机器学习总结——机器学习课程笔记整理
机器学习笔记整理
- 说明
- 基础点整理
- 1. 基础数学知识
- (1) 一些零七八碎的基础知识
- (2) 最优化相关问题
- (3) 概率论相关问题
- (4) 矩阵相关问题
- 2. 回归(线性回归、Logistic回归,Softmax回归)
- (1) 线性回归
- (2) Logistic回归
- (3) Softmax回归
- (4) AUC(ROC曲线下的面积)用来衡量分类效果
- 3. 树(决策书、随机森林、梯度下降决策树、XGBoost、提升树)
- (1) 熵的概念
- (2) 决策树
- (3) 随机森林 = Bagging + 决策树
- (4) 梯度下降决策树(GBDT) = Gradient Boosting + 决策树
- (5) XGBoost
- (6) 提升树 = AdaBoost + 决策树
- 4. SVM
- (1) 基本推导及求解过程
- (2) 线性SVM
- (3) 非线性SVM
- 5. 聚类
- (1) 相似度计算方法
- (2) Kmeans聚类方法
- (3) 层次聚类
- (4) 密度聚类
- (5) 谱聚类
- (6) 概率传递算法(半监督)
- 6. EM算法
- (1) 基本推导及求解过程
- (2) EM算法的通用形式
- 7. 贝叶斯网络
- (1) 朴素贝叶斯(GaussianNB)
- (2) 贝叶斯网络
- 8. 隐马尔科夫模型
- (1) 概率计算问题(前向后向算法)
- (2) 学习问题(Baum-Welch算法)
- (3) 预测问题(Viterbi算法)
- 相关问题
说明
之前看paper的时候,发现语义SLAM领域涉及到很多机器学习的知识,去年开学便花时间恶补了一阵机器学习的知识,主要参考的是小象学院的机器学习课程,结合《机器学习》一书,这篇博客主要是以课程的框架对知识点进行总结,类似于知识框图。写完才发现篇幅这么长,看起来可能不是很愉悦…下次注意,本人水平有限,错误欢迎指出。
基础点整理
1. 基础数学知识
(1) 一些零七八碎的基础知识
- 方向导数的概念
- 泰勒展开的概念
- Gamma函数的概念: ( x − 1 ) ! = ∫ 0 + ∞ t x − 1 e − t d t (x-1)! = \int_{0}^{+\infty}t^{x-1}e^{-t}dt (x−1)!=∫0+∞tx−1e−tdt,其意义在于阶乘在实数域上的推广
(2) 最优化相关问题
- 凸函数的定义(割线位于函数值上方: f ( θ x + ( 1 − θ ) y ) ≤ θ f ( x ) + ( 1 − θ ) f ( y ) f(\theta x+(1-\theta )y)\le\theta f(x)+(1-\theta)f(y) f(θx+(1−θ)y)≤θf(x)+(1−θ)f(y)),其主要性质是: (1)一阶可微判定( f ( y ) ≥ f ( x ) + f ( x ) ′ ( y − x ) f(y)\ge f(x)+f(x)'(y-x) f(y)≥f(x)+f(x)′(y−x));(2)二阶可微判定(一元函数二阶导数大于等于0,多元函数二阶导数即Hessen矩阵半正定)
- 拉格朗日乘子法求带约束不等式的最优化问题
(3) 概率论相关问题
- 基本公式:条件概率公式、全概率公式、贝叶斯公式
这里重点回顾下贝叶斯公式
P ( θ ∣ x ) = P ( x ∣ θ ) P ( θ ) P ( x ) P(\theta | x) = \frac{P(x | \theta)P(\theta)}{P(x)} P(θ∣x)=P(x)P(x∣θ)P(θ)
其中:
P ( θ ∣ x ) P(\theta | x) P(θ∣x)是在数据 x x x的支持下, θ \theta θ发生的概率;
P ( x ∣ θ ) P(x | \theta) P(x∣θ)是给定某参数 θ \theta θ后的概率分布,也就是所谓的似然概率;
P ( θ ) {P(\theta )} P(θ)是没有样本数据支持下, θ \theta θ发生的概率,也就是所谓的先验概率;
P ( x ) {P(x)} P(x)就是全概率咯。
可以理解为,本来我知道了某个状态发生的概率,现在在某个状态下,我获得了这么一组数据的分布,然后我来了一组新的数据分布,我可以推算出这个状态发生的概率(好像还是有点绕口…)
进一步,来提一下最大似然估计:
m a x P ( θ ∣ x ) = m a x P ( x ∣ θ ) P ( θ ) P ( x ) = m a x ( P ( x ∣ θ ) P ( θ ) ) = m a x P ( x ∣ θ ) maxP(\theta|x) = max\frac{P(x|\theta)P(\theta)}{P(x)}=max(P(x|\theta)P(\theta))=maxP(x|\theta) maxP(θ∣x)=maxP(x)P(x∣θ)P(θ)=max(P(x∣θ)P(θ))=maxP(x∣θ)
最大似然估计的问题是:我们已经获得了样本 x 1 , x 2 . . . x n x_1,x_2...x_n x1,x2...xn,那么对应的状态 θ \theta θ是多少?
