darknet-yolov3环境配置、编译、训练和测试完整记录(Win10 + CUDA10 + VS2017)
1. 环境与依赖配置
操作系统:windows10;
依赖:
(1). VS2017
CUDA8.0之后的版本支持VS2017。darknet是使用VS2015编译的,官网提供的编译教程也是基于VS2015的,但VS都是向下兼容的,安装相应版本的平台工具集即可。
(2). CUDA10.0(推荐Installer type为network)
(3). cudnn for CUDA10.0(需要注册nvidia账号)国内下载 https://download.csdn.net/download/ywueoei/12352001
ps:如果不清楚可以看该up的视频教程https://www.bilibili.com/video/BV1H4411j7Wv
推荐博客: https://blog.csdn.net/Clay_Zhang/article/details/82975593
https://www.cnblogs.com/taotingz/p/11319410.html
https://blog.csdn.net/anhec/article/details/86747512
https://blog.csdn.net/anhec/article/details/86748637
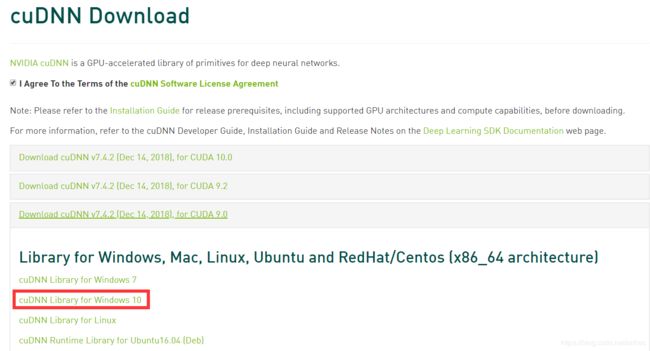
(4). Opencv3.4.0(darknet官网教程提示更新的版本会有bug,推荐就下载安装这个版本)。
Opencv3.4.0不需要安装,其实解压就行,将下载的opencv-3.4.0-vc14_vc15.exe双击进行解压过程。
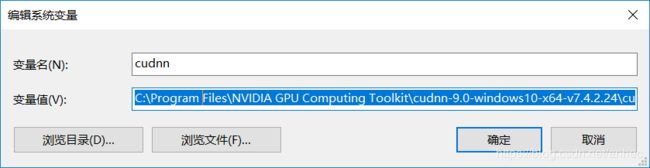
添加系统环境变量:根据darknet官网教程,需要将Opencv与cudnn的路径添加到环境变量,这是为了在编译Yolov3时读取Opencv与cudnn中的依赖.dll文件,如果不添加环境变量,我们后续将所依赖的.dll文件手动拷贝到编译目录下也行。
添加系统环境变量:

测试
方法一:打开cmd,输入nvcc -V:
方法二:运行测试demo,打开 %CUDA_install_dir%\CUDA\v10.0\extras\demo_suite,运行deviceQuery.exe:
若显示Result = PASS,说明安装成功。
经过以上步骤,便已成功安装了CUDA,之后可以对Yolov3源码进行编译,用来训练自己的数据。
2.编译darknet源码
开始编译Yolov3源码darknet,参照darknet官方教程:https://github.com/AlexeyAB/darknet#how-to-compile-on-windows
