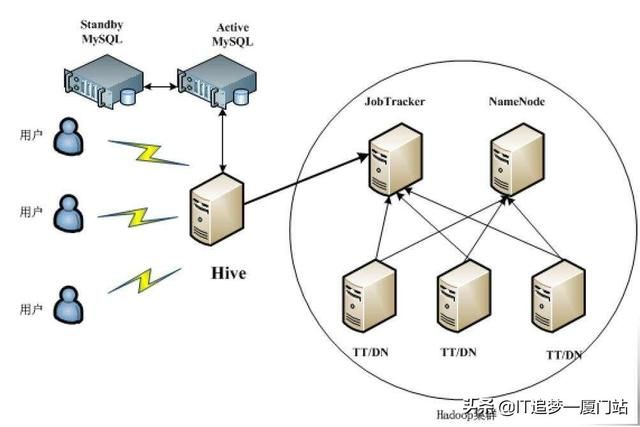
一、HIVE简介

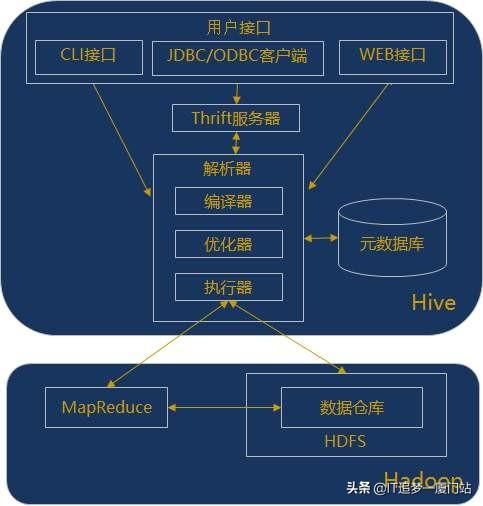
hive是基于Hadoop构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop分布式文件系统中的数据:可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能;可以将SQL语句转换为MapReduce任务运行,通过自己的SQL查询分析需要的内容,这套SQL简称Hive SQL,使不熟悉mapreduce的用户可以很方便地利用SQL语言‘查询、汇总和分析数据。而mapreduce开发人员可以把自己写的mapper和reducer作为插件来支持hive做更复杂的数据分析。它与关系型数据库的SQL略有不同,但支持了绝大多数的语句如DDL、DML以及常见的聚合函数、连接查询、条件查询。它还提供了一系列的1:具进行数据提取转化加载,用来存储、查询和分析存储在Hadoop中的大规模数据集,并支持UDF(User-Defined Function)、UDAF(User-Defnes AggregateFunction)和USTF(User-Defined Table-Generating Function),也可以实现对map和reduce函数的定制,为数据操作提供了良好的伸缩性和可扩展性
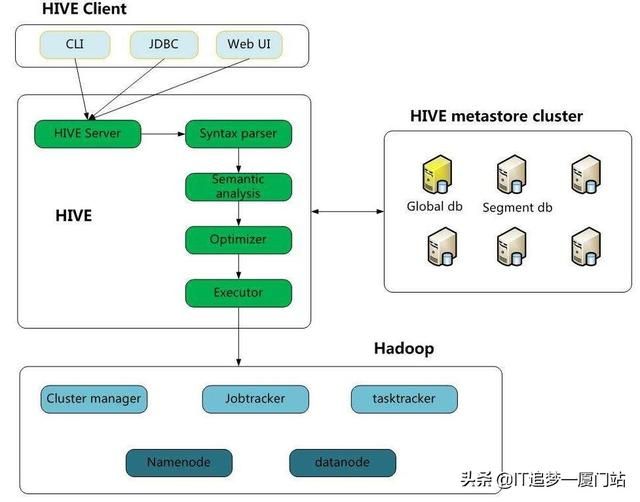
1.2、适用场景
hive 构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。
因此,hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,已经为大家精心准备了大数据的系统学习资料,从Linux-Hadoop-spark-......,需要的小伙伴可以点击hive 将用户的hiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。hive 并非为联机事务处理而设计,hive 并不提供实时的查询和基于行级的数据更新操作。hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
二、下载
wget https://archive.cloudera.com/cdh5/cdh/5/hive-1.1.0-cdh5.15.1.tar.gz
三、解压
tar -zxvf hive-1.1.0-cdh5.15.1.tar.gz
四、配置环境变量
打开并编辑系统文档profile,把hive的环境配置进去。
vim ./etc/profile
这里主要配置HIVE_HOME,并且把它加载到PATH中,因为我的环境有多个,所以直接拼接到PATH后面,使用:隔开
export HIVE_HOME=/home/hadoop/app/hive-1.1.0-cdh5.15.1 export PATH=$HIVE_HOME/bin:$PATH
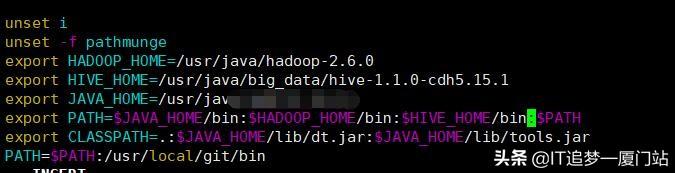
如果不知道你的HIVE的路径,可以在你的HIVE目录下执行pwd命令,就会得到此目录的完整路径,如下图

