文章目录
- 慢查询日志
- 是什么
- 怎么玩
- 说明
- 查看是否开启及如何开启
- 默认
- 开启
- 那么开启了慢查询日志后,什么样的SQL才会记录到慢查询日志里面呢?
- Case
- 配置版
- 日志分析工具mysqldumpslow(重点)
- 查看mysqldumpslow的帮助信息
- 工作常用参考
- 批量数据脚本
- 建表
- 设置参数log_bin_trust_function_creators
- 创建函数,保证每条数据都不同(可用于压力测试,重点看)
- 随机产生字符串
- 随机产生部门编号
- 创建存储过程
- 创建往emp表中插入数据的存储过程
- 创建往dept表中插入数据的存储过程
- 调用存储过程
- dept
- emp
- 大量数据案例
- Show Profile
- 分析步骤
- 全局查询日志(只能在测试环境用,不能再生产环境用)
- 配置启用
- 编码启用
- 尽量不要在生产环境开启这个功能。(重要)
索引优化:https://blog.csdn.net/dataiyangu/article/details/89114013 还需要结合本节的查询截取分析
慢查询日志
是什么
• MySQL的慢查询日志是MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过阀值的语句,具体指运行时间超过long_query_time值的SQL,则会被记录到慢查询日志中。
• 具体指运行时间超过long_query_time值的SQL,则会被记录到慢查询日志中。long_query_time的默认值为10,意思是运行10秒以上的语句。
• 由他来查看哪些 SQL 超出了我们的最大忍耐时间值,比如一条 sql 执行超过 5 秒钟,我们就算慢 SQL ,希望能收集超过 5 秒的 sql ,结合之前 explain 进行全面分析。
怎么玩
说明
默认情况下,MySQL数据库没有开启慢查询日志 ,需要我们手动来设置这个参数。
当然,如果不是调优需要的话,一般不建议启动该参数 ,因为开启慢查询日志会或多或少带来一定的性能影响。慢查询日志支持将日志记录写入文件
查看是否开启及如何开启
默认
SHOW VARIABLES LIKE '%slow_query_log%';
默认情况下slow_query_log的值为OFF,表示慢查询日志是禁用的,
可以通过设置slow_query_log的值来开启
SHOW VARIABLES LIKE ‘%slow_query_log%’;

开启
set global slow_query_log=1;
使用set global slow_query_log=1开启了慢查询日志 只对当前数据库生效 , 如果MySQL重启后则会失效。

 
全局变量设置,对当前连接不影响
 
对当前连接立刻生效

如果要永久生效,就必须修改配置文件 my.cnf (其它系统变量也是如此)
修改my.cnf文件,[mysqld]下增加或修改参数
slow_query_log 和slow_query_log_file后,然后重启MySQL服务器。也即将如下两行配置进my.cnf文件
slow_query_log =1
slow_query_log_file=/var/lib/mysql/atguigu-slow.log
关于慢查询的参数slow_query_log_file ,它指定慢查询日志文件的存放路径, 系统默认会给一个缺省的文件host_name-slow.log (如果没有指定参数slow_query_log_file的话)
那么开启了慢查询日志后,什么样的SQL才会记录到慢查询日志里面呢?
这个是由参数long_query_time控制,默认情况下long_query_time的值为10秒,
命令:SHOW VARIABLES LIKE ‘long_query_time%’;
 
可以使用命令修改,也可以在my.cnf参数里 面修改。
假如运行时间正好等于long_query_time的情况,并不会被记录下来。也就是说,
在mysql源码里是 判断大于long_query_time,而非大 于等于 。
Case
- 查看当前多少秒算慢
SHOW VARIABLES LIKE 'long_query_time%';
- 设置慢的阙值时间
使用命令
set global long_query_time=1
修改为阙值到1秒钟的就是慢sql

修改后发现long_query_time并没有改变。
为什么设置后看不出变化?
需要重新连接或新开一个会话才能看到修改值。 SHOW VARIABLES LIKE ‘long_query_time%’;
或者通过set session long_query_time=1来改变当前session变量;

- 记录慢SQL并后续分析
实验一条慢sql

跟踪日志信息
- 查询当前系统中有多少条慢查询记录
show global status like '%Slow_queries%';

配置版
【mysqld】下配置: //my.cnf 或者my.ini
slow_query_log=1;
slow_query_log_file=/var/lib/mysql/atguigu-slow.log
long_query_time=3;
log_output=FILE
日志分析工具mysqldumpslow(重点)
在生产环境中,如果要手工分析日志,查找、分析SQL,显然是个体力活,MySQL提供了日志分析工具mysqldumpslow。
查看mysqldumpslow的帮助信息
mysqldumpslow --help
s: 是表示按照何种方式排序;
c: 访问次数
l: 锁定时间
r: 返回记录
t: 查询行数
al:平均锁定时间
ar:平均返回记录数
at:平均查询时间
t:即为返回前面多少条的数据;
g:后边搭配一个正则匹配模式,大小写不敏感的;
工作常用参考
得到返回记录集最多的10个SQL
mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log
得到访问次数最多的10个SQL
mysqldumpslow -s c -t 10 /var/lib/mysql/atguigu-slow.log
得到按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s t -t 10 -g “left join” /var/lib/mysql/atguigu-slow.log
另外建议在使用这些命令时结合 | 和more 使用 ,否则有可能出现爆屏情况
mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log | more
批量数据脚本
往表里插入1000W数据
建表
# 新建库
create database bigData;
use bigData;
#1 建表dept
CREATE TABLE dept(
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
dname VARCHAR(20) NOT NULL DEFAULT "",
loc VARCHAR(13) NOT NULL DEFAULT ""
) ENGINE=INNODB DEFAULT CHARSET=UTF8 ;
#2 建表emp
CREATE TABLE emp
(
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/
ename VARCHAR(20) NOT NULL DEFAULT "", /*名字*/
job VARCHAR(9) NOT NULL DEFAULT "",/*工作*/
mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*上级编号*/
hiredate DATE NOT NULL,/*入职时间*/
sal DECIMAL(7,2) NOT NULL,/*薪水*/
comm DECIMAL(7,2) NOT NULL,/*红利*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*部门编号*/
)ENGINE=INNODB DEFAULT CHARSET=UTF8 ;
设置参数log_bin_trust_function_creators
创建函数,假如报错:This function has none of DETERMINISTIC......
# 由于开启过慢查询日志, 因为我们开启了 bin-log, 我们就必须为我们的function指定一个参数。
show variables like 'log_bin_trust_function_creators';
set global log_bin_trust_function_creators=1;
# 这样添加了参数以后,如果mysqld重启,上述参数又会消失,永久方法:
windows下my.ini[mysqld]加上log_bin_trust_function_creators=1
linux下 /etc/my.cnf下my.cnf[mysqld]加上log_bin_trust_function_creators=1
创建函数,保证每条数据都不同(可用于压力测试,重点看)
随机产生字符串
//这里的两个$$对应下面的end$$,可以是两个四个八个,也可以是其他的符号,
//因为mysql默认的结尾是”;“现在需要把多行写在一块,改一下结尾,不再用”;“结束
//要用两个$才表示这段程序结束。
//也就是每次执行sql语句都需要通过$$才会结束
DELIMITER $$
//减建立函数 使我们自定义的函数名字(rand_string) RETURNS是返回值
CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
BEGIN ##方法开始
DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
##声明一个 字符窜长度为 100 的变量 chars_str ,默认值
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
##循环开始
WHILE i < n DO
SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
##concat 连接函数 ,substring(a,index,length) 从index处开始截取
SET i = i + 1;
END WHILE;
RETURN return_str;
END $$
#假如要删除
#drop function rand_string;
随机产生部门编号
#用于随机产生部门编号
DELIMITER $$
CREATE FUNCTION rand_num( )
RETURNS INT(5)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(100+RAND()*10);
RETURN i;
END $$
# 假如要删除
#drop function rand_num ;
创建存储过程
tip: 函数和存储过程的区别,函数有返回值,存储过程没有返回值
创建往emp表中插入数据的存储过程
DELIMITER $$
//创建存储过程,参数是从什么数字开始,到什么数字结束
CREATE PROCEDURE insert_emp10000(IN START INT(10),IN max_num INT(10))
BEGIN
DECLARE i INT DEFAULT 0;
#set autocommit =0 把autocommit设置成0 ;提高执行效率 ,例如,执行五十次insert,提交一次
SET autocommit = 0;
REPEAT ##重复 ,简而言之就是循环 相当于while true
SET i = i + 1;
INSERT INTO emp10000 (empno, ename ,job ,mgr ,hiredate ,sal ,comm ,deptno ) VALUES ((START+i) ,rand_string(6),'SALESMAN',0001,CURDATE(),FLOOR(1+RAND()*20000),FLOOR(1+RAND()*1000),rand_num());
UNTIL i = max_num ##直到 上面定义的max_num也是一个循环
END REPEAT; ##满足条件后结束循环
COMMIT; ##执行完成后一起提交
END $$
#删除
# DELIMITER ;
# drop PROCEDURE insert_emp;
创建往dept表中插入数据的存储过程
#执行存储过程,往dept表添加随机数据
DELIMITER $$
CREATE PROCEDURE insert_dept(IN START INT(10),IN max_num INT(10))
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO dept (deptno ,dname,loc ) VALUES (START +i ,rand_string(10),rand_string(8));
UNTIL i = max_num
END REPEAT;
COMMIT;
END $$
# 删除
# DELIMITER ;
# drop PROCEDURE insert_dept;
调用存储过程
dept
//将mysql的结尾符号修改回来,变成”;“
DELIMITER ;
CALL insert_dept(100,10);
emp
#执行存储过程,往emp表添加50万条数据
DELIMITER ; #将 结束标志换回 ;
CALL insert_emp(100001,500000);
CALL insert_emp10000(100001,10000);
 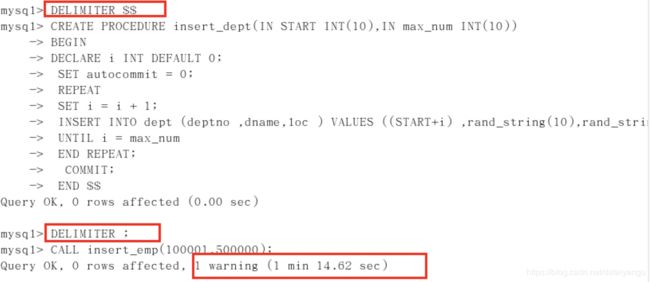

大量数据案例
#查询 部门编号为101的,且员工编号小于100100的用户,按用户名称排序
 
EXPLAIN SELECT * FROM emp WHERE deptno =101 AND empno <101000 ORDER BY ename ;

#结论:很显然,type 是 ALL,即最坏的情况。Extra 里还出现了 Using filesort,也是最坏的情况。优化是必须的。
#开始优化:
思路: 尽量让where的过滤条件和排序使用上索引
但是一共两个字段(deptno,empno)上有过滤条件,一个字段(ename)有索引
1、我们建一个三个字段的组合索引可否?
 

create index idx_dno_eno_ena on emp(deptno,empno,ename);
我们发现using filesort 依然存在,所以ename 并没有用到索引。
原因是因为empno是一个范围过滤,所以索引后面的字段不会再使用索引了。

所以
drop index idx_dno_eno_ena on emp;
但是我们可以把索引建成
create index idx_dno_ena on emp(deptno,ename);
 
也就是说empno 和ename这个两个字段我只能二选其一。
这样我们优化掉了 using filesort。
执行一下sql
 
速度果然提高了3倍。
…
但是
如果我们建立
create index idx_dno_eno on emp(deptno,empno);
而放弃ename使用索引呢?

果然出现了filesort,意味着排序没有用到索引。
我们来执行以下sql
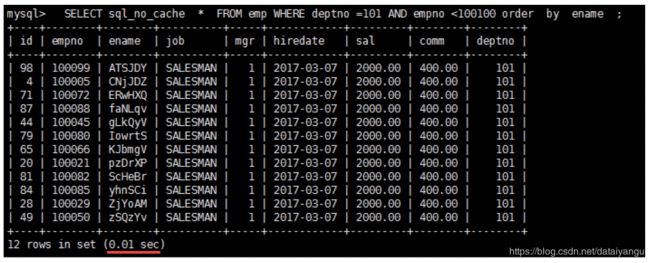
结果竟然有 filesort的 sql 运行速度,超过了已经优化掉 filesort的 sql ,而且快了近10倍。何故?
原因是所有的排序都是在条件过滤之后才执行的,所以如果条件过滤了大部分数据的话,几百几千条数据进行排序其实并不是很消耗性能,即使索引优化了排序但实际提升性能很有限。 相对的 empno<100100 这个条件如果没有用到索引的话,要对几万条的数据进行扫描,这是非常消耗性能的,所以索引放在这个字段上性价比最高,是最优选择。
结论: 当范围条件和group by 或者 order by 的字段出现二选一时 ,优先观察条件字段的过滤数量,如果过滤的数据足够多,而需要排序的数据并不多时,优先把索引放在范围字段上。反之,亦然。
Show Profile
是什么:是mysql提供可以用来分析当前会话中语句执行的资源消耗情况。可以用于SQL的调优的测量
官网:http://dev.mysql.com/doc/refman/5.5/en/show-profile.html
默认情况下,参数处于关闭状态,并保存最近15次的运行结果
分析步骤
- 是否支持,看看当前的mysql版本是否支持
Show variables like ‘profiling’;
默认是关闭,使用前需要开启
- 开启功能,默认是关闭,使用前需要开启
show variables like ‘profiling’;
set profiling=1;
或者
set profiling=on;

