Spark SQL的底层执行流程
说到Spark SQL ,我们不得不提到它的优化器(Catalyst),Catalyst是Spark sql的核心,它是针对于Spark SQL语句执行过程中的查询优化框架。所以在想了解Spark SQL的执行流程的时候,理解一下Catalyst的工作流程是很有必要的! 了解Catalyst的话! 一张图解释一下它的全流程。其中黑色方框为Catalyst的工作流程。

SQL语句首先通过Parser模块被解析成parsed Logical Plan AST语法树,而这棵树是Unresolved Logical Plan(未解决的逻辑计划)的,parsed Logical Plan 通过 Analyzer(分析器)模块借助于Catalog中的表信息解析成为 Analyzer Logical Plan AST语法树,这棵树是resolved Logical Plan(解决的逻辑计划);此时,Optimizer(优化器)在通过各种基于规则的优化策略进行深入优化,得到Optimized Logical Plan;优化后的逻辑执行计划依然是逻辑的,是不能够被spark系统理解,此时需要使用SparkPlan将此逻辑执行计划转换为Physical Plan,最后我们使prepareForExecution()将Physical Plan转换成为系统可以执行的物理计划。
总结:
- sqlText 经过 SqlParser 解析成 parsed Logical Plan AST语法树 ,而这颗语法树是(Unresolved Logical Plan);
- analyzer 模块结合catalog进行绑定,生成 nalyzer Logical Plan AST语法树,这颗树是(resolved Logical Plan);
- optimizer 模块对 resolved LogicalPlan 进行优化,生成 optimized LogicalPlan;
- SparkPlan 将 LogicalPlan 转换成PhysicalPlan;
- prepareForExecution()将 PhysicalPlan 转换成可执行物理计划;
- 使用 execute()执行可执行物理计划;
------------------------------------------------------
下面一步是讲解如何解析出来Parsed Logical Plan ,这棵树是Unresolved Logical Plan (未解决的逻辑计划) 。
将Parsed Logical Plan表示成结构树!如下图所示。Catalyst的Parser将图左边中一个sql查询的字符串解析成图右的一个AST语法树,该语法树就称为Parsed Logical Plan。解析后的逻辑计划基本形成了执行计划的基础骨架,此逻辑计划称为Unresolved Logical Plan,也就是该逻辑计划无法执行的,系统并不知道语法树中的每个词都是什么东西!,如图中的fifter , join , 以及studentTable。

此图转载! 这是Parsed Logical Plan语法树(AST语法树),该逻辑计划称为为Unresolved Logical Plan的。
下面讲解的是通过Analyzer模块中借助Catalog中的表信息将树解析成为Analyzed Logical Plan树,同时将Unresolved Logical Plan解析成 resolved Logical Plan;
将上图的Anlyzed Logical Plan 。即Resolved Logical plan表示成树结构--->下图所示。Catalyst的Analyzer将Unresolved Logical Plan 解析成resolved Logical Plan。Anlazer借助Catalog中表的结构信息、函数信息等将此逻辑计划解析成可被识别的Logocal Plan(逻辑执行计划)!

此图转载 Analyzed Logical Plan树 ,这棵树的计划是resolved Logical Plan(逻辑解决方案)
转载地址:https://blog.csdn.net/xuetaoxuetao/article/details/79025671
Optimized Logical Plan 与Physical Plan 的树结构跟上面两种逻辑执行计划树结构的画法相似,下面就不画了!从Optimized Logical Plan可出,此处优化使用了Filter下推的策略 , 这个下推策略大概就是Filter下推到子查询中实现,继而减少后续数据的处理量。
---------------------------Catalyst 各个模块的介绍----------------------------
1 . Parser 模块