五、HIVE配置Mysql
1、HIVE加载Mysql驱动包
我这里把Mysql做为元数据库,所以需要Mysql的驱动包,驱动包建议使用5.x的版本,把驱动包放到lib下,如下图
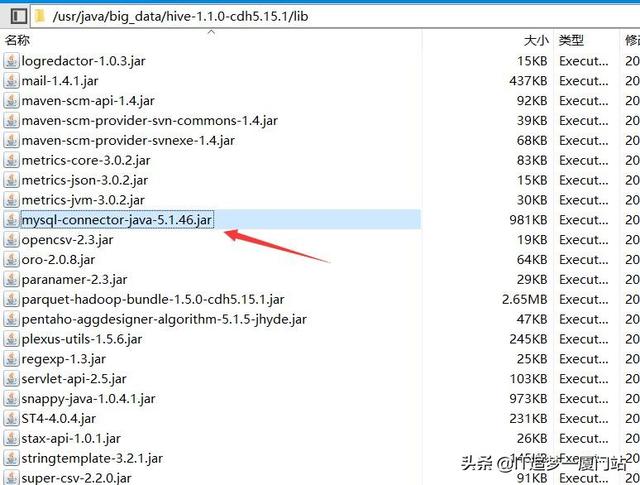
2、配置JDBC数据源
在conf下创建一个hive-site.xml文档,文档内容如下
javax.jdo.option.ConnectionURL jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useSSL=false javax.jdo.option.ConnectionDriverName com.mysql.jdbc.Driver javax.jdo.option.ConnectionUserName root javax.jdo.option.ConnectionPassword root
说明:JAVA开发的人基本是看得懂上面的配置,
ConnectionURL:第一个property是JDBC数据连接,只要修改Mysql数据库的IP和端口,再取一个库名(hive), createDatabaseIfNotExist=true:的意思是如果你的Mysql库里没有hive库的话,他会自动帮你创建库。 &useSSL=false:设置SSL为false,不需要证书,如果不设置,在使用hive操作Mysql数据库时,可能会userSSL相关错误
ConnectionDriverName:表示数据源的驱动,我这用的是Mysql驱动;
ConnectionUserName:数据库登录用户
ConnectionPassword:数据库登录密码
六、启动并使用hive命令(所有命令都 需要用分号;结尾,切记)
配置完数据源,开始操作hive,开始前先截图一下启动前的Mysql数据库,可以看到,在数据库中并没有hive这个库

1、启动hive,进入bin目录下,执行./hive命令。只要前面的配置不会出错,就会进入到下图中的最后一行光标显示的hive>命令行,这说明启动成功,可以在这里使用hive命令

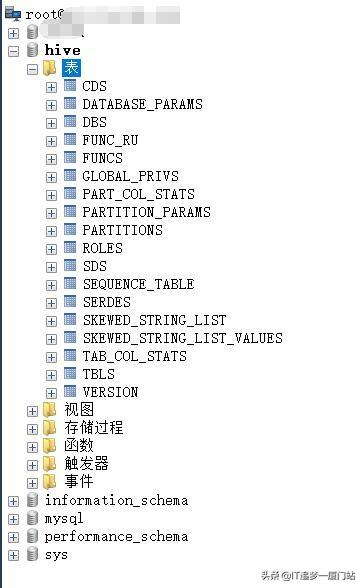
2、显示所有表命令,执行下面的命令,因为库不存在,所以花了三秒的时间创建了一个库,并且返回OK。这时我们再看下Mysql是否多了一个hive库(这个库名是由前面的数据源配置文件所写的,不一定要叫hive,可以取任何库名),看Mysql界面截图,多了一个hive库,并且自动生成了很多表
hive> show tables;

