TensorFlow官网教程Convolutional Neural Networks 难点详解
前言
断断续续花了几周的时间,终于把Tensorflow的学习教程Convolutional Neural Networks实现了。因为是深度学习的入门级小白,所以中间费了不少周折。
网上关于这个教程的帖子很多,大多是英文原版文档的中文译本,跟教程重复的我就不讲了,我就从我自己学习难点的角度,讲一下这篇教程吧。
这篇教程相较于之前的入门级tensorflow教程,算是高阶版,还是需要一定的tensorflow使用基础和机器学习知识积累的。
我觉得主要的难点集中在两大部分,第一是从文件读取数据,第二是使用训练变量的滑动平均值进行评估。
PS,这篇教程还提供了一个多GPU的版本,由于我只有一个GPU,所以没有进行这部分代码的实现,所以在这里就不多讲多GPU的部分了。
数据集是CIFAR-10数据集,属于十分类问题,不再多说。
这篇教程的重点在于实现了以下的功能
1、 基本的神经网络运算:convolution, rectified linear activations, max pooling, local response normalization
2、 神经网络训练过程参数的可视化
3、 计算学习参数的moving average(滑动平均)以及在评估过程使用滑动平均值提高预测的性能。
4、 实现学习率learning rate随着时间衰减
5、 使用queue runner从文件中读取数据
代码的组织
整个项目包括5个Python文件,其中 cifar_train.py 和 cifar_eval.py 是可直接运行,而其他文件是供它二者调用。
文件名 功能
cifar10_input.py 从硬盘上的二进制文件中读取数据
cifar10.py 构造模型
cifar10_train.py 在单个CPU或GPU上训练模型
cifar10_eval.py 评估模型
cifar10_multi_gpu_train.py 在多个GPU上训练模型
简单来说,整个项目就是要先实现输入数据的构造,再构建模型,然后写模型的训练过程,最后是评估过程。
输入数据的构造 – cifar10_input.py
这个文件主要包括以下的函数
函数名 功能
read_cifar10(filename_queue) 从filename_queue中读取二进制数据,构造成样本数据
_generate_image_and_label_batch() 构造batch_size样本集
distorted_inputs(data_dir, batch_size) 将样本数据进行预处理,构造成训练数据
inputs(eval_data, data_dir, batch_size) 将样本数据进行预处理,构造成测试数据
read_cifar10() 和 _generate_image_and_label_batch()是供distorted_inputs()和input()
调用的子函数
该文件主要做了以下三件事情:
1、 从二进制文件中读取数据,每次读取一个样本,并将二进制数据解析为tensor类型数据
2、 对1产生的样本数据进行预处理
3、 构造样本队列,将2产生的样本插入队列,每次运行distorted_inputs()和input(),就从队列中取出batch_size大小的数据集
下面详细说一下这个文件代码中几个比较难懂的地方。
输入数据的构造
我觉得这部分对于没有接触过的人来说,还是有一定的难度的。我就是属于之前不了解的,所以花了好几天的时间才研究明白。
之前的教程中,tensorflow的模型输入都是使用placeholder来实现的,但是这种情况不适用于大数据量的情况。因此本篇教程介绍了tensorflow的另一种数据读取机制,从文件中读取数据,这是一种更通用的方法。
大体的实现思路是,让tensorflow单独创建一个queue runner线程,它负责从文件中读取样本数据,并将其装载到一个队列中。我们只需要开启这个线程,在需要数据时从队列中获取想要的size的数据集就可以了,队列数据的装载由该线程自动实现的。
图像数据的预处理
原始图片经过了部分预处理之后,才送入模型进行训练或评估。
原始的图片尺寸为32*32的像素尺寸,主要的预处理是两步
1、 首先将其裁剪为24*24像素大小的图片,其中训练集是随机裁剪,测试集是沿中心裁
2、 将图片进行归一化,变为0均值,1方差
其中为了增加样本量,我们还对训练集增加如下的预处理
1、 随机的对图片进行由左到右的翻转
2、 随机的改变图片的亮度
3、 随机的改变图片的对比度
关于tf.train.shuffle_batch 中的参数 shuffle、min_after_dequeue
shuffle的作用在于指定是否需要随机打乱样本的顺序,一般作用于训练阶段,提高鲁棒性。
1、当shuffle = false时,每次dequeue是从队列中按顺序取数据,遵从先入先出的原则
