Kafka入门大全
定义
一个分布式、分区的、多副本的实时消息发布和订阅系统。
特点
消息持久化——消息被持久化到本地磁盘,支持数据备份以防数据丢失
高吞吐量——即使是普通硬件,Kafka也支持每秒数百万的消息
可拓展性——搭建在分布式集群服务器上,支持水平无限拓展
容错性——将数据副本存放在多台服务器上,避免服务器故障影响运行
高并发——将数据分片后存在多台服务器上,在多台客户端上读取消息
使用场景
∙ 日志收集
使用Kafka收集来自多台服务器上的日志文件,以统一接口服务的方式开放给各种consumer
∙ 用户活动跟踪
记录web或app用户的各种活动,将活动信息通过各个broker发送到Kafka的topic中,订阅者订阅这些topic来做实时的监控分析
∙ 指标监控
收集各种分布式应用的数据,将统计数据集中聚合
∙ 消息系统
与大多数消息系统比较,kafka有更好的吞吐量,内置分区,副本和故障转移,这有利于处理大规模的消息
基本概念
Broker:Kafka集群包含一个或多个服务器,每个服务器成为一个broker
Topic:Kafka集群中消息的主题/类别
Producer:生产者,负责发布消息到Kafka
Consumer:消费者,是从Kafka broker读取消息的客户端
Consumer Group:每个consumer属于一个特定的consumer group
Partition:分区,每个topic包含一至多个分区
Offset:记录当前所消费的消息的起始位置
Replicas:副本,以分区为单位。每个分区都有各自副本的主副本(leader)和从副本(follower)
ISR:leader的备选集,负责记录所有处于同步状态的副本
Controller:一个负责topic创建、修改、删除的broker
Kafka的分布式
为了保证Kafka的容错能力,每个topic有多个副本,这就意味着每个partition有多个副本。所以当producer往某个topic写消息的时候,Kafka会根据key(hash选择),选择一个partition让producer写入。而这个partition是该partition众多副本中的leader,其余副本均为follower,用来与leader同步。
写消息
1、producer向Kafka请求连接指定topic;
2、Kafka收到连接请求,获取请求连接的相关数据,将key值进行hash找到对应topic的一个partition(leader partition),返回与producer的socket连接;
3、producer向leader partition发送数据;
4、Kafka将数据进行存储,向follower广播发送数据——集群的数据同步;
5、数据同步完成后,向producer发送committed命令,表示发送成功,并通知继续发送数据。
读消息
1、consumer连接zookeeper,请求获取Kafka某个topic的主机地址;
2、zookeeper返回相关的连接参数,consumer直接进行连接;
3、Kafka在这个topic的partitions中,根据负载均衡算法(简单的就是轮询),选择一个partition的socket连接给consumer;
4、consumer建立连接后开始消费数据。
拓扑结构
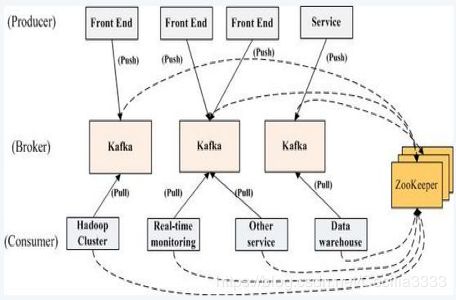
一个典型的Kafka集群中包含若干Producer(可以是web前端或服务器日志等),若干broker,若干Consumer Group以及一个Zookeeper集群。
Kafka通过Zookeeper管理Kafka集群配置:选举Kafka broker的leader,以及在Consumer Group发生变化时进行rebalance。因为consumer消费topic的partition的offset信息是存在Zookeeper中的。
Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
数据处理流程
分区机制
∙ Kafka的broker端支持消息分区partition,在一个partition 中message的顺序即Producer发送消息的顺序。一个topic中可以有多个partition,具体partition的数量是可配置的。
∙ partition可以设置replica副本,replica副本存在不同的broker节点上,第一个partition是leader,其他的是follower,message先写到partition leader上,再由partition leader 广播发送到partition follower上。所以说kafka可以水平扩展,即扩展partition。
leader选举
Kakfa Broker集群受Zookeeper管理。所有的Kafka Broker节点会一起去Zookeeper上注册一个临时节点。只有一个Kafka Broker会注册成功,这个成功在Zookeeper上注册临时节点的 Broker会成为Controller,其他的 broker为follower。Controller会选举出一个partition为leader partition,其余的partition为follower partition。leader partition负责消息的同步和读写操作。当有消息发送过来时,首先会在leader partition上进行写操作,然后leader广播通知其他的follower进行消息的同步。ISR中会记录所有与leader保持同步的follower信息,当某个follower状态变为非同步时,leader会将此follower剔除出ISR,直至它重新保持同步。当leader非同步时,Controller会在ISR中选举一个follower成为新的leader。
实时数据与离线数据