(1). 下载源码:
git clone https://github.com/AlexeyAB/darknet.git或者直接下载然后解压,我解压后项目的路径为D:\darknet-master
(2). 拷贝依赖的.dll文件:
拷贝项目所依赖的opencv与cuda的.dll文件到项目输出路径(D:\darknet-master\build\darknet\x64)下:
C:\Program Files\opencv3.4.0\build\x64\vc14\bin\opencv_ffmpeg340_64.dll
C:\Program Files\opencv3.4.0\build\x64\vc14\bin\opencv_world340.dll
(4). 修改项目属性:
双击D:\darknet-master\build\darknet\darknet.sln文件,用VS2017打开项目,会显示“重定向项目”:
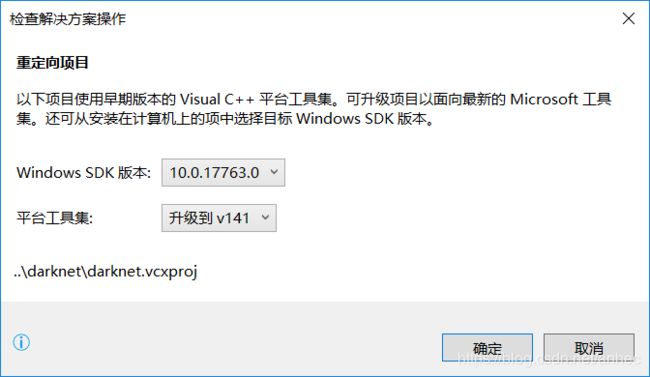
点击取消,然后修改解决方案平台为x64, 配置为Release:

打开项目属性,修改平台工具集为Visual Studio 2017 (v141):(Visual Studio 2015 (v140)也可以,我用141)

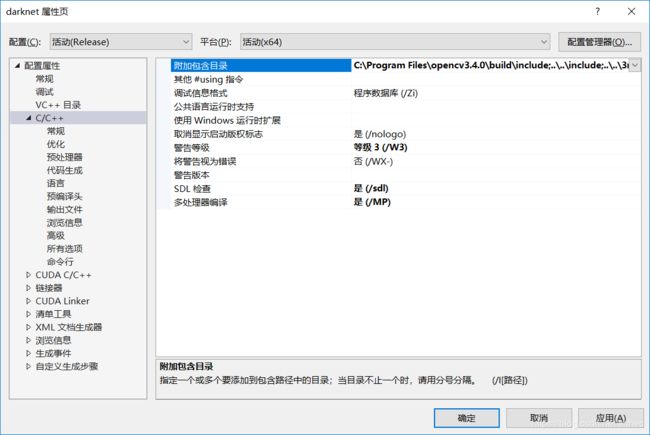
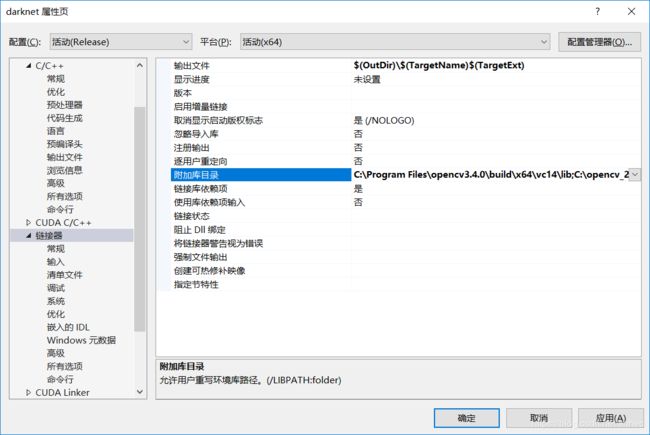
修改opencv的目录属性:在属性页的“配置属性” --> "C/C++" --> “附加包含目录”,与 “配置属性” -->“链接器” --> “附加库目录”中,将Opencv的目录修改为自己的路径:
修改完成后点击确认,然后右击项目名称,点击“生成”:
编译成功:

(5) 测试
在输出路径(D:\darknet-master\build\darknet\x64)下生成了darknet.exe文件。
在github上下载作者训练好的模型,网址:https://github.com/AlexeyAB/darknet/blob/master/README.md
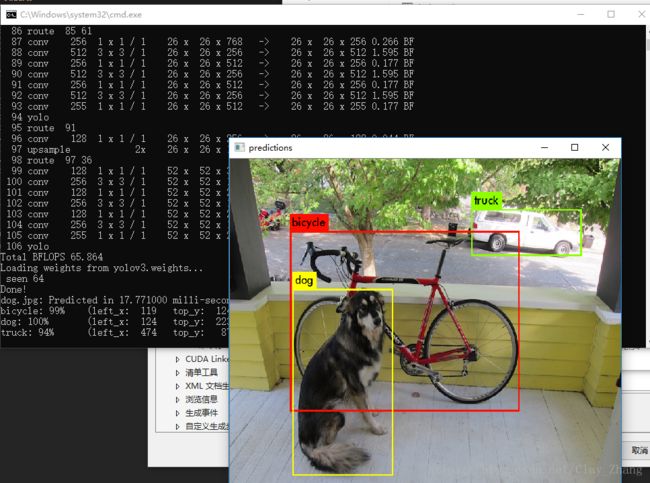
下载后放在…\darknet-master\build\darknet\x64下,打开该目录,双击darknet_yolo_v3.cmd会出现以下结果,表明成功编译。
3.训练自己数据集
(1)下载图片
推荐使用爬虫或者脚本,大家各显神通,我用的fatkun这个脚本插件。
(2)目标快速标注
darknet-yolo数据集标注工具有labelimage和yolo-mark(需要自己make),我找了一个大佬自制标注工具(下载后双击exe文件可直接运行),可以实现yolo数据集的快速标注。