2、当shuffle = true时,每次从队列中dequeue取数据时,不再按顺序,而是随机的,所以打乱了样本的原有顺序。
shuffle还要配合参数min_after_dequeue使用才能发挥作用。
这个参数min_after_dequeue的意思是队列中,做dequeue(取数据)的操作后,queue runner线程要保证队列中至少剩下min_after_dequeue个数据。
如果min_after_dequeue设置的过少,则即使shuffle为true,也达不到好的混合效果。
这个地方可能不太好理解,我尝试解释一下吧,但可能解释的不太好。
假设你有一个队列,现在里面有m个数据,你想要每次随机从队列中取n个数据,则代表先混合了m个数据,再从中取走n个。
当第一次取走n个后,队列就变为m-n个数据;
当你下次再想要取n个时,假设队列在此期间插进来了k个数据,则现在的队列中有
(m-n+k)个数据,则此时会从混合的(m-n+k)个数据中随机取走n个,。如果队列填充的速度比较慢,k就比较小,那你取出来的n个数据只是与周围很小的一部分(m-n+k)个数据进行了混合。
因为我们的目的肯定是想尽最大可能的混合数据,因此设置min_after_dequeue,可以保证每次dequeue后都有足够量的数据填充尽队列,保证下次dequeue时可以很充分的混合数据。
但是min_after_dequeue也不能设置的太大,这样会导致队列填充的时间变长,尤其是在最初的装载阶段,会花费比较长的时间。
模型的构建 cifar10.py
函数名 功能
_activation_summary 为激发函数的输出添加su mmary
_variable_on_cpu 在cpu上创建变量
_variable_with_weight_decay 为变量添加weight decay
distorted_inputs() 构造训练数据集
inputs() 构造测试数据集
inference() 构建模型,神经网络
loss() 定义模型的loss函数
_add_loss_summaries(total_loss) 为所有的loss项添加summary
并对所有的loss计算滑动平均
train() 定义训练过程
Maybe_download_and_extract() 从给定的网址上下载CIFAR_10数据集
distorted_inputs()和input()是cifar10_input.py文件中distorted_inputs()和input()函数的wrapper,只是添加了路径设置和数据类型转换操作。
构造的神经网络模型结构
层 简介
conv1 Convolution and rectified linear activation
pool1 Max pooling
norm1 Local response normalization
conv2 Convolution and rectified linear activation
norm2 Local response normalization
pool2 max pooling
local3 full connected layer with rectified linear activation
local4 full connected layer with rectified linear activation
softmax_linear linear transformation to produce logits
模型的构建这块没什么好讲的,在之前的tensorflow教程中都有涉及。
唯一没有涉及的就是 local response normalization,叫做局部响应归一化,简称LRN,这里简单的讲一下原理。
LRN的输入为 4D tensor , shape = [batch_size, height, width, depth],其中每个元素为一个标量
我们首先将4D tensor看作一个3D tensor, shape = [batch_size, height, width],
则此时的tensor的每个元素不再是一个标量值,而是一个 1D 的vector,即原4D Tensor中batch_size, height, width 维度坐标相同, depth维度坐标不同的一组数据组成了3D tensor的一个元素,类型为vector。
然后将3D tensor的每个vector元素按照给定的系数逐一进行规范化处理,就得到了LRN的输出。
简言之就是只沿depth这个维度进行规范化处理。
具体的细节请参考相关的论文。
模型的训练 cifar10_train.py
模型的loss函数使用的是交叉熵,为了正则化,又向loss函数添加了所有学习变量的weight decay 项,具体使用的是L2LOSS。
训练过程
每10步, 打印一次训练loss数据和时间数据
每100步,打印一下 summary
每1000步, 保存一次checkpoint
怎样实现 learning rate的衰减?
