TextBoxes++在 ubuntu16.04上的编译及训练
论文地址:https://arxiv.org/abs/1801.02765,发表于 AAAI2018
Github地址:https://github.com/MhLiao/TextBoxes_plusplus.git
对于阅读这篇文章的读者来说,对于 TextBoxes++论文本身应该已经不陌生。它是 TextBoxes 的一个扩展,TextBoxes 只可以检测水平方向的文本,而 TextBoxes++可以检测任意角度的文本,而且訪方法也是基于 SSD 改造实现的。TextBoxes++的具体实现细节我可能另外会写一篇自己的解读文章(只是可能),这里主要是记录一下如果把这个项目跑起来。
1.我的环境
系统:Ubuntu 16.4
CUDA:CUDA 8.0,cudnn v5.1
GPU: NVIDIA GeForce RTX 2080 Ti
应该有不少人是在 ubuntu 14.04上编译的訪项目,我本来还担心 ubuntu 16.04会不会有问题,结果还是可以跑的。问题有不少,但是貌似都不是系统版本的问题。因为主要是自己搭环境,所以也没用到 docker 。
2. CUDA和 cudnn
因为作者在说明文档里面明确地说要 cuda8.0, cudnn v5.1(cudnn 6 and cudnn 7 my fail),虽然我自己已经装了 cuda 10.0了,现在得再装个 cuda 8.0,外加 cudnn v5.1。
2.1 cuda 8.0
直接在官网(https://developer.nvidia.com/cuda-80-ga2-download-archive)上,按照自身系统的配置,填入相应信息进行下载,我下载的本地安装包runfile(local)。

下载完成后,运行安装文件将 cuda 安装到指定目录即可。
$ sh cuda_8.0.61_375.26_linux-run
......此外省略 N 多行......
这里要特别注意的是当问到你是否需要安装 NVIDIA 显卡驱动一步的时候你要根据你的实际情况来选择。像我在我之前已经装好显卡驱动,所以这里我明确地给了个 no。
![]()
我将cuda 8.0安装在了/usr/local/cuda-8.0文件夹下面。
2.2 cudnn v5.1
依然是从 nvidia 的官网上(https://developer.nvidia.com/rdp/cudnn-archive)下载 cudnn v.5.1,应该是要注册账号才行。
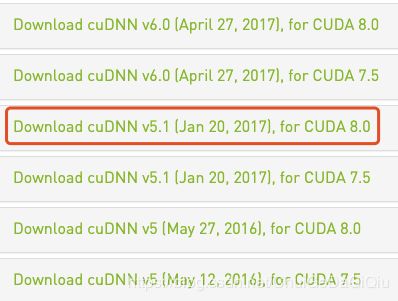
版本一大堆,选择自己需要的即可,毫无疑问我应该选 cuDNN v5.1 for CUDA 8.0。下载之后怎么安装,nvidia官方也很人性话地给出了说明,请见页面:https://docs.nvidia.com/deeplearning/sdk/cudnn-install/。
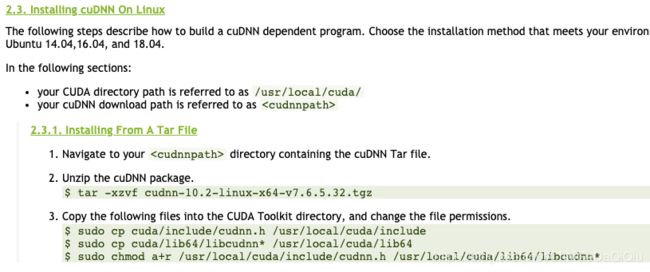
我解压后基本照抄上面的命令就行了,只是注意将目标cuda目录换成了我新装好的/usr/local/cuda-8.0。
3. OpenCV 的问题
作者给出的版本要求是 opencv 3.0,一开始我以为只能装 opencv 3.0.x。因为我系统里面装的是 opencv 3.4.0,我一开始不想再折腾一遍 opencv,我就抱着试试看的心态直接用我已经装好的 opencv 3.4.0 去编译caffe,然后在 cmake 的时候直接报了下面这个错误:
-- CUDA detected: 8.0
-- Found cuDNN: ver. 5.1.10 found (include: /usr/local/cuda-8.0/include, library: /usr/local/cuda-8.0/lib64/libcudnn.so)
-- Added CUDA NVCC flags for: sm_75
CMake Error at /usr/local/share/OpenCV/OpenCVConfig.cmake:108 (message):
OpenCV static library was compiled with CUDA 10.0 support. Please, use the
same version or rebuild OpenCV with CUDA 8.0
Call Stack (most recent call first):
cmake/Dependencies.cmake:72 (find_package)
CMakeLists.txt:43 (include)