3、创建表及字段
3.1:在hive命令行中,执行下面的命令,创建一个table_test表,表中有两个字段,以逗号结尾的行格式分隔字段。
hive> create table table_test(id int,name string) row format delimited fields terminated by ',';
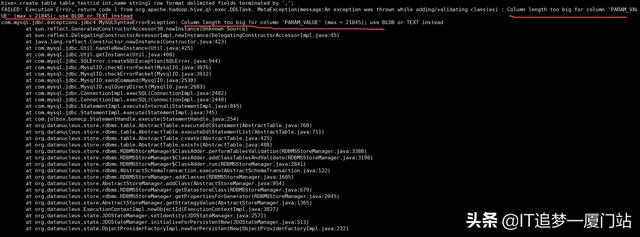
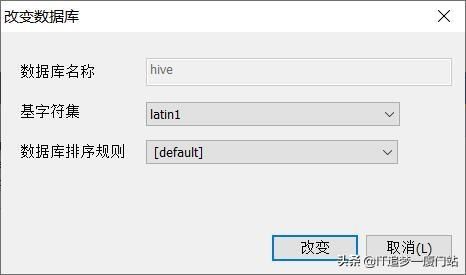
注意:在执行下面的语句时,有的人可能会出现下面的错误,出现类似下面的错误是因为我们创建的数据库编码问题,只需要把hive数据库的编码改成latin1类型
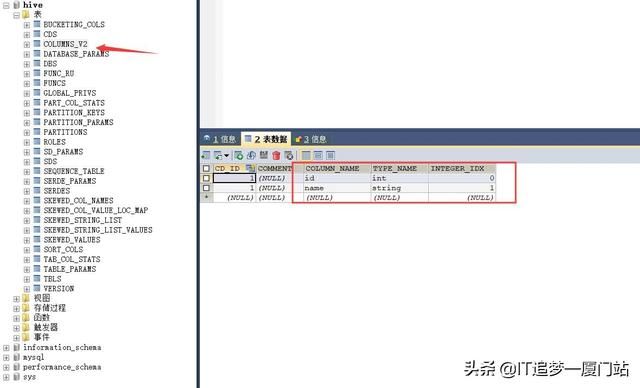
3.2:改完数据库编码后,我们再执行一下创建表语句,创建成功。我们再执行一下show tables;命令查看表,发现已经多了一张表,并且在Mysql中的hive库中,也多了一张列表,如图二

4、写入表数据
首先创建一个测试数据文档,然后用hive去读取这个文档信息,并且存储到我们前面刚建的表。我直接在hive目录下创建一个test.txt文档做测试。
![]()
测试文档的内容如下图,编辑完后,一定要记得保存(保存命令如最后一行)。

开始执行写入和查询,(我一并截图,因为太多截图,会导致这篇文章卡顿。)在执行count(1)语句时会跑MapReduce 任务,我们也可以使用浏览器查看一下作业,如图二,图二界面,我在上篇文章也有提到过,到下面,我对图二列表中的字段做个解释。
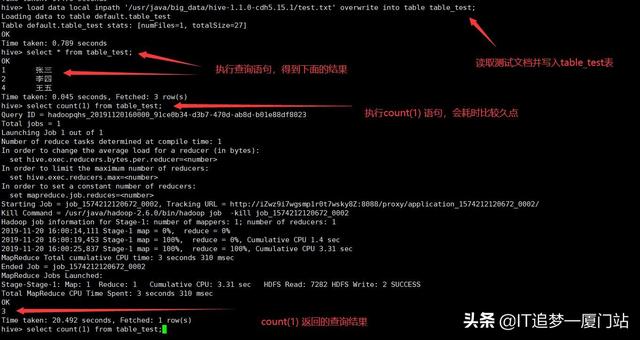
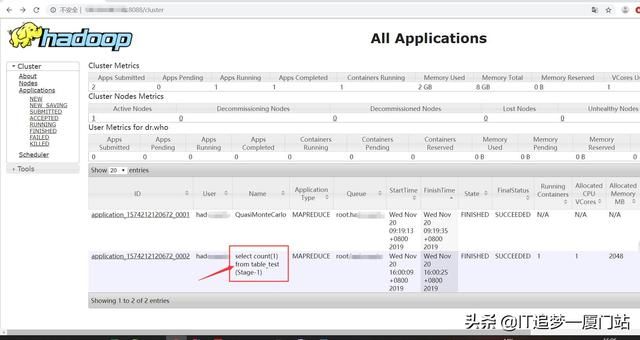
- ID:作业的标识
- User:作业的执行用户,也就是你执行hive的用户
- Name:作业名称
- ApplicationType:应用类型
- Queue:队列名
- StartTime:作业开始时间
- FinishTime:作业结束时间
- State:状态
- FinalStatus:结束状态
- RunningContainers:运行容器
- AllocatedCPUVCores:任务分配的CPU核心数
- AllocatedMemoryMB:任务分配的内容大小
七、结束语
至此HIVE的配置,运行,测试等都介绍完毕,若要跟着做的一定要先去看前面的文章(HDFS和YARN的配置),到现在Hadoop组件HDFS,SSH免密,YARN,HIVE都已经介绍完毕,这些都是数据存储及中间件,有了数据存储,后续我会介绍SparkSQL做数据分析。有兴趣的可以关注后续的文章。