csdn下载地址:https://download.csdn.net/download/ywueoei/12351963
教程:https://blog.csdn.net/KayChanGEEK/article/details/85054588
(3)修改模型结构.cfg文件
从这一部分开始,推荐跟着官方的方法走是最安全的。
https://github.com/AlexeyAB/darknet#how-to-train-to-detect-your-custom-object
Darknet中的cfg文件说明参考 https://blog.csdn.net/phinoo/article/details/83022101
这里我使用的是yolov3-tiny模型来训练,从darknet源码目录下的cfg\下拷贝yolov3-tiny_obj.cfg文件重命名进行修改:
(a). 修改batch与subdivision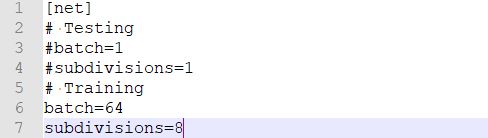
batch表示一个批次的样本数目。
(b). 修改classes数目
将第135行与第177行的classes=80修改为classes=1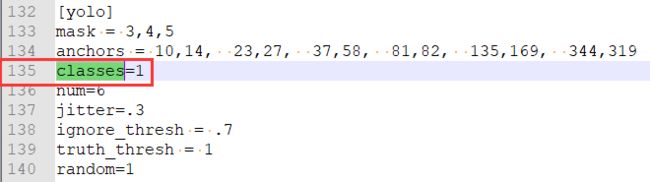
(c ). 修改filters数目
将模型里的yolo层的上一层的filters数目(第127行与)修改为(classes + 5)x3,比如原来有80个类时,filters=255;我们只有1个类,所以filters=18。该版本filters=(classes+5)*3 kn
kn
(4)修改voc.data
记住这里的voc.data是在F:\darknet-master\build\darknet\x64\data这下面的,做如下修改:
类别数为对应你想检测的类别,train和valid对应的路径,backup就是最后训练好的权重存放位置。
classes= 1
train = data/my_train.txt
valid = data/my_val.txt
names = data/voc.names
backup = data/weights
(5)修改voc.names
记住这里的voc.names是在F:\darknet-master\build\darknet\x64\data下的,做如下修改:
写上自己需要检测的类别名即可,一行一个,我这里只有一个。
cup
ps: 如果用的是上边那个工具则只需要将.data文件复制到 darknet的data或cfg下,(4)(5)中其它文件不用修改,已经自动生成

(6). 训练
准备好训练数据与训练模型后,编译好的darknet.exe进行训练了。
官方说明:
Do all the same steps as for the full yolo model as described above. With the exception of:
- Download default weights file for yolov3-tiny: https://pjreddie.com/media/files/yolov3-tiny.weights
- Get pre-trained weights
yolov3-tiny.conv.15using command:darknet.exe partial cfg/yolov3-tiny.cfg yolov3-tiny.weights yolov3-tiny.conv.15 15 - Make your custom model
yolov3-tiny-obj.cfgbased oncfg/yolov3-tiny_obj.cfginstead ofyolov3.cfg - Start training:
darknet.exe detector train data/obj.data yolov3-tiny-obj.cfg yolov3-tiny.conv.15
(a)从头开始训练
darknet.exe detector train \data\voc.data cfg\yolov3-tiny_obj.cfg
- 1
(b)使用预训练好的权重继续训练
权重下载:https://pjreddie.com/media/files/yolov3-tiny.weights 然后运行预训练:
darknet.exe partial train cfg\yolov3-tiny_obj.cfg yolov3-tiny.weights yolov3-tiny.conv.15 15
- 训练:
darknet.exe detector train \data\voc.data cfg\yolov3-tiny_obj.cfg yolov3-tiny.conv.15
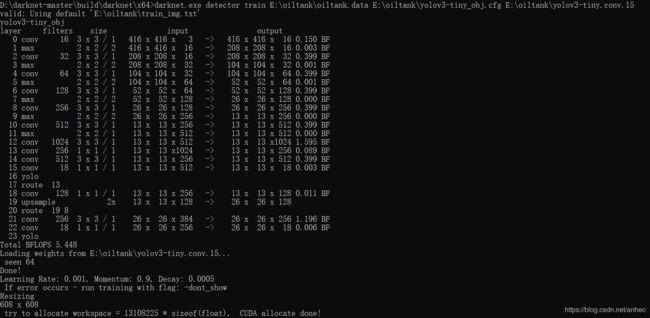
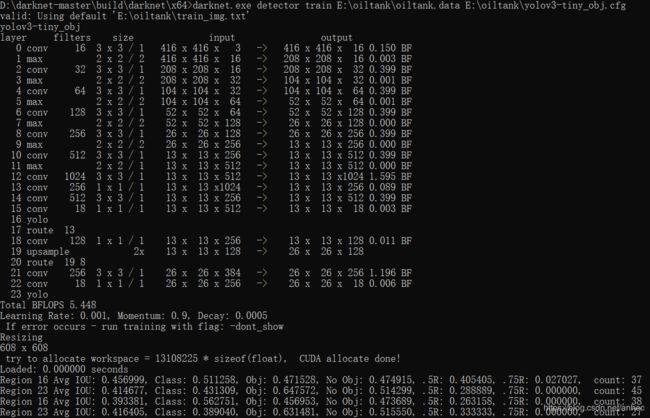
训练时,每个批次64幅图片,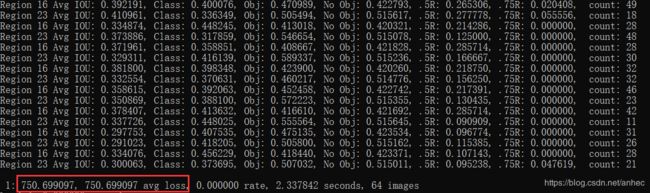
红框内表示训练集误差与测试集误差,当误差值不再下降时,可以停止训练。每1000个batch会保存一次模型的weights 到data文件中声明的backup路径下。
Region Avg IOU:平均的IOU,代表预测的bounding box和ground truth的交集与并集之比,期望该值趋近于1。
Class:是标注物体的概率,期望该值趋近于1.
Obj:期望该值趋近于1.
No Obj:期望该值越来越小但不为零.