最大似然估计的解释是: θ 1 , θ 2 . . . θ n \theta_1,\theta_2...\theta_n θ1,θ2...θn中 θ i \theta_i θi使得样本 x 1 , x 2 . . . x n x_1,x_2...x_n x1,x2...xn发生的概率最大,那么 x 1 , x 2 . . . x n x_1,x_2...x_n x1,x2...xn对应的状态就是 θ i \theta_i θi。
那么,假设 x 1 , x 2 . . . x n x_1,x_2...x_n x1,x2...xn为该总体采用得到的样本,因为 x 1 , x 2 . . . x n x_1,x_2...x_n x1,x2...xn独立同分布,所以他们的联合密度为:
L ( x 1 , x 2 . . . x n ; θ 1 , θ 2 . . . θ n ) = ∑ i = 1 n f ( x i ; θ 1 , θ 2 . . . θ n ) L(x_1,x_2...x_n;\theta_1,\theta_2...\theta_n) = \sum_{i=1}^{n}f(x_i;\theta_1,\theta_2...\theta_n) L(x1,x2...xn;θ1,θ2...θn)=i=1∑nf(xi;θ1,θ2...θn)
样本已经存在即 x 1 , x 2 . . . x n x_1,x_2...x_n x1,x2...xn已经固定, L ( x , θ ) L(x,\theta) L(x,θ)是关于 θ \theta θ的函数,即似然函数,求 θ \theta θ的值即求似然函数取最大值 - 概率分布:两点分布(0-1分布),二项分布( n n n次实验的两点分布),多项分布(二项分布的推广, x x x可以取多个值而不仅仅是0和1),泊松分布(可以由 e x e^x ex的泰勒展开推导获得,通常表示某一设施在一定时间内服务人数),均匀分布,指数分布(通常表示某一服务设施单一成员的等候时间,特点是无记忆性),正态分布(高斯分布),Beta分布(与Gamma函数阶乘相关,特点是有且只有一个最大值)
- 指数族分布:只有一个峰值,伯努利分布是指数族分布,有伯努利分布可以推出sigmod函数,高斯分布不是指数族分布,指数族分布具有类似的性质
- 事件的独立性:AB独立,则AB包含的互信息为0,且 P ( A ∣ B ) = P ( A ) = P ( A B ) / P ( B ) P(A|B) = P(A) = P(AB)/P(B) P(A∣B)=P(A)=P(AB)/P(B)
- 期望:定义是概率加权下的平均值,下列性质无条件成立:a. E ( k X ) = k E ( X ) E(kX)=kE(X) E(kX)=kE(X) b. E ( X + Y ) = E ( X ) + E ( Y ) E(X+Y)=E(X)+E(Y) E(X+Y)=E(X)+E(Y) 若 X Y XY XY相互独立: E ( X Y ) = E ( X ) E ( Y ) E(XY)=E(X)E(Y) E(XY)=E(X)E(Y)
- 方差:定义 V a r ( x ) = E [ x − E ( x ) ] 2 = E ( x 2 ) − E 2 ( x ) Var(x)=E{[x-E(x)]^2}=E(x^2)-E^2(x) Var(x)=E[x−E(x)]2=E(x2)−E2(x),下列性质无条件成立:a. V a r ( c ) = 0 Var(c)=0 Var(c)=0 b. V a r ( c + x ) = V a r ( x ) Var(c+x)=Var(x) Var(c+x)=Var(x) c. V a r ( k x ) = k 2 V a r ( x ) Var(kx)=k^2Var(x) Var(kx)=k2Var(x) 若 X Y XY XY相互独立: V a r ( X + Y ) = V a r ( X ) + V a r ( Y ) Var(X+Y)=Var(X)+Var(Y) Var(X+Y)=Var(X)+Var(Y)
- 协方差:定义 c o v ( x , y ) = E ( [ x − E ( x ) ] [ y − E ( y ) ] ) = E ( x y ) − E ( x ) E ( y ) cov(x,y)=E([x-E(x)][y-E(y)])=E(xy)-E(x)E(y) cov(x,y)=E([x−E(x)][y−E(y)])=E(xy)−E(x)E(y) 协方差为零不一定独立,但是独立一定协方差为零, 协方差为零则不相关,不相关则线性独立,协方差大于零正相关,协方差小于零负相关,协方差矩阵一定是正定阵。
- 相关系数:一次函数相关系数为1,二次函数相关系数为0
- 大数定律以及中心极限定理
(4) 矩阵相关问题