通过定义
lr=tf.train.exponential_decay((INITIAL_LEARNING_RATE,global_step, decay_steps,
LEARNING_RATE_DECAY_FACTOR, staircase=True)
然后将 lr传递给 GradientDescentOptimizer实现。
其中参数straircase = True,代表learning rate按照梯度函数衰减,
即global_step,每隔decay_steps, learing_rate会按照LEARNING_RATE_DECAY_FACTOR(衰减系数)衰减一次。
如果straircase = false, 代表 learning rate 按照连续函数衰减, 即每训练一次,learning rate 都会衰减一次
指数移动平均 ExponentialMovingAverage
指数移动平均,是指tensorflow会创建一个变量(一般称为shadow variable)来储存某个变量的指数移动平均值,在训练过程中,每训练一次,变量都会学习到一个新的值,则对应的shadow变量也会跟着更新一次(更新需要run update op) 。
在训练过程中,只会不断更新shadow 变量的值,而不会在模型中使用这个shadow变量。这个shadow变量一般是提供给评估过程使用的。
我理解的是,直接使用学习到的变量值进行评估,会导致评估有一定的波动性,如果使用变量的移动平均值替换变量进行评估,则会使评估过程更稳定,而且获得的评估效果也更好。
当然具体的细节讨论,还是要去看相关的论文。
模型的评估—- cifar10_eval.py
这应该是代码量最小的一个文件,结构也比较简单,只有两个函数
evaluate()负责创建和维护整个评估过程:
1、 创建测试集
2、 创建神经网络模型(和训练过程的一样)
3、创建saver ,saver 负责restore时shadow variable的值赋值给 variable
4、每隔固定的间隔,运行一次eval_once()
eval_once()负责完成一次评估,步骤是:
1、 从checkpoint中取出模型
2、 运行saver.restore将shadow variable的值赋值给 variable
3、 运行神经网络,对测试集的数据按批次进行预测
4、 计算整个测试集的预测精度
在以前的教程中,都是将训练和评估放在一个程序中运行,而在这个教程中,训练和评估是分开在两个独立的程序中进行的,之所以这样做,是因为评估过程不会直接使用训练学习到的模型参数(trainable variable的值),而是要使用的是变量的滑动平均(shadow variable)来代替原有变量进行评估。