kafka既支持实时数据,同时也支持离线数据,因为kafka的message是持久化到本地文件系统中的,并且可以设置有效期,因此可以把kafka作为一个高效的存储系统来使用,可以存储离线数据供后面的分析。当然作为分布式实时消息系统,大多数情况下还是用于实时数据的处理。但是当consumer消费能力下降的时候,可以通过message的持久化,将数据淤积在kafka中。
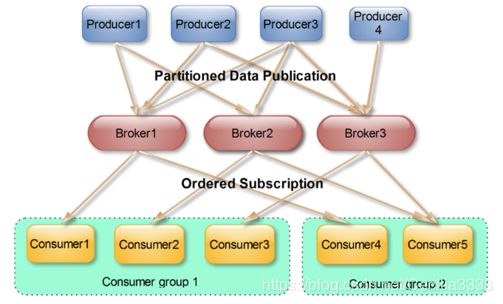
consumer group消费
1、各个consumer可以组成一个Consumer group,partition中的每个message只能被Consumer group中的一个consumer消费。
2、如果一个message被多个consumer消费的话,那么这些consumer必须在不同的Consumer group。多个consumer的消费都必须是顺序读取partition里面的message。
3、当启动一个consumer group去消费一个topic的时候,无论topic里面有多少个partition,无论consumer group里面配置了多少个consumer,这个topic里面所有的partition一定会被这个Consumer group全部消费,即便这个consumer group下只有一个consumer。
4、最优的设计就是consumer group下的consumer 数量等于partition数量,这样效率是最高的。
如果一个consumer group里面consumer的数量小于topic里面partition的数量,就会有consumer同时处理多个partition。
如果这个consumer group里面consumer的数量等于topic里面partition的数量,则每个consumer处理一个partition。
如果这个consumer group里面consumer的数量大于topic里面partition的数量,多出的consumer就会闲着啥也不干,剩下的是一个consumer处理一个partition,这就造成了资源的浪费。

副本机制
一个分区可以有多个副本,这些副本保存在不同的broker上。每个分区的副本中都会有一个Leader。当一个broker失败时,Leader在这台broker上的分区都会变得不可用,kafka会自动移除Leader,在其他副本中选一个作为新的Leader。
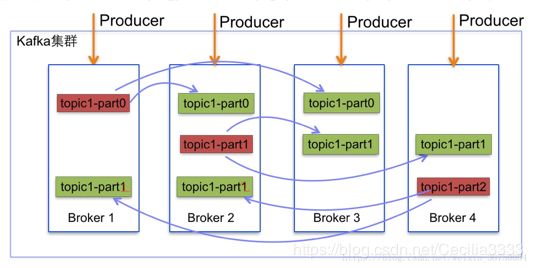
自动分区
例:一个Kafka集群中4个broker,创建一个topic包含4个partition,2个replication。
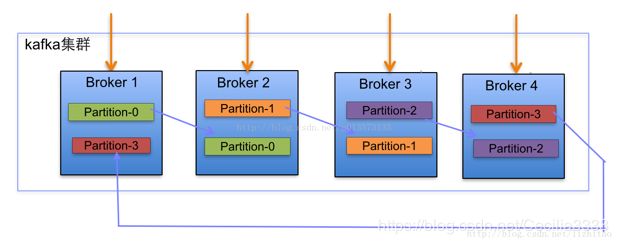
当新增两个broker节点,partition增加至6。
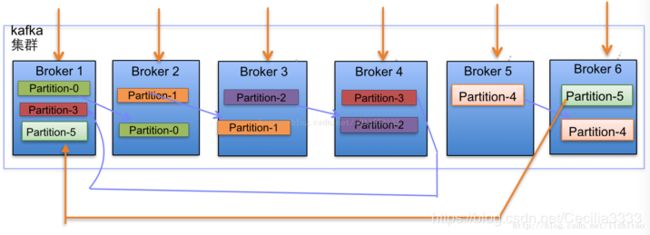
副本分配逻辑
1、在Kafka集群中,每个Broker都有均等分配Leader Partition的机会。
2、上述图Broker Partition中,箭头指向为副本。以Partition-0为例,broker1中parition-0为Leader,Broker2中Partition-0为副本。
3、上述图中每个Broker依次分配主Partition,下一个Broker为副本,如此循环迭代分配,多副本都遵循此规则。
常用命令
启动Kafka
bin/kafka-server-start.sh --daemon config/server.properties
停止Kafka
bin/kafka-server-stop.sh config/server.properties
新建topic
bin/kafka-topic.sh --zookeeper localhost:2181 --create --topic test_topic --partitions 10 --replication-factor 3
查看topic列表
bin/kafka-topic.sh --zookeeper localhost:2181 --list
查看指定topic明细
bin/kafka-topic.sh --zookeeper localhost:2181 --desc --topic test_topic
修改partition数量
bin/kafka-topic.sh --zookeeper localhost:2181 --alter --topic test_topic --partition 5
(注:partition的数量只允许增加,不允许减少)
删除topic
1、修改server.properties中delete.topic.enable=true
2、执行命令bin/kafka-topic.sh --zookeeper localhost:2181 --delete --topic test_topic
生产数据
bin/kafka-console-producer.sh --broker-list localhost:2181 --topic test_topic
消费数据
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test_topic (--from-beginning)
(注:加上--from-beginning表示指定从第一条数据开始消费 )
查看日志内容
bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files ./log/test_topic-0/00000000000000000000.log --print-data-log
(注:print-data-log选项可以显示日志文件中每条消息推送的内容)
查看consumer的offset
get /kafka/admin/config/reassignment-config