【Java8源码分析】NIO包-Buffer类:内存映射文件DirectByteBuffer与MappedByteBuffer(二)
转载请注明出处:http://blog.csdn.net/linxdcn/article/details/72903422
1 概述
上一篇NIO包-Buffer类:ByteBuffer与HeapByteBuffer(一)介绍了Buffer类的大致情况,还有两个特殊的类DirectByteBuffer和MappedByteBuffer未分析,这两个类的原理都是基于内存文件映射。
(1)系统IO调用
首先来看一下一般的IO调用。在传统的文件IO操作中,我们都是调用操作系统提供的底层标准IO系统调用函数 read()、write() ,此时调用此函数的进程(在JAVA中即java进程)由当前的用户态切换到内核态,然后OS的内核代码负责将相应的文件数据读取到内核的IO缓冲区,然后再把数据从内核IO缓冲区拷贝到进程的私有地址空间中去,这样便完成了一次IO操作。如下图所示。

注意两点:
- OS的read函数会在内核IO缓冲区中预读取数据,减少磁盘IO操作(Step2)
- Java的BufferedReader或BufferedInputStream的缓冲区的作用是减少系统调用(Step1)
(2)内存映射文件
内存文件映射适用于对大文件的读写。虚拟地址空间有一块区域: “Memory mapped region for shared libraries” ,这段区域就是在内存映射文件的时候将某一段的虚拟地址和文件对象的某一部分建立起映射关系,此时并没有拷贝数据到内存中去,而是当进程代码第一次引用这段代码内的虚拟地址时,触发了缺页异常,这时候OS根据映射关系直接将文件的相关部分数据拷贝到进程的用户私有空间中去,如下图所示。
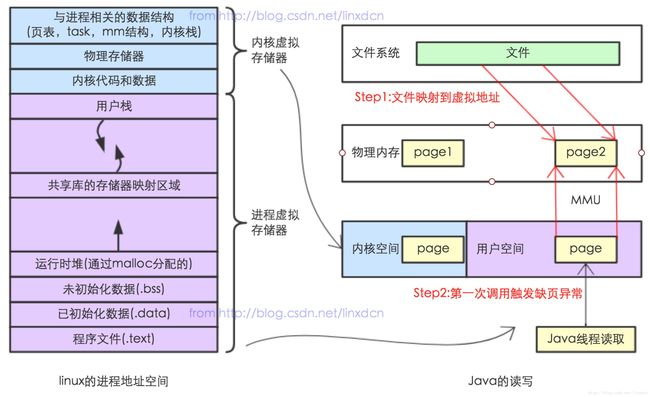
内存映射文件的效率比标准IO高的重要原因就是因为少了把数据拷贝到OS内核缓冲区这一步。
明白了内存映射文件的原理,下面就来分析DirectByteBuffer和MappedByteBuffer两个类。
2 MappedByteBuffer
MappedByteBuffer是一个抽象类,继承自ByteBuffer,本身比较简单
public abstract class MappedByteBuffer extends ByteBuffer
{
// 对应的文件描述符
private final FileDescriptor fd;
// 内存映射文件地址
long address;
// 构造函数
// 只有通过子类 DirectByteBuffer 的构造函数调用
MappedByteBuffer(int mark, int pos, int lim, int cap, // package-private
FileDescriptor fd)
{
super(mark, pos, lim, cap);
this.fd = fd;
}
MappedByteBuffer(int mark, int pos, int lim, int cap) { // package-private
super(mark, pos, lim, cap);
this.fd = null;
}
}2.1 Map映射实现
映射是通过FileChannel提供的map方法把文件映射到虚拟内存,通常情况可以映射整个文件,如果文件比较大,可以进行分段映射。Map的代码如下
public MappedByteBuffer map(MapMode mode, long position, long size) throws IOException {
int pagePosition = (int)(position % allocationGranularity);
long mapPosition = position - pagePosition;
long mapSize = size + pagePosition;
try {
// native方法,返回地址
addr = map0(imode, mapPosition, mapSize);
} catch (OutOfMemoryError x) {
// 如果失败,手动触发gc
System.gc();
try {
Thread.sleep(100);
} catch (InterruptedException y) {
Thread.currentThread().interrupt();
}
try {
// 再尝试映射
addr = map0(imode, mapPosition, mapSize);
} catch (OutOfMemoryError y) {
// After a second OOME, fail
throw new IOException("Map failed", y);
}
}
// 此时addr存放的内存映射文件地址,通过newMappedByteBuffer构造
int isize = (int)size;
Unmapper um = new Unmapper(addr, mapSize, isize, mfd);
if ((!writable) || (imode == MAP_RO)) {
return Util.newMappedByteBufferR(isize,
addr + pagePosition,
mfd,
um);
} else {
return Util.newMappedByteBuffer(isize,
addr + pagePosition,
mfd,
um);
}
}map函数的作用是把文件映射到内存中,获得内存地址addr,然后通过这个addr构造MappedByteBuffer类,代码如下:
static MappedByteBuffer newMappedByteBuffer(int size, long addr, FileDescriptor fd, Runnable unmapper) {
MappedByteBuffer dbb;
if (directByteBufferConstructor == null)
initDBBConstructor();
dbb = (MappedByteBuffer)directByteBufferConstructor.newInstance(
new Object[] { new Integer(size),
new Long(addr),
fd,
unmapper
}
return dbb;
}
// 访问权限
private static void initDBBConstructor() {
AccessController.doPrivileged(new PrivilegedAction() {
public Void run() {
Class cl = Class.forName("java.nio.DirectByteBuffer");
Constructor ctor = cl.getDeclaredConstructor(
new Class[] { int.class,
long.class,
FileDescriptor.class,
Runnable.class });
ctor.setAccessible(true);
directByteBufferConstructor = ctor;
}
});
} 实质上是通过构造DirectByteBuffer。
3 DirectByteBuffer
DirectByteBuffer继承了MappedByteBuffer,主要是实现了byte获得函数get等
private long ix(int i) {
return address + ((long)i << 0);
}
public byte get() {
return ((unsafe.getByte(ix(nextGetIndex()))));
}
public byte get(int i) {
return ((unsafe.getByte(ix(checkIndex(i)))));
}由于已经通过map0()函数返回内存文件映射的address,这样就无需调用read或write方法对文件进行读写,通过address就能够操作文件。底层采用unsafe.getByte方法,通过(address + 偏移量)获取指定内存的数据。
4 总结
(1)直接内存DirectMemory的大小默认为 -Xmx 的JVM堆的最大值,但是并不受其限制,而是由JVM参数 MaxDirectMemorySize单独控制。
(2)直接内存不是分配在JVM堆中。并且直接内存不受 GC(新生代的Minor GC)影响,只有当执行老年代的 Full GC时候才会顺便回收直接内存!而直接内存是通过存储在JVM堆中的DirectByteBuffer对象来引用的,所以当众多的DirectByteBuffer对象从新生代被送入老年代后才触发了 full gc。
(3)MappedByteBuffer在处理大文件时的确性能很高,但也存在一些问题,如内存占用、文件关闭不确定,被其打开的文件只有在垃圾回收的才会被关闭,而且这个时间点是不确定的。
参考
http://blog.csdn.net/mg0832058/article/details/5890688
http://blog.csdn.net/fcbayernmunchen/article/details/8635427
转载请注明出处:http://blog.csdn.net/linxdcn/article/details/72903422