具体的实现方法是,在训练过程中,为每个trainable variable 添加 指数滑动平均变量,然后每训练1000步就将模型训练到的变量值保存在checkpoint中,评估过程运行时,从最新存储的checkpoint中取出模型的shadow variable,赋值给对应的变量,然后进行评估
怎样实现训练和评估一起运行?
训练程序每运行一千步,就会保存模型的参数到checkpoint文件中。
评估程序运行时,会取出最新存储的checkpoint文件,从中复原模型。因此需要同时运行两个程序,才能使用评估程序实时的对训练程序进行评估。
在Linux下同时运行两个Python程序很简单,可以直接运行
python cifar_train.py & python cifar_eval.py
或者先运行 python cifar_train.py ,再打开另一个窗口运行 python cifar_eval.py
建议使用第二种方法,第一种方法中,两个程序的输出会显示在同一个界面里,我看着有点乱。
但有个问题,同时运行训练和评估程序,如果放在一块GPU上运行可能会造成内存不足。官网的教程中提到两种解决办法,
一,将训练和评估放在不同的GPU上执行
二,还是在一块GPU上执行,但是要交替执行两个程序,即当评估运行时,暂时挂起训练程序,评估跑完,再继续训练
第二种方法,我尝试了很久都没有成功,我的确做到了两个程序交替执行,但是当训练挂起的时候,GPU的资源并没有释放,不知道是我理解有误,还是挂起的方式不对
由于我只有一块GPU(人穷啊。。。),所以也不能使用方法一,所以我就采取了曲线救国的策略。
我将评估放在了CPU上运行,训练过程还是在GPU上运行。 因为评估每隔五分钟才跑一次,所以我觉得影响不大。
实际的训练过程
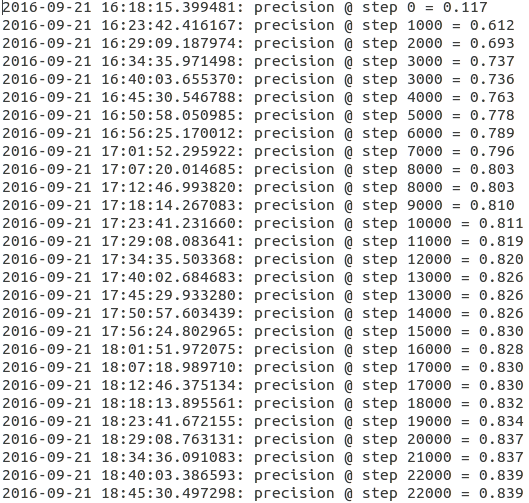
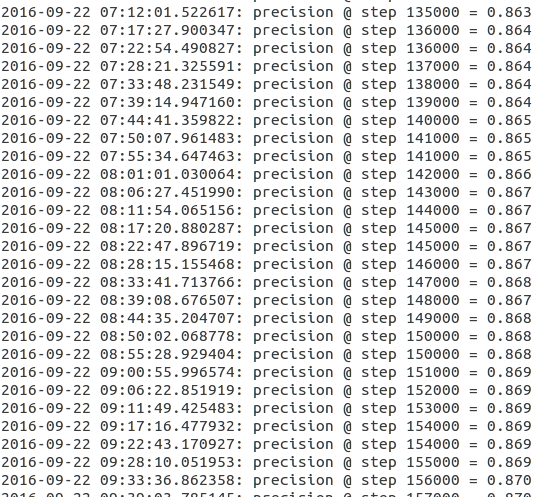
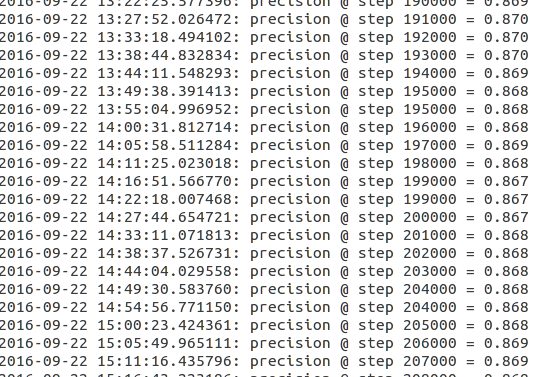
官方的教程中,设置的训练步骤是一百万步。
因为我的GPU太挫了,只有1G内存,所以算的比较慢,每个小时大概可以训练一万步,大概在训练到15万步的时候达到了峰值 0.870,之后精度开始没有明显的提升,在0.838-0.870之间徘徊。
跟教程中声明的最高精度还是温和的,说我的实现应该没有怎么出错。
最后贴几张tensorboard的图吧
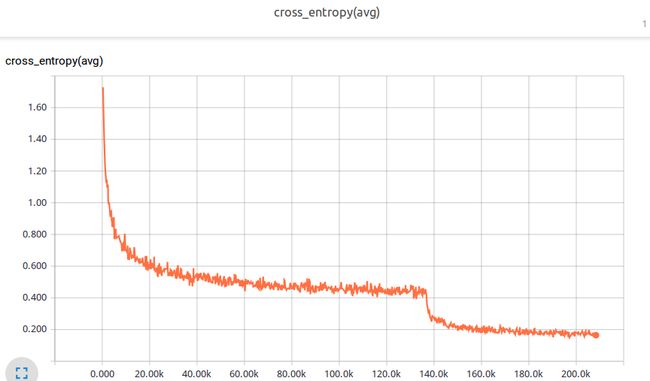
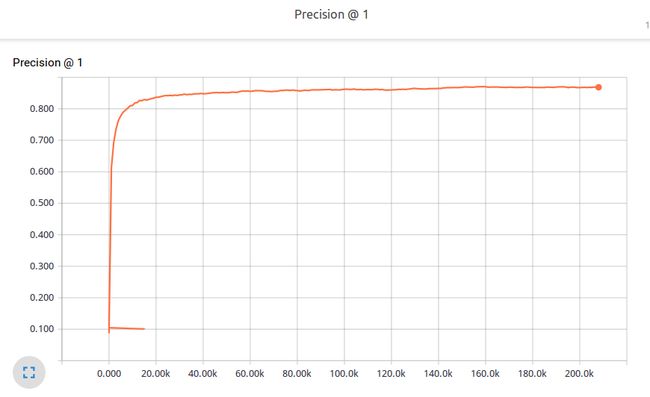
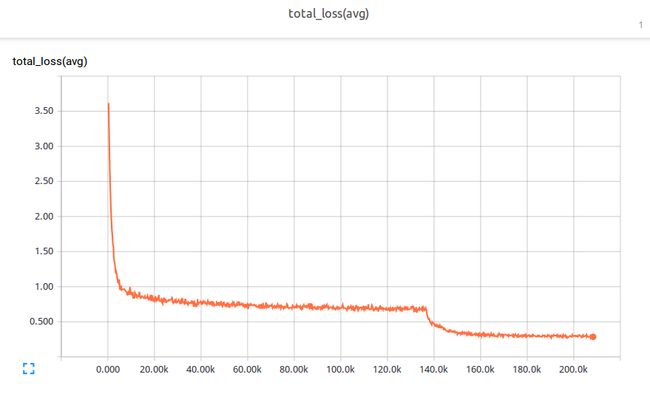
评估过程