Avg Recall:期望该值趋近1
avg:平均损失,期望该值趋近于0
rate:当前学习率
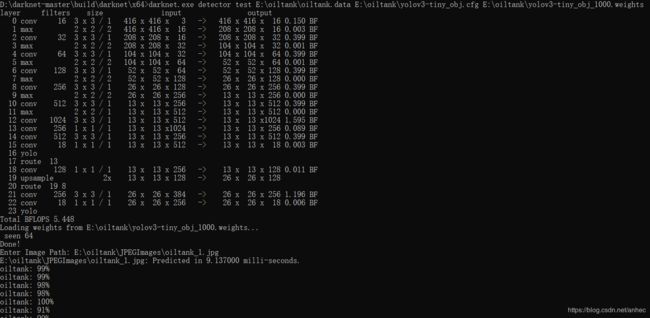
4. 测试
我训练到1000个批次左右时,avg loss值在3附近波动不再下降了,于是停止了训练。 注意: avg loss极限值为0.6左右
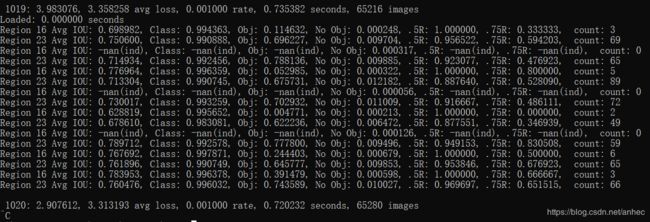
backup声明的路径下,生成了2个权重文件: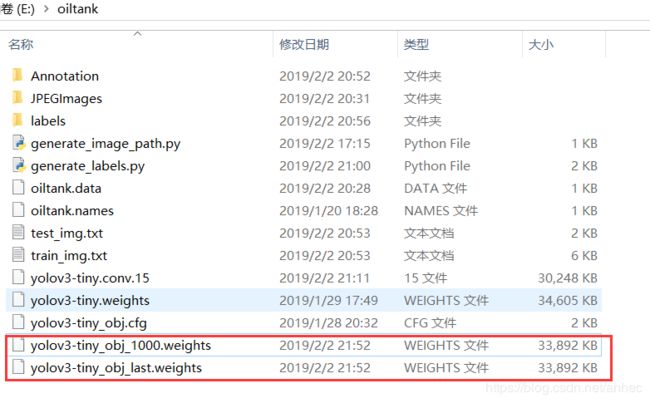
yolov3-tiny_obj_1000.weights是训练到第1000次时,模型的权重;yolov3-tiny_obj_last.weights是中止训练时模型的权重。
程序中断之后继续训练(就是将训练命令后边的weights文件换成刚刚生成的.weights文件 1000是迭代了1000次的)
./darknet detector train data/voc.data cfg/yolov3-tiny_obj.cfg /backup/yolov3-voc_1000.weights
注意:
- 如果
Out of memory发生错误,则应在.cfg中修改subdivisions=16 32或者64 - 如果要训练的话,要把Testing状态的相关参数注释掉,改用Training状态的参数(batch=64, subdicisions=16),否则会出现loss 不收敛,一直nan的状态,测试时要改回去不然可能检测不到目标。
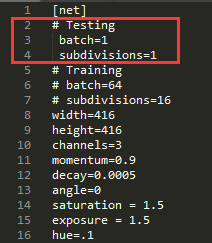
测试:
darknet.exe detector test \data\voc.data cfg\yolov3-tiny_obj.cfg yolov3-tiny_obj_1ast.weights -thresh 0.25
-thresh 0.25 是设置置信度越小精确度越低,刚开始一直识别没有框,降低置信度后才成功识别出 下为官方给出的各种命令
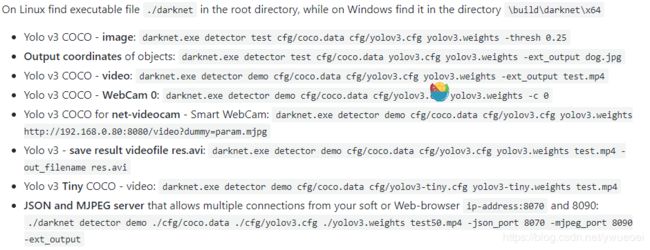
然后输入要测试的图片的路径: