文末赠书100本 | 当下最火爆的机器学习算法
![]()
1959年美国的塞缪尔(Samuel)设计了一个下棋程序,这个程序具有学习能力,它可以在不断的对奕中改善自己的棋艺。7年年,这个程序战胜了美国一个保持8年之久的常胜不败的冠军。包括最近火热的Alpha Zero,这些机器向人们展示了它们学习的能力,也揭示着这个社会中正在出现的变革,一些机器学习的算法也伴随着媒体报道逐步进入我们的视野,诸如:线性分析、神经网络、深度学习、支持向量机、降维分析、聚类分析、集成学习、决策树等。下面给大家简单介绍下当下比较火爆的几种简单又常用的机器学习算法。
1.线性模型
1.1线性回归
给定数据集,线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。其表达形式为y = w'x+e,e为误差服从均值为0的正态分布。
回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
1.2 对数几率回归(Logistic Regression)
logistic回归是一种广义线性回归(generalized linear model),因此与多重线性回归分析有很多相同之处。它们的模型形式基本上相同,都具有 w‘x+b,其中w和b是待求参数,其区别在于他们的因变量不同,多重线性回归直接将w‘x+b作为因变量,即y =w‘x+b,而logistic回归则通过函数L将w‘x+b对应一个隐状态p,p =L(w‘x+b),然后根据p 与1-p的大小决定因变量的值。如果L是logistic函数,就是logistic回归,如果L是多项式函数就是多项式回归。
logistic回归的因变量可以是二分类的,也可以是多分类的,但是二分类的更为常用,也更加容易解释,多类可以使用softmax方法进行处理。实际中最为常用的就是二分类的logistic回归。
2、支持向量机
支持向量机(Support Vector Machine,SVM)是Corinna Cortes和Vapnik等于1995年首先提出的,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。
在机器学习中,支持向量机(SVM,还支持矢量网络)是与相关的学习算法有关的监督学习模型,可以分析数据,识别模式,用于分类和回归分析。它是建立在统计学习理论的VC维理论和结构风险最小原理基础上的,根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折中,以求获得最好的推广能力。

给定训练样本空间D={(x_i,y_i)},y_i={+1,-1},i=1,…,n,基于训练集在样本空间中找到一个划分超平面,将不同类别的样本点划分开,划分的超平面可以通过方程来描述,其中为法向量,决定了超平面的方向,b为位移项,决定了超平面和原点之间的距离,样本空间中的任意点x到超平面的距离是距离超平面最近的几个训练样本点的称为支持向量,两个异类支持向量到支持向量之间的距离为 被称为间隔,预找到最大间隔划分超平面,即
被称为间隔,预找到最大间隔划分超平面,即 ,
,
s.t. ![]()
显然为了最大化间隔,仅需要最大化![]() ,等价于
,等价于![]() ,于是,得到支持向量机的基本型为
,于是,得到支持向量机的基本型为
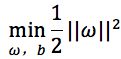
s.t. ![]()
3、神经网络
神经网络是具有适用性的简单单元组成的广泛并行的网络,它的组织能够模拟生物神经系统对真实世界物体作出的交互反应。

神经网络中最基本的模型是神经元模型,神经元接受来自n个其他神经元传递过来的输入信号,这些输入信号通过带权重的连接进行传递,神经元接受到的总输入值将与神经元的阀值进行比较,然后通过“激活函数”处理产生脑神经元输出。
理想中的激活函数有sgn(x)和sigmoid(x)。把多个这样的神经元按照一定的结构层次链接起来,就得到了神经元。以下是神经网络学习的几个相关概念:
选择模式:这将取决于数据的表示和应用。过于复杂的模型往往会导致问题的学习。
学习算法:在学习算法之间有无数的权衡。几乎所有的算法为了一个特定的数据集训练将会很好地与正确的超参数合作。然而,选择和调整的算法上看不见的数据训练需要显著量的实验。
稳健性:如果该模型中,成本函数和学习算法,适当地选择所得到的神经网络可以是非常健壮的。有了正确的实施,人工神经网络,可以自然地应用于在线学习和大型数据集的应用程序。其简单的实现和表现在结构上主要依赖本地的存在,使得在硬件快速,并行实现。
4、降维分析
4.1主成分分析是最常用的降维方法之一,考虑在正交属性的空间中,用一个超平面将所有样本点进行划分,这个超平面应该具有:最近重构性(样本点到达这个超平面的距离足够近)和最大可分性(样本点在这个超平面上的投影尽可能分开)。主成分分析的过程如下,首先对所有的样本点进行样本中心化,然后计算样本的协方差矩阵,之后对协方差矩阵惊醒特征值分析,最后取出最大的d’个特征值对应的特征向量,最终输出投影矩阵。
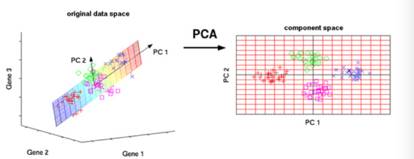
主成分分析是一种无监督的的线性降维方法,而监督降维方法中最著名的就是线性判别分析,通过最大化两个变量集合之间的相关性,可以得到典型相关分析等等。
4.2线性判别分析
线性鉴别分析的基本思想是将高维的模式样本投影到最佳鉴别矢量空间,以达到抽取分类信息和压缩特征空间维数的效果,投影后保证模式样本在新的子空间有最大的类间距离和最小的类内距离,即模式在该空间中有最佳的可分离性。因此,它是一种有效的特征抽取方法。使用这种方法能够使投影后模式样本的类间散布矩阵最大,并且同时类内散布矩阵最小。就是说,它能够保证投影后模式样本在新的空间中有最小的类内距离和最大的类间距离,即模式在该空间中有最佳的可分离性。

在过去的二十年中,人类收集、存储、运输、处理数据的能力取得了飞速提升,人类社会的各个角落都积累了大量数据,急需要能有效的对数据进行分析利用的算法,而机器学习恰好顺应了大时代对这个的迫切需求,该学科领域很自然地取得了巨大发展,受到了广泛关注。
今天,在计算机科学的诸多学科领域中,无论是多媒体、图形学,还是网络通讯、软件工程、乃至体系结构、芯片设计,都能找到机器学习技术的身影,尤其是在计算机视觉、自然语言处理等“计算机应用技术”领域,机器学习已经成为最重要的技术进步源泉之一。
哈哈~你想了解更多机器学习的相关知识成为一名Machine Learning大佬嘛~?!!下面要送出我们的福利了哟~
![]()
100本!
这本书发行三个月
就卖出了30000册
是目前自学机器学习
最重要的参考书目之一
《机器学习》by 周志华
作者介绍
周志华,南京大学计算机系教授,ACM杰出科学家,IEEE Fellow, IAPR Fellow, IET/IEEFellow, 中国计算机学会会士。国家杰出青年科学基金获得者、长江学者特聘教授。先后担任多种SCI(E)期刊执行主编、副主编、副编辑、编委等。中国计算机学会人工智能与模式识别专业委员会主任,中国人工智能学会机器学习专业委员会主任,IEEE计算智能学会数据挖掘技术委员会副主席。
内容简介
机器学习是计算机科学与人工智能的重要分支领域. 本书作为该领域的入门教材,在内容上尽可能涵盖机器学习基础知识的各方面. 全书共16章,大致分为3 个部分:第1部分(第1~3 章)介绍机器学习的基础知识;第2部分(第4~10 章)讨论一些经典而常用的机器学习方法(决策树、神经网络、支持向量机、贝叶斯分类器、集成学习、聚类、降维与度量学习);第3部分(第11~16 章)为进阶知识,内容涉及特征选择与稀疏学习、计算学习理论、半监督学习、概率图模型、规则学习以及强化学习等.每章都附有习题并介绍了相关阅读材料,以便有兴趣的读者进一步钻研探索。
本书可作为高等院校计算机、自动化及相关专业的本科生或研究生教材,也可供对机器学习感兴趣的研究人员和工程技术人员阅读参考。
废话少说
现在说说抽奖规则↓↓↓
![]()
SO EASY
1. 只需关注小象学院
2. 进入后台点击菜单栏“抽奖”
3. 然后按照要求操作就有机会中奖哦~
(没关注的同学扫下面二维码哦~)