意思就是说你 CUDA虽然用的是8.0,但是你 Opencv 静态库确是基于 CUDA 10.0环境编译的。确实我之前装 opencv 3.4.x 的时候是用的 cuda 10.0。为此,我不得不基于 CUDA 8.0环境又重新编译了 OpenCV。好了,下面就是我在在 ubuntu 16.04上编译 opencv 3.4.0的一般过程。
#安装依赖包
sudo apt-get update
sudo apt-get install libgtk2.0-dev
sudo apt-get install pkg-config
sudo apt-get install build-essential
sudo apt-get install cmake cmake-gui git libavcodec-dev libavformat-dev libswscale-dev
sudo apt-get install python-dev python-numpy libtbb2 libtbb-dev libjpeg-dev libpng-dev libtiff-dev libjasper-dev libdc1394-22-dev # 处理图像所需的包
sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev liblapacke-dev
sudo apt-get install libxvidcore-dev libx264-dev # 处理视频所需的包
sudo apt-get install libatlas-base-dev gfortran # 优化opencv功能
sudo apt-get install ffmpeg
#下载源码包并解压
https://github.com/opencv/opencv/archive/3.4.0.zip
unzip opencv-3.4.0.zip
#cmake 进行编译安装
cd opencv-3.4.0
mkdir build #新建编译目录
cd build
cmake ../ CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/opt/opencv-3.4.0 #指定安装目录
make -j8 #编译
make install #安装
ok 了!
4. 开始编译 textboxes_plusplus 的 caffe
好了,现在只剩下编译项目自带的 caffe 了。
git clone https://github.com/LeftThink/TextBoxes_plusplus.git #克隆项目到本地
cd TextBoxes_plusplus #进入目录
mdkri build #创建 build 目录,等下要在这里进行 cmake
cd build
cmake .. #开始 cmake,生成编译所需文件
make -j8 #开始编译
..........
(Use -Wno-deprecated-gpu-targets to suppress warning).
Scanning dependencies of target opencv_cudafilters
[ 27%] Building CXX object modules/cudafilters/CMakeFiles/opencv_cudafilters.dir/src/filtering.cpp.o
[ 27%] Linking CXX shared library ../../lib/libopencv_cudafilters.so
[ 27%] Built target opencv_cudafilters
Makefile:149: recipe for target 'all' failed
make: *** [all] Error 2
哟,报错了!opencv 的错!恍然大悟,我cmake 的时候没有指定刚刚用 cuda 8.0重新编译好的 opencv路径,因为我没有设置安装在默认路径下面,指定好路径再来cmake一次。
cmake -DOpenCV_DIR=/opt/opencv-3.4.0/share/OpenCV .. #指定好 opencv 再 cmake
make -j8 #再 make
.....编译成功了.....
5. 准备数据
这是要准备好训练用的 lmdb 数据。
6. 开始训练
在开始训练前注意修改 examples/text/modelConfig.py 文件,填写了你准备好的训练和测试数据lmdb 文件的路径(目录),如图:

作者提供了预训练模型,我下载了预训练模型,放置于 models目录下。
然后就可以跑跑看了!
python examples/text/train.py
...... ok ......