基于Ubuntu Server16.04的Hadoop伪分布式及Spark的安装与配置
基于Ubuntu Server16.04的Hadoop伪分布式及Spark的安装与配置
一、配置JDK环境
- 下载jdk安装包jdk-8u172-linux-x64.tar.gz
- 解压安装包,并将其放在指定位置
ubuntu@VM-54-14-ubuntu:~/downloads$ tar -zxvf jdk-8u172-linux-x64.tar.gz
ubuntu@VM-54-14-ubuntu:~/downloads$ mv jdk1.8.0_172 /usr/local/jdk1.8.0_172
- 添加环境变量

- 使环境变量生效
ubuntu@VM-54-14-ubuntu:~/downloads$ source /etc/profile
- 测试

二、安装Scala
- 下载Scala安装包scala-2.12.6.tgz
- 解压安装包
ubuntu@VM-54-14-ubuntu:~/downloads$ sudo tar -zxvf scala-2.12.6.tgz
- 将解压后的文件放在指定位置

- 添加到环境变量
![]()
- 测试
![]()
另外,还可以通过sudo apt install scala的方式安装scala
三、安装Hadoop
安装具体步骤可参考厦门大学数据库实验室的教程http://dblab.xmu.edu.cn/blog/install-hadoop/
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
修改/etc/hadoop/core-site.xml:
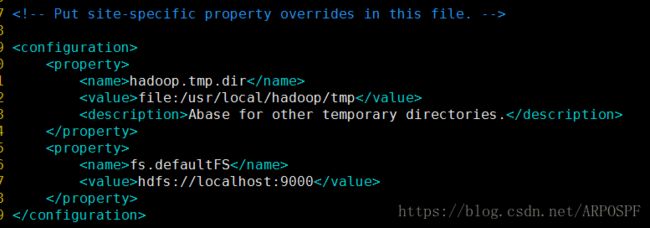
修改etc/hadoop/hdfs-site.xml:
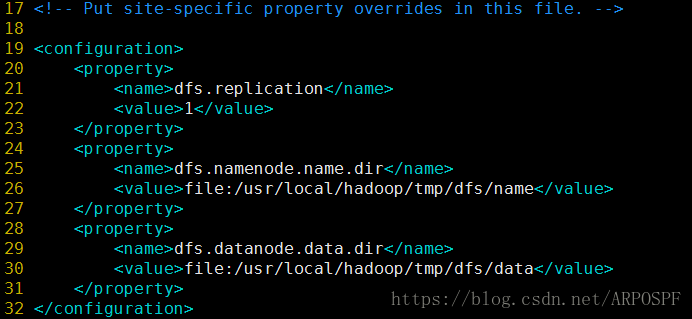
另外,还需要修改hadoop环境配置文件,即hadoop-env.sh:
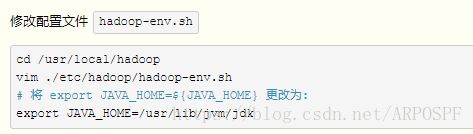
这里,我的修改信息如下:
![]()
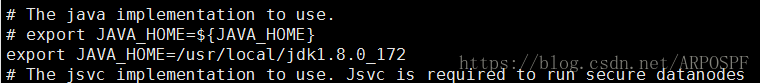
Hadoop配置文件说明
Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。
此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
修改完配置文件后,可以执行NameNode格式化。
hadoop@VM-54-14-ubuntu:/usr/local/hadoop$ ./bin/hdfs namenode -format
之后可以启动HDFS文件系统
hadoop@VM-54-14-ubuntu:/usr/local/hadoop$ ./sbin/start-dfs.sh
通过浏览器访问:http://your ip address:50070
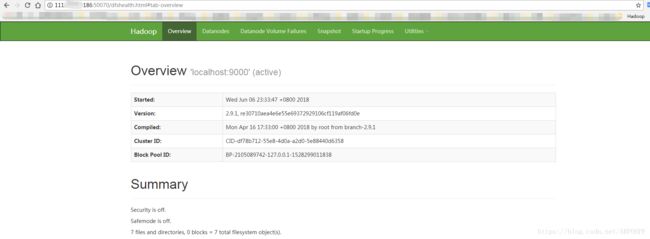
关于YARN
YARN 是从 MapReduce 中分离出来的,负责资源管理与任务调度。YARN 运行于 MapReduce 之上,提供了高可用性、高扩展性。启动 YARN ,让 YARN 来负责资源管理与任务调度。
首先修改MapReduce的配置文件,配置JobTracker的地址及端口:
复制mapred-site-xml.template为mapred-site-xml
ubuntu@VM-54-14-ubuntu:/usr/local/hadoop/etc/hadoop$ sudo cp mapred-site.xml.template mapred-site.xml
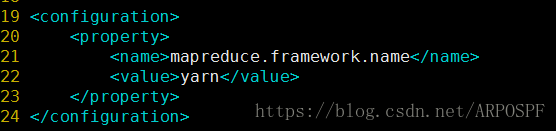
修改yarn-site.xml
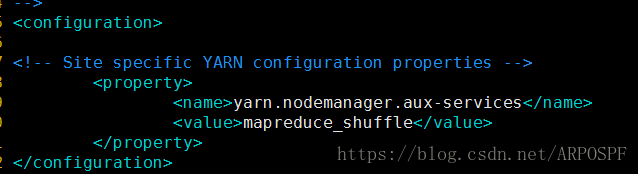
启动yarn
hadoop@VM-54-14-ubuntu:/usr/local/hadoop$ ./sbin/start-yarn.sh
![]()
启动历史服务器
![]()
通过浏览器查看:
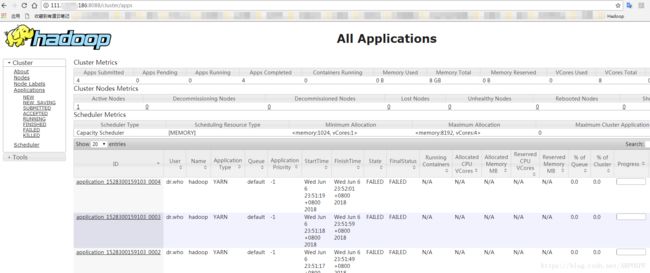
四、安装Spark
下载Spark(spark-2.3.0-bin-hadoop2.7.tgz)
解压后将文件移动到指定位置:
sudo mv spark-2.3.0-bin-hadoop2.7 /usr/local/spark
添加环境变量

修改配置文件
sudo cp ./conf/spark-env.sh.template ./conf/spark-env.sh
添加

运行简单的实例:计算Pi
ubuntu@VM-54-14-ubuntu:/usr/local/spark$ ./bin/run-example SparkPi 2>&1 | grep "Pi is"
测试Spark是否可以正常访问Ubuntu系统中的本地文件

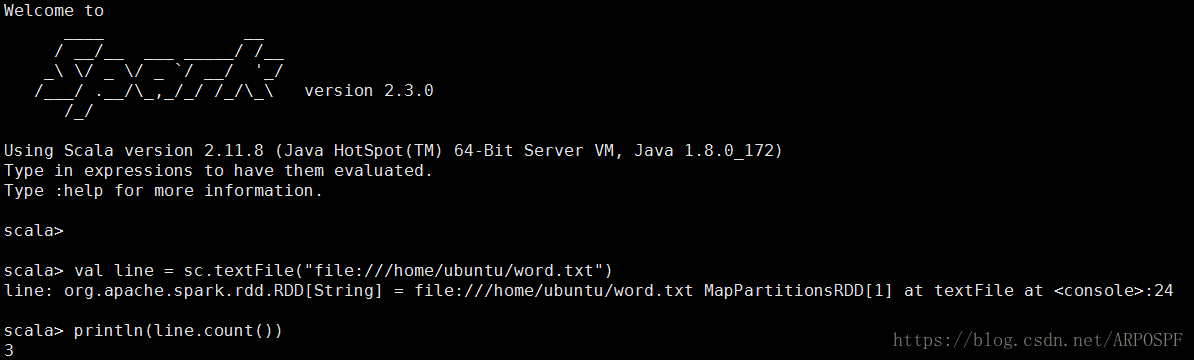
测试Spark是否能够正常访问Hadoop中的HDFS
创建用户目录
hadoop@VM-54-14-ubuntu:/usr/local/hadoop$ ./bin/hdfs dfs -mkdir -p /user/ubuntu
将文件上传到用户目录中
hadoop@VM-54-14-ubuntu:/usr/local/hadoop$ ./bin/hdfs dfs -put /home/ubuntu/word.txt /user/ubuntu
查看文件内容

启动Spark-shell,测试

在spark-shell交互式环境中,要访问HDFS中的文件时,可以直接使用sc.textFile(“/user/linziyu/word.txt”)和sc.textFile(“word.txt”)这两种路径格式。
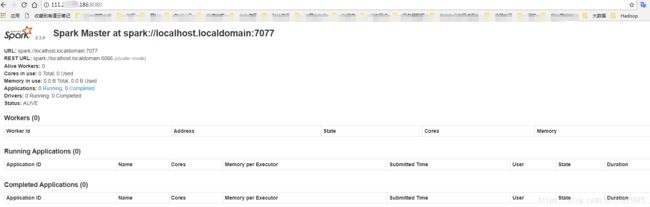
启动Spark
hadoop@VM-54-14-ubuntu:/usr/local/spark$ ./sbin/start-all.sh
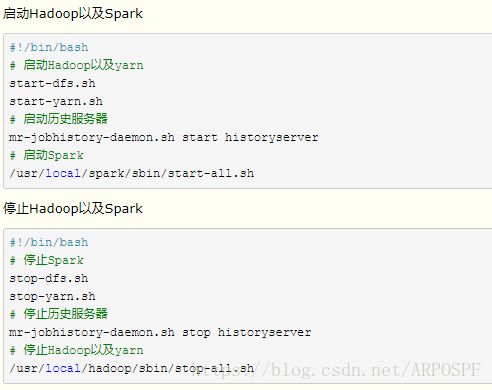
除此之外,还可以通过编写脚本等方式启动hadoop与spark
参考文章:
http://www.cnblogs.com/bovenson/p/5760856.html
http://dblab.xmu.edu.cn/blog/install-hadoop/
http://dblab.xmu.edu.cn/blog/2081-2/