- 运行SQL
select * from emp group by id%10 limit 150000;
select * from emp group by id%20 order by 5 - 查看结果,show profiles;

Duratioin:持续的时间
Query:具体的操作
- 诊断SQL,show profile cpu,block io for query n (n为上一步前面的问题SQL数字号码);
参数备注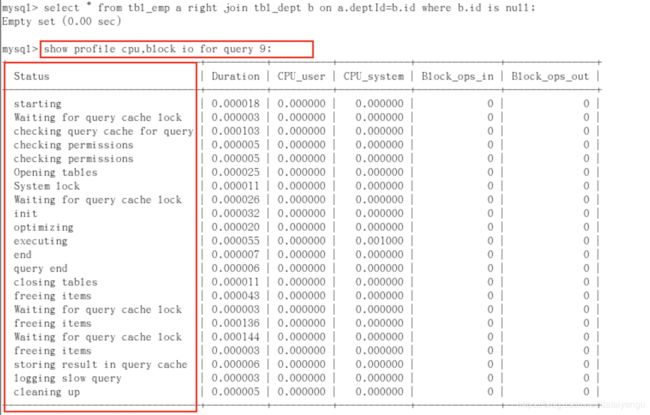
左边的status是sql语句的完整生命:连接、初始化、打开表、查找、缓存等
想看其他的修改参数即可如下:
type:
| ALL --显示所有的开销信息
| BLOCK IO --显示块IO相关开销
| CONTEXT SWITCHES --上下文切换相关开销
| CPU --显示CPU相关开销信息
| IPC --显示发送和接收相关开销信息
| MEMORY --显示内存相关开销信息
| PAGE FAULTS --显示页面错误相关开销信息
| SOURCE --显示和Source_function,Source_file,Source_line相关的开销信息
| SWAPS --显示交换次数相关开销的信息
- 日常开发需要注意的结论
如果status出现下面的就危险了
-
converting HEAP to MyISAM 查询结果太大,内存都不够用了往磁盘上搬了。
-
Creating tmp table 创建临时表
1 select * from emp group by id%20 limit 120000;
2 select * from emp group by id%20 order by 5
拷贝数据到临时表
用完再删除
- opying to tmp table on disk 把内存中临时表复制到磁盘,危险!!!
- locked
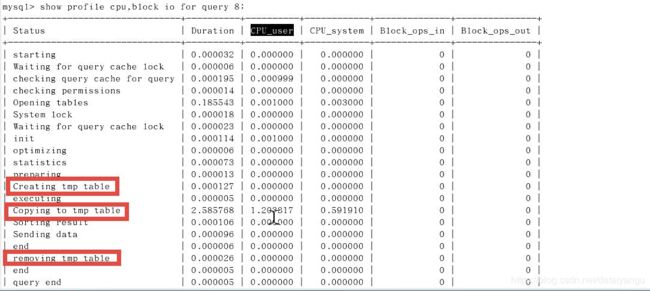
如上图就出现了临时表的相关操作。
全局查询日志(只能在测试环境用,不能再生产环境用)
配置启用
在mysql的my.cnf中,设置如下:
#开启
general_log=1
# 记录日志文件的路径
general_log_file=/path/logfile
#输出格式
log_output=FILE
编码启用
命令
• set global general_log=1;
#全局日志可以存放到日志文件中,也可以存放到Mysql系统表中。存放到日志中性能更好一些,存储到表中
• set global log_output='TABLE';
此后 ,你所编写的sql语句,将会记录到mysql库里的general_log表,可以用下面的命令查看
• select * from mysql.general_log;