- SVD分解:通过对图像进行SVD分解,根据特征值排序,可以提取其主要特征。这里提及下SVD分解和PCA的关系:PCA在推导过程是对 X X T XX^T XXT进行特征分解,特征分解的结果是 A = Q Σ Q − 1 A = Q\Sigma Q^{-1} A=QΣQ−1 ,其中 Σ \Sigma Σ是特征值构成的矩阵,PCA的降维操作其实也相当于是对特征值排序,提取其主要特征。在实际应用当中,SVD分解结果和PCA是相同的,但SVD计算更加方便,因此通常采用SVD分解来实现PCA
参考:https://blog.csdn.net/dark_scope/article/details/53150883 - 矩阵的秩: 通过秩来判定方程组是否有解
- 正交矩阵:正交阵的列向量和行向量都是单位向量且两两正交,正交变换不改变向量的长度(旋转矩阵的特性),实对称阵的特征向量是实向量,实对称阵的不同特征值的特征向量正交
- 合同矩阵: P − 1 A P = P T A P = \bm{P^{-1}AP = P^{T}AP=} P−1AP=PTAP=对角阵,其中 P \bm{P} P为正交阵。和数据白化的推导有关:假设训练的数据是图像,图像中的相邻像素之间有很强的相关性,所以用于输入训练的输入是冗余的,白化的目的就是降低输入的冗余性。白化之后的数据具有如下性质:(1)特征之间相关性较低;(2)所有特征具有相同的方差。白化的计算公式为:
X P C A w h i t e , i = X r o t , i λ i X_{PCAwhite,i} = \frac{X_{rot,i}}{\sqrt{\lambda_i}} XPCAwhite,i=λiXrot,i
易知, X X T = U T D U , 由 上 式 有 X w h i t e = D − 0.5 X XX^T=U^TDU,由上式有X_{white} = D^{-0.5}X XXT=UTDU,由上式有Xwhite=D−0.5X,又 X w h i t e = U T D − 0.5 U X X_{white} = U^{T} {D^{-0.5}}UX Xwhite=UTD−0.5UX,因此 X w h i t e X w h i t e T = I X_{white}X_{white}^T=I XwhiteXwhiteT=I,即白化后的矩阵各个向量之间不相关。白化后的矩阵是正交阵。 - QR分解:主要用来求解矩阵的逆和特征值
- 向量求导:涉及矩阵和向量的求导不外乎五大类别(1)向量对标量,(2)标量对向量,(3)向量对向量,(4)矩阵对标量,(5)标量对矩阵
2. 回归(线性回归、Logistic回归,Softmax回归)
先说明一个原理:误差满足高斯分布可以推导出线性回归;误差满足二项分布可以推导出Logistic回归
(1) 线性回归
- 损失函数推导过程及求解过程(笔述,敲公式实在是太恶心了…): y = θ x + σ y = \theta x+\sigma y=θx+σ,其中 x , y x,y x,y都是样本向量, θ \theta θ是需要估计的参数, σ \sigma σ是误差,由中心极限定理推得其为高斯分布利用误差的高斯分布,由此根据前文所述的最大似然估计方法建立其似然函数 L ( θ ) L(\theta) L(θ),根据似然函数的一般解法,取对数即可定义其和 θ \theta θ相关部分为损失函数 J ( θ ) J(\theta) J(θ): J ( θ ) = 1 2 ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J(\theta) = \frac{1}{2} \sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})^2 J(θ)=21i=1∑m(hθ(x(i))−y(i))2对 J ( θ ) J(\theta) J(θ)对 θ \theta θ求导即可获得: θ = ( X T X ) − 1 X T Y \theta = (X^TX)^{-1}X^TY θ=(XTX)−1XTY时损失函数取得极小值,即获得最小二乘的结论,注意,这里可以获得一个解析解,而后面的Logistic回归都是没有解析解的对 J ( θ ) J(\theta) J(θ)对 θ \theta θ求导即可获得: θ = ( X T X ) − 1 X T Y \theta = (X^TX)^{-1}X^TY θ=(XTX)−1XTY时损失函数取得极小值,即获得最小二乘的结论,注意,这里可以获得一个解析解,而后面的Logistic回归都是没有解析解的