首先调用sqlParser的ParsePlan方法,将sql字符串解析成Unresolved逻辑执行计划。parsePlan的具体是现在AbstractSqlParser类中。
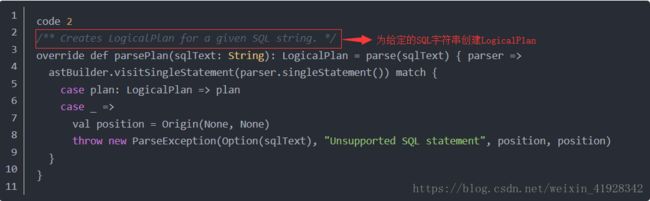
上段代码可以看出,调用的主函数是parse , 然后进入到parses方法中 ,
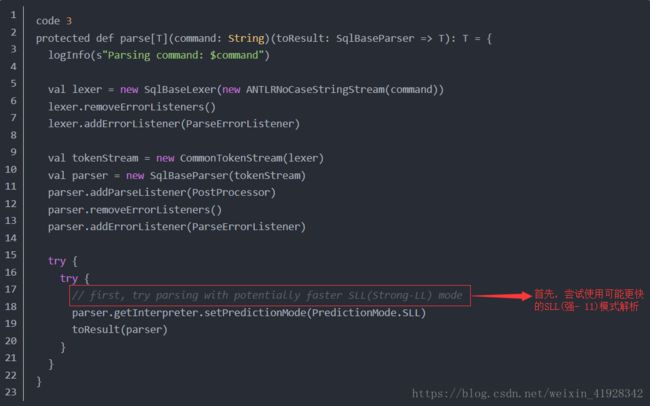
从parse函数可以看出,这里对于SQL语句的解析采用的是ANTLR 4 ,这里面使用了两个类:词法解析器SqlBaseLexer和语法解析器SqlBaseParser
SqlBaseLexer(词法解析器)和SqlBaseParser(语法解析器)均是使用ANTLR 4 自动生成的Java类。
代码2中的sqlParser 为SparkSqlParser,其成员变量 val astBuilder = new SparkSqlAstBuilder(conf)是将antlr语法结构转换为catalyst表达式的关键类!
可以看到code2中parsePlan方法先执行parse方法(code3),在代码4中先后实例化了分词解析器(SqlBaseLexer)和语法解析器(SqlBaseParser),最后将antlr的语法解析器parser:SqlBaseParser传给Code2中的柯里化函数,使用astBuilder转化为catalyst表达式,可以看到首先调用的是visitSingleStatement,singleStatement 为语法文件中定义的最顶级节点,接下来就是利用sntrl的visitor模式显示的便利整个语法树,将所有的节点都替换成了LogicalPlan或者Tableldentifier。
此时生成的逻辑计划称为unresolved logical Plan。只是将sql字符串解析成类似语法树结构的执行计划,系统并不知道每个词所表示的意思,还不能真正的执行!
总结 :
其实parser就是将SQL字符串切分成一个个的Token,再根据一定的语义解析成一个语法树。我们写的sql语句只是一个字符串而已,首先需要将其通过词法解析生成语法树,Spark1.X版本使用的是scala原生的parser语法解析器,从2.X后改用的是第三方语法解析工具ANTLR4,在性能上有很大的提升
那么思考一下antlr4 的使用需要定义一个语法文件,Sparksql的语法文件的路径在sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 antlr可以使用插件自动生成词法解析和语法解析代码,在SparkSQL中词法解析器SqlBaseLexer和语法解析器SqlBaseParser,遍历节点有两种模式 Listener和Visitor。
Listener模式是被动式遍历,antlr生成类ParserTreeListrner,这个类里面包含了所有进入语法树中每个节点和退出每个节点时要进行的操作。我们只需要实现我们需要的节点事件逻辑代码即可,在实例化一个遍历类ParserTreeWalker,antlr会自上而下的遍历所有节点,已完成我们的逻辑处理;
Visitor则是主动遍历模式,需要我们显示的控制我们的遍历顺序。该模式可以实现在不改变各元素的类的前提下定义作用于这些元素的新操作。SparkSql用的就是此方式来遍历节点的!
通过词法解析和语法解析将SQL语句解析成了ANTLR 4的语法树结构Parse Tree。然后再ParsePlan中,使用AstBuilder将ANTLR 4语法树结构转换成catalyst表达式逻辑计划logical plan。
----------------------------------------------------------------------------------------------------
2 . Analyzer模块
在上面的步骤中我们总结了,将parser生成逻辑计划以后,使用analyzer将逻辑执行进行分析。 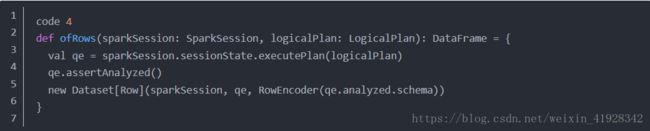
这里面首先创建了QueryExecution类对象,QueryExecution中定义了sql执行过程中的关键步骤,是sql执行的关键类,但会一个dataframe类型的对象。QueryExecution类中的成员都是lazy(懒惰)的,被调用时才会执行。只有等到程序中出现action算子时,才会调用queryExecution类中的executed Plan成员,原来生成的逻辑执行计划才会被优化器优化,并转化成物理执行计划真正的 被系统调用执行。
那么QueryExecution中的主要成员有哪些呢???主要定义了解析器analyzer、优化器optimizer以及生成物理执行计划的sparkPlan。

前面我们提到过!analyzer的主要职责是将parser生成的unresolved logical plan解析成resolved logical plan。调用analyzer的代码在QueryExecution中! 在code5中已经贴出! 此模块的主函数来自于analyzer的父类RuleExecutor。主函数execute实现在RuleExecutor类中,代码如下:
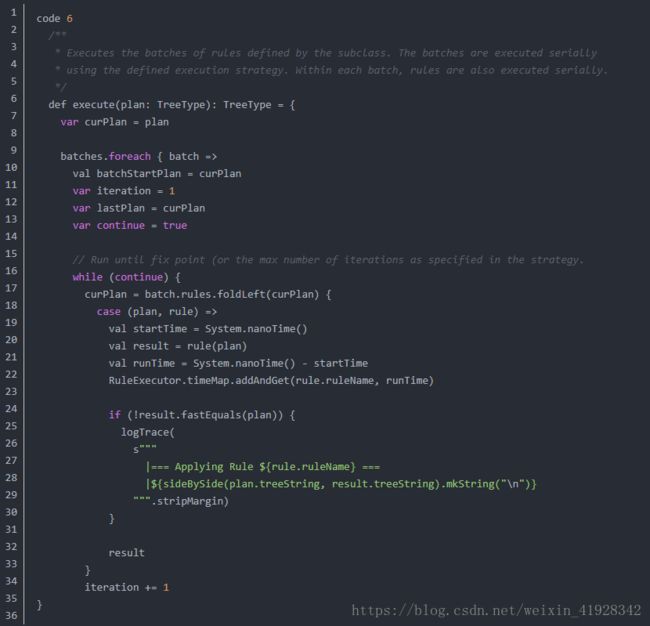
这个函数实现了针对analyzer类中定义的每一个batch(类别),按照batch中定义的fix point(策略)和rule(规则)对Unresolved的逻辑执行计划解析,代码的源码在Analyzer类中查看。
在Batchs里的这些batch中! resolution是最常用的,它就是将parser解析后的逻辑计划里面的各个节点,转变成resolved节点。而其中ResolveRelations是比较好理解的一个rule(规则),这一步调用了catalog这个对象,Catalog对象里面维护了一个tableName,logical Plan的HashMap结果。通过这个Catalog目录来寻找当前表的结构,从而从中解析出这个表的字段,如UnResolvedRelatioms会得到一个tableWithQualifiers。(就是表和字段)。