CVPR2020 U2-Net: Going Deeper with Nested U-Structure for Salient Object Detection代码解读
CVPR2020 U2-Net: Going Deeper with Nested U-Structure for Salient Object Detection代码解读
文章亮点
我们的U2-网的体系结构是一个两级嵌套的U-结构。该设计具有以下优点:(1)在所提出的ReSidual U-blocks (RSU)中混合了不同大小的感受场,能够从不同的尺度捕捉更多的上下文信息;(2)在不显著增加计算代价的情况下,增加了整个体系结构的深度,因为这些RSU块使用了合并操作。此体系结构使我们能够从头开始训练深度网络,而无需使用图像分类任务中的主干。
解决的问题:
1.我们能否为SOD设计一个新的网络,允许从头开始训练,并实现与基于现有预先培训的骨干网相媲美或更好的性能?
2.我们能否在保持高分辨率特征图的同时,以较低的内存和计算成本深入研究?
U2-Net,它解决了上述两个问题。首先,U2-Net是一种为SOD设计的两级嵌套U-结构,不需要使用图像分类中的任何预先训练的骨干。它可以从头开始训练,以获得有竞争力的表现。第二,新颖的体系结构允许网络走得更深,达到高分辨率,而不会显著增加内存和计算成本。这是通过嵌套的U-结构实现的:在底层,我们设计了一种新的ReSidual U-blocks (RSU),它能够在不降低特征图分辨率的情况下提取级内多尺度特征;在顶层,我们设计了一种类似U-Net的结构,其中每一级都由RSU块填充。
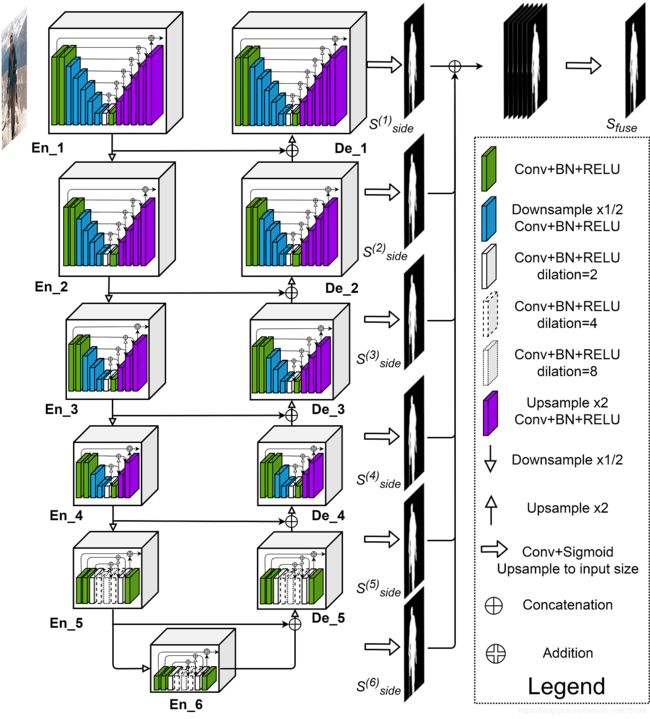
这是这篇文章的结构图,整个结构较为清晰,En_1和De_1,En_2和De_2,En_3和De_3,En_,4和De_4,En_,5和De_5以及En_6分别使用了RSU-7,RSU-6,RSU-5,RSU-4,RSU-4F和RSU-4F。在编码过程中添加了最大池化层,在解码过程中采用了双线性插值的方式进行上采样。
RSU结构及代码如下:
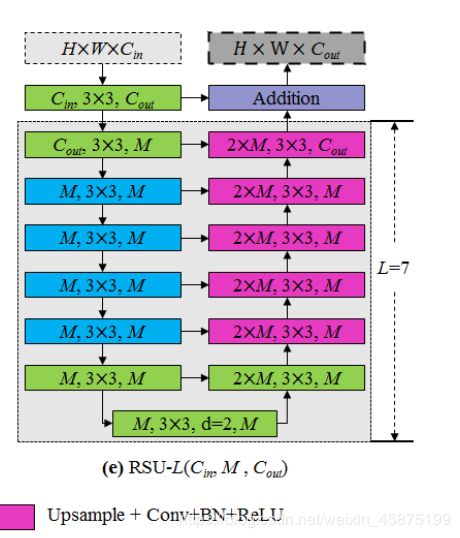
其中L是编码器中的层数,Cin,Cout表示输入和输出通道,M表示RSU内部层中的通道数。
文章中先定义了一段卷积模块:
class REBNCONV(nn.Module):
def __init__(self,in_ch=3,out_ch=3,dirate=1):
super(REBNCONV,self).__init__()
self.conv_s1 = nn.Conv2d(in_ch,out_ch,3,padding=1*dirate,dilation=1*dirate)
self.bn_s1 = nn.BatchNorm2d(out_ch)
self.relu_s1 = nn.ReLU(inplace=True)
def forward(self,x):
hx = x
xout = self.relu_s1(self.bn_s1(self.conv_s1(hx)))
return xout
接下来以RSU-7为例进行说明,其他层的代码几乎一致:
class RSU7(nn.Module):#UNet07DRES(nn.Module):
def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
super(RSU7,self).__init__()
self.rebnconvin = REBNCONV(in_ch,out_ch,dirate=1)
self.rebnconv1 = REBNCONV(out_ch,mid_ch,dirate=1)
self.pool1 = nn.MaxPool2d(2,stride=2,ceil_mode=True)
self.rebnconv2 = REBNCONV(mid_ch,mid_ch,dirate=1)
self.pool2 = nn.MaxPool2d(2,stride=2,ceil_mode=True)
self.rebnconv3 = REBNCONV(mid_ch,mid_ch,dirate=1)
self.pool3 = nn.MaxPool2d(2,stride=2,ceil_mode=True)
self.rebnconv4 = REBNCONV(mid_ch,mid_ch,dirate=1)
self.pool4 = nn.MaxPool2d(2,stride=2,ceil_mode=True)
self.rebnconv5 = REBNCONV(mid_ch,mid_ch,dirate=1)
self.pool5 = nn.MaxPool2d(2,stride=2,ceil_mode=True)
self.rebnconv6 = REBNCONV(mid_ch,mid_ch,dirate=1)
self.rebnconv7 = REBNCONV(mid_ch,mid_ch,dirate=2)
self.rebnconv6d = REBNCONV(mid_ch*2,mid_ch,dirate=1)
self.rebnconv5d = REBNCONV(mid_ch*2,mid_ch,dirate=1)
self.rebnconv4d = REBNCONV(mid_ch*2,mid_ch,dirate=1)
self.rebnconv3d = REBNCONV(mid_ch*2,mid_ch,dirate=1)
self.rebnconv2d = REBNCONV(mid_ch*2,mid_ch,dirate=1)
self.rebnconv1d = REBNCONV(mid_ch*2,out_ch,dirate=1)
def forward(self,x):
hx = x
hxin = self.rebnconvin(hx)
hx1 = self.rebnconv1(hxin)
hx = self.pool1(hx1)
hx2 = self.rebnconv2(hx)
hx = self.pool2(hx2)
hx3 = self.rebnconv3(hx)
hx = self.pool3(hx3)
hx4 = self.rebnconv4(hx)
hx = self.pool4(hx4)
hx5 = self.rebnconv5(hx)
hx = self.pool5(hx5)
hx6 = self.rebnconv6(hx)
hx7 = self.rebnconv7(hx6)
hx6d = self.rebnconv6d(torch.cat((hx7,hx6),1))
hx6dup = _upsample_like(hx6d,hx5)
hx5d = self.rebnconv5d(torch.cat((hx6dup,hx5),1))
hx5dup = _upsample_like(hx5d,hx4)
hx4d = self.rebnconv4d(torch.cat((hx5dup,hx4),1))
hx4dup = _upsample_like(hx4d,hx3)
hx3d = self.rebnconv3d(torch.cat((hx4dup,hx3),1))
hx3dup = _upsample_like(hx3d,hx2)
hx2d = self.rebnconv2d(torch.cat((hx3dup,hx2),1))
hx2dup = _upsample_like(hx2d,hx1)
hx1d = self.rebnconv1d(torch.cat((hx2dup,hx1),1))
return hx1d + hxin
结合RSU的结构图和文章总的结构,应该能够比较容易理解每一层对应的具体网络结构。代码应该已经很详细的表明每一步所在的位置及具体的指向。
最后总结:从全文以及最后的效果来看,作者不仅仅实现了无需现成骨干网络便可从头开始训练,并且最终的效果也较好。接下来还值得思考的是:文章是不是在提取高分辨图特征时,已经提取到细节信息,控制下采样的深度不仅仅是为了减少计算成本,或许也能更好掌握边缘细节等信息?(纯属个人观点,请知晓者答疑解惑)