- 正则项:若 X T X X^TX XTX不可逆或者防止过拟合,可以增加 λ \lambda λ扰动,因为 X T X X^TX XTX是半正定的,在对角线上增加一个小扰动则一定正定,则一定可逆。其中在损失函数增加参数的绝对值( λ ∑ j = 1 n θ j 2 \lambda \sum_{j=1}^{n}\theta_j^2 λ∑j=1nθj2)和作为正则项为Lasso回归,增加参数的平方和(( λ ∑ j = 1 n ∣ θ j ∣ \lambda \sum_{j=1}^{n}|\theta_j| λ∑j=1n∣θj∣))作为正则项为Ridge回归,增加绝对值和平方和( λ ( ρ ∑ j = 1 n θ j 2 + ( 1 − ρ ) ∑ j = 1 n ∣ θ j ∣ ) \lambda( \rho\sum_{j=1}^{n}\theta_j^2+(1-\rho)\sum_{j=1}^{n}|\theta_j|) λ(ρ∑j=1nθj2+(1−ρ)∑j=1n∣θj∣))作为正则项为Elastic Net回归
- 梯度下降算法:几百维以下的参数可以直接导数求极值,几百维以上的最好利用梯度下降算法,沿着负梯度方向下降,更新 θ \theta θ使 J ( θ ) J(\theta) J(θ)变小梯度下降算法分为批量梯度下降算法(BGD)、 随机梯度下降算法(SGD) 、mini-batch梯度下降算法
- 衡量系数:MSE、RMSE、 R 2 R^2 R2 , R 2 R^2 R2越大越接近于1效果越好
(2) Logistic回归
- 损失函数推导过程及求解过程: y = 1 1 + e − θ T x y = \frac{1}{1+e^{-\theta^Tx}} y=1+e−θTx1,其中同理 x , y x,y x,y是样本向量, θ \theta θ是需要估计的参数。Logistic回归可以用回归来解决分类问题,及判定样本是否属于某一类。首先假定样本满足二项分布,即 P ( y = 1 ∣ x i ; θ ) = h ( x ) P ( y = 0 ∣ x i ; θ ) = 1 − h ( x ) P(y=1|x_i;\theta) = h(x) P(y=0|x_i;\theta) = 1-h(x) P(y=1∣xi;θ)=h(x)P(y=0∣xi;θ)=1−h(x),其中 h ( x ) h(x) h(x)为Logistic函数,根据极大似然估计求得 L ( θ ) L(\theta) L(θ),取对数即可以定义其损失函数 J ( θ ) J(\theta) J(θ)
J ( θ ) = ∑ i = 1 m ( y ( i ) l o g h ( x ( i ) ) + ( 1 − y ( i ) ) l o g ( 1 − h ( x ( i ) ) ) ) J(\theta) = \sum_{i=1}^{m}(y^{(i)}logh(x^{(i)})+(1-y^{(i)})log(1-h(x^{(i)}))) J(θ)=i=1∑m(y(i)logh(x(i))+(1−y(i))log(1−h(x(i))))按照梯度下降算法求得参数 θ \theta θ即可。这里解释下,线性回归对损失函数求导后等于零可以求得解析解,因此线性回归求 θ \theta θ有两种方式,但是Logistic回归没有解析解,因此只能用梯度下降算法。值得注意的是,Logistic回归的SGD形式和线性回归的SGD形式是一样的,因为他们都是指数族分布。
(3) Softmax回归
- 损失函数推导过程及求解过程:其推导过程和上述类似,求似然函数,然后定义损失函数,然后用随机梯度法进行求解,Softmax回归是用来解决多分类问题,其函数形式为 y = e x p ( θ k T x ) ∑ l = 1 k e x p ( θ l T x ) y= \frac{exp(\theta_k^Tx)}{\sum_{l=1}^{k}exp(\theta_l^Tx)} y=∑l=1kexp(θlTx)exp(θkTx)其他的就不在这里赘述了
(4) AUC(ROC曲线下的面积)用来衡量分类效果
3. 树(决策书、随机森林、梯度下降决策树、XGBoost、提升树)
(1) 熵的概念
- 信息熵:离散熵 H ( p ) = − ∑ i = 1 n P i l n P i H(p) = -\sum_{i=1}^{n}P_ilnP_i H(p)=−∑i=1nPilnPi以及连续熵 H ( p ) = − ∫ d = f ( x ) f ( x ) l n f ( x ) H(p) =- \int_{d=f(x)}f(x)lnf(x) H(p)=−∫d=f(x)f(x)lnf(x)
- 条件熵: H ( y ∣ x ) = H ( x , y ) − H ( x ) H(y|x) = H(x,y)-H(x) H(y∣x)=H(x,y)−H(x)
- 相对熵: D ( p ∣ ∣ q ) = ∑ ( p ( x ) l o g ( p ( x ) q ( x ) ) = E ( l o g ( p ( x ) q ( x ) ) ) D(p||q) = \sum(p(x)log(\frac{p(x)}{q(x)}) = E(log(\frac{p(x)}{q(x)})) D(p∣∣q)=∑(p(x)log(q(x)p(x))=E(log(q(x)p(x))) 其实就是对相对于 p ( x ) p(x) p(x)求期望,衡量两个随机变量之间的相对距离
- 互信息: I ( X ∣ Y ) = D ( P ( X , Y ) ∣ ∣ P ( X ) P ( Y ) ) = ∑ P ( x , y ) l o g P ( x , y ) P ( x ) P ( y ) I(X|Y) = D(P(X,Y)||P(X)P(Y))=\sum P(x,y)log\frac{P(x,y)}{P(x)P(y)} I(X∣Y)=D(P(X,Y)∣∣P(X)P(Y))=∑P(x,y)logP(x)P(y)P(x,y)
(2) 决策树
- 决策树的基本思想就是以信息上为度量构造一棵熵值下降最快的树,因为是最快,所以它是一种贪心算法
其中,ID3定义是信息增益下降最快,C4.5定义是信息增益率下降最快,CART是基尼系数下降最快。 - 决策树防止过拟合:剪枝(预剪枝(体现在代码里就是设置层数和节点数),后剪枝) 和随机森林(一棵树会过拟合,多棵树就可以抵消这种效果)
- 决策树可以用来进行分类,也可以用来进行进行回归(求一个叶节点下的均值,连起来即构成回归曲线)
(3) 随机森林 = Bagging + 决策树
-
Bagging算法过程如下:
a. 从原始样本集中使用Bootstraping方法随机抽取n个训练样本,共进行k轮抽取,得到k个训练集。(k个训练集之间相互独立,元素可以有重复)
b. 对于k个训练集,我们训练k个模型(这k个模型可以根据具体问题而定,比如决策树,KNN等)
c. 对于分类问题:由投票表决产生分类结果;对于回归问题:由k个模型预测结果的均值作为最后预测结果。(所有模型的重要性相同)
Bagging算法应用到决策数上即成为随机森林 -
投票机制(一票否决,少数服从多数,阈值表决,贝叶斯投票机制)和采样不均匀问题(欠采样,过采样,数据生成,提高权值)
-
随意森林的应用:计算样本间的相似读(位于同一节点则两个样本的相似度大),计算特征的重要度,Isolation forest(判断异常点)
(4) 梯度下降决策树(GBDT) = Gradient Boosting + 决策树
- 基本思想:首先初始化 F 0 ( x ) F_0(x) F0(x),利用最速下降的近似方法,即利用损失函数的负梯度在当前模型的值,作为回归问题中提升树算法的残差的近似值,拟合一个回归树,然后更新 F ( x ) F(x) F(x),具体细节可以参考:Gradient Boosted Decision Trees(GBDT)详解
其算法过程如下:

另外,这张图很好地说明了什么是Gradent Boosting,有助于加深理解:
(5) XGBoost
- 基本思想:如果不考虑工程实现、解决问题上的一些差异,XGBoost与GBDT比较大的不同就是目标函数的定义。XGBoost定义如下:

求解XGBoost的公式推导还是比较复杂的,这里主要讨论下XGBoost和GBDT的区别(主要):
参考机器学习算法中 GBDT 和 XGBOOST 的区别有哪些
(1)传统GBDT以CART作为基分类器,XGBoost还支持线性分类器,这个时候XGBoost相当于带L1和L2正则化项的Logistic回归(分类问题)或者线性回归(回归问题)
(2)传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数
(3)XGBoost在代价函数里加入了正则项,用于控制模型的复杂度,使学习出来的模型更加简单,防止过拟合,这也是XGBoost优于传统GBDT的一个特性。
(6) 提升树 = AdaBoost + 决策树
- 基本概念:前一个基本分类器分错的样本会得到加强,加权后的全体样本再次被用来训练下一个基本分类器。同时,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数。这里参考Adaboost 算法实例解析中的例子去理解就好了
4. SVM
(1) 基本推导及求解过程
SVM的目标是分割线离样本最近的距离取最大,如下图 建立目标函数如下: w ∗ , b ∗ = a r g m a x ( min i = 1 , 2 , n ( ( w T x ( i ) + b ) y ( i ) ∣ ∣ w ∣ ∣ 2 ) ) ⇒ w ∗ , b ∗ = a r g m i n 1 2 ∣ ∣ w ∣ ∣ 2 , s t . y i ( w T x i + b ) ≥ 1 , i = 1 , 2 , n w^*,b^* = argmax(\min \limits_{i=1,2,n}(\frac{(w^Tx^{(i)}+b)y^{(i)}}{||w||_2}))\Rightarrow w^*,b^* = argmin\frac{1}{2}||w||^2,st.y_i(w^Tx_i+b)\ge1,i=1,2,n w∗,b∗=argmax(i=1,2,nmin(∣∣w∣∣2(wTx(i)+b)y(i)))⇒w∗,b∗=argmin21∣∣w∣∣2,st.yi(wTxi+b)≥1,i=1,2,n通过等比例缩放 w w w的方法,使得两类点的函数值都满足 y ≥ 1 y \ge1 y≥1,将目标函数转变成带有约束条件的最小值,由此建立拉格朗日方程 L ( w , b , a ) = 1 2 ∣ ∣ w ∣ ∣ 2 + ∑ i = 1 n α i ( y i ( w T x i + b ) − 1 ) L(w,b,a)=\frac{1}{2}||w||^2+\sum_{i=1}^{n}\alpha_i(y_i(w^Tx_i+b)-1) L(w,b,a)=21∣∣w∣∣2+i=1∑nαi(yi(wTxi+b)−1)通过对偶问题转化,先求关于 w , b w,b w,b的最小值,再求此条件下的关于 α \alpha α的最大值 min w , b max α L ( w , b , α ) ⇒ max α min w , b L ( w , b , α ) \min \limits_{w,b} \max \limits_{\alpha} L(w,b,\alpha) \Rightarrow \max \limits_{\alpha}\min \limits_{w,b} L(w,b,\alpha) w,bminαmaxL(w,b,α)⇒αmaxw,bminL(w,b,α)后面的推导推导过程中还需要用到SMO算法,整个过程还是比较复杂的
建立目标函数如下: w ∗ , b ∗ = a r g m a x ( min i = 1 , 2 , n ( ( w T x ( i ) + b ) y ( i ) ∣ ∣ w ∣ ∣ 2 ) ) ⇒ w ∗ , b ∗ = a r g m i n 1 2 ∣ ∣ w ∣ ∣ 2 , s t . y i ( w T x i + b ) ≥ 1 , i = 1 , 2 , n w^*,b^* = argmax(\min \limits_{i=1,2,n}(\frac{(w^Tx^{(i)}+b)y^{(i)}}{||w||_2}))\Rightarrow w^*,b^* = argmin\frac{1}{2}||w||^2,st.y_i(w^Tx_i+b)\ge1,i=1,2,n w∗,b∗=argmax(i=1,2,nmin(∣∣w∣∣2(wTx(i)+b)y(i)))⇒w∗,b∗=argmin21∣∣w∣∣2,st.yi(wTxi+b)≥1,i=1,2,n通过等比例缩放 w w w的方法,使得两类点的函数值都满足 y ≥ 1 y \ge1 y≥1,将目标函数转变成带有约束条件的最小值,由此建立拉格朗日方程 L ( w , b , a ) = 1 2 ∣ ∣ w ∣ ∣ 2 + ∑ i = 1 n α i ( y i ( w T x i + b ) − 1 ) L(w,b,a)=\frac{1}{2}||w||^2+\sum_{i=1}^{n}\alpha_i(y_i(w^Tx_i+b)-1) L(w,b,a)=21∣∣w∣∣2+i=1∑nαi(yi(wTxi+b)−1)通过对偶问题转化,先求关于 w , b w,b w,b的最小值,再求此条件下的关于 α \alpha α的最大值 min w , b max α L ( w , b , α ) ⇒ max α min w , b L ( w , b , α ) \min \limits_{w,b} \max \limits_{\alpha} L(w,b,\alpha) \Rightarrow \max \limits_{\alpha}\min \limits_{w,b} L(w,b,\alpha) w,bminαmaxL(w,b,α)⇒αmaxw,bminL(w,b,α)后面的推导推导过程中还需要用到SMO算法,整个过程还是比较复杂的
(2) 线性SVM
分类完全正确的超平面不一定最好,过渡带越宽,泛化能力越好,为了防止过拟合,可以增加松弛因子 ξ \xi ξ,使得函数间隔加上松弛因子大于等于一,即 y i ( w T x i + b ) ≥ 1 − ξ i y_i(w^Tx_i+b)\ge1-\xi_i yi(wTxi+b)≥1−ξi目标函数变为 w ∗ , b ∗ = a r g m i n 1 2 ∣ ∣ w ∣ ∣ 2 + c ∑ i = 1 N ξ i , s t . y i ( w T x i + b ) ≥ 1 − ξ i , i = 1 , 2 , n w^*,b^* = argmin\frac{1}{2}||w||^2+c\sum_{i=1}^{N}\xi_i,st.y_i(w^Tx_i+b)\ge1-\xi_i,i=1,2,n w∗,b∗=argmin21∣∣w∣∣2+ci=1∑Nξi,st.yi(wTxi+b)≥1−ξi,i=1,2,n这样就会出现允许过渡带里面出现错误分类,解法就是将松弛因子作为约束条件加入拉格朗日乘子优化函数中,这样构造的SVM的损失函数为Hidge损失
注意,这里的参数 c c c控制着过度带的宽度, c c c为无穷大时代表对错误零容忍,此时过渡带最窄,退化为线性可分
(3) 非线性SVM
SVM的非线性化主要是通过加入核函数实现的,有多项式核函数、高斯核函数、sigmod核函数。可以简单理解为将上式中的 x i x_i xi映射以为 ϕ ( x i ) \phi(x_i) ϕ(xi),对应的 x x x映射为 ϕ ( x ) \phi(x) ϕ(x),具体参考核函数。
5. 聚类
(1) 相似度计算方法
欧式距离、杰卡德相似系数、余弦相似度、Pcason相似洗漱、相对熵、Hellinger距离
(2) Kmeans聚类方法
方法如下:
a. 选择出事的 k k k个样本类别中心 u 1 , u 2 . . . u n u_1,u_2...u_n u1,u2...un
b. 对每个样本 k k k,将其标记为距离类别中心最近的类别
c. 每个类别中心跟新为隶属该类别的所有样本的值
d. 重复b、c两步,直到类别中心的变化小于某阈值,终止条件可以是:迭代次数、簇中心变化率、最小平方误差
解决Kmeans算法对初值敏感问题方法:二分Kmeans算法、选择合适的聚类中心(远的被选中的概率高、近的被选中的概率低)、mini-batch Kmeans算法(所有样本中随机选择部分样本)
(3) 层次聚类
- 凝聚的层次聚类:基本原理是一种自底向上的策略,首先讲每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到某个终结条件被满足
- 分类的层次聚类:将所有的对象放置于一个簇中,然后逐渐细分越来越小的簇,直到达到了某个终结条件
(4) 密度聚类
基本思想是只要样本点的密度大于某个阈值,则将该样本添加到最近的簇中
- DBSCAN算法:簇的定义为密度相连的样本点的最大集合,可在有噪声的数据中产生任意形状的聚类,噪声的定义为不包含在任何簇中的对象,阈值小则会将噪声生成簇
- 密度最大值聚类:局部密度: ρ i = ∑ j x ( d j − d e ) , x ( d ) = 1 , x > 0 \rho_i = \sum_{j}x(d_j-d_e),x(d)=1,x>0 ρi=j∑x(dj−de),x(d)=1,x>0高局部密度点的距离(比自己密度还要大的最近样本点点的距离): δ i = min ρ j > ρ i ( d i j ) \delta_i = \min \limits_{\rho_j>\rho_i}(d_{ij}) δi=ρj>ρimin(dij)局部密度很大,同时高局部密度距离很大,被认为是簇的中心
(5) 谱聚类
- 谱的定义:实对称阵的特征值都是实数,实对称阵的不同特征值之间的特征向量正交。方阵作为线性算子,它的所有特征值的全体统称为方阵的谱,谱半径即最大的特征值
- 谱聚类就是通过对样本的拉普拉斯矩阵和特征向量进行聚类
首先定义两个样本的相似度 w i j = e x p ∣ ∣ x i − x j ∣ ∣ 2 2 2 σ 2 w_{ij} = exp{\frac{||x_i-x_j||_{2}^{2}}{2\sigma^2}} wij=exp2σ2∣∣xi−xj∣∣22根据相似度定义邻接矩阵为 W = ( w i j ) i , j = 1 , 2... n , i = j , w i j = 0 W=(w_{ij})_{i,j=1,2...n},i=j,w_{ij}=0 W=(wij)i,j=1,2...n,i=j,wij=0,进一步定义顶点的度为 d i = ∑ i = 1 n ( w i j ) d_i=\sum_{i=1}^{n}(w_{ij}) di=∑i=1n(wij),度矩阵 D D D为对角阵。拉普拉斯矩阵为 L = D − W L=D-W L=D−W,拉普拉斯矩阵是对称半正定矩阵,最小特征值是0, 对应的特征向量是 I I I。谱聚类即找到一个划分,使得随机游走在相同的簇中停留而几乎不会游走到其他簇
(6) 概率传递算法(半监督)
将标记样本的标记通过一定概率传递给未标记样本,直到最终收敛
6. EM算法
(1) 基本推导及求解过程
利用EM算法求解高斯混合模型GMM:随机变量 x x x,由 k k k个高斯分布混合而成,各个高斯分布发生概率满足多项式分布为 ϕ 1 , ϕ 2 . . . ϕ i \phi_1,\phi_2...\phi_i ϕ1,ϕ2...ϕi,参数分别为 μ i , ∑ i \mu_i,\sum_i μi,∑i,观测到随机变量 x x x的一系列样本 x ( 1 ) , x ( 2 ) . . . x ( m ) x^{(1)},x^{(2)}...x^{(m)} x(1),x(2)...x(m),求 ϕ , μ , ∑ \phi,\mu,\sum ϕ,μ,∑。EM算法可以由最大似然估计推得,似然函数为:

其中 z ( i ) z^{(i)} z(i)代表样本 x ( i ) x^{(i)} x(i)属于哪个高斯分布获得的, p ( z ( i ) = j ) = ϕ j p(z^{(i)}=j)=\phi_j p(z(i)=j)=ϕj就是说样本 x ( i ) x^{(i)} x(i)属于第 j j j个高斯分布组分的概率为 ϕ j \phi_j ϕj, z ( i ) z^{(i)} z(i)是一个隐变量。如果我们知道 z ( i ) z^{(i)} z(i)的取值的话,问题将简化为:

因此EM算法采用的是迭代算法,先设置一个初值,其中
E步(判断样本 x ( i ) x^{(i)} x(i)属于组分 j j j的概率):
![]()
M步(估计第 j j j个组分的参数以及整体 j j j组分所占比例):
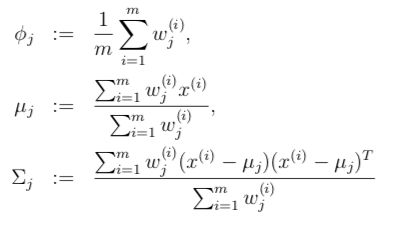
如何感性地理解EM算法很好地解释了这一过程
(2) EM算法的通用形式
主要的想法是计算对数似然函数的霞姐,求该下界的最大值,重复该过程,直到收敛局部最小值
E步骤:根据参数θθ初始值或上一次迭代所得参数值来计算出隐性变量的后验概率(即隐性变量的期望),作为隐性变量的现估计值: Q i ( z ( i ) ) : = P ( z ( i ) ∣ x ( i ) , θ ) ) Q_i(z^{(i)}) := P( z^{(i)}|x^{(i)},\theta)) Qi(z(i)):=P(z(i)∣x(i),θ)) M步骤:将似然函数最大化以获得新的参数值: θ : = a r g max θ ∑ i = 1 m ∑ z ( i ) Q i ( z ( i ) ) l o g P ( x ( i ) , z ( i ) ∣ θ ) \theta : = arg \max \limits_{\theta}\sum\limits_{i=1}^m\sum\limits_{z^{(i)}}Q_i(z^{(i)})log{P(x^{(i)}, z^{(i)}|\theta)} θ:=argθmaxi=1∑mz(i)∑Qi(z(i))logP(x(i),z(i)∣θ) 这和上面求解高斯混合模型的过程是对应得上的,但是高斯混合模型只是它的最典型的应用之一,其应用包括
(1)支持向量机的SMO算法;(2)混合高斯模型;(3)K-means;(4)隐马尔科夫模型
7. 贝叶斯网络
(1) 朴素贝叶斯(GaussianNB)
朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。通俗来说,就好比这么个道理,你在街上看到一个黑人,我问你你猜这哥们哪里来的,你十有八九猜非洲。为什么呢?因为黑人中非洲人的比率最高,当然人家也可能是美洲人或亚洲人,但在没有其它可用信息下,我们会选择条件概率最大的类别,这就是朴素贝叶斯的思想基础。其公式如下: p ( C ∣ F 1 , … , F n ) = 1 Z p ( C ) ∏ i = 1 n p ( F i ∣ C ) p(C\vert F_{1},\dots ,F_{n})={\frac {1}{Z}}p(C)\prod _{{i=1}}^{n}p(F_ {i}\vert C) p(C∣F1,…,Fn)=Z1p(C)i=1∏np(Fi∣C)其中 C C C为所分的类别,比如说是什么任重, F i F_i Fi是特征变数,比如说是皮肤颜色、身高等。其他的例子可以参考朴素贝叶斯分类器的应用,朴素贝叶斯模型有三种典型模型:多项式模型(文本分类)、高斯模型、伯努利模型,模型的不同其实指的就是 p ( F i ∣ C ) p(F_i|C) p(Fi∣C)的不同
(2) 贝叶斯网络
把某个研究系统中涉及的随机变量,根据是否条件独立绘制到一个有向图中即贝叶斯网络,最大的用处应该是在自然语言处理中,比如LDA主题模型,因为这个暂时我在我的研究领域内,所以我没有做太深的研究。
8. 隐马尔科夫模型
隐马尔科夫模型随机生成的状态随机序列 x ( i ) x(i) x(i),成为称为状态序列;每个状态生成一个观测 y ( i ) y(i) y(i),称为观测随机序列, x ( t − 1 ) , x ( x ) x(t-1),x(x) x(t−1),x(x)是不可以被观测的, y ( t − 1 ) , y ( t ) y(t-1),y(t) y(t−1),y(t)是不独立的。

用于描述关于时序的概率模型 λ = ( A , B , π ) \lambda = (A,B,\pi) λ=(A,B,π),其中 A A A为状态转移概率分布, B B B为观测概率分布, π \pi π为初始概率分布
(1) 概率计算问题(前向后向算法)
给定模型参数 λ \lambda λ和观测序列 O = ( O 1 , O 2 . . . O n ) O={(O_1,O_2...O_n)} O=(O1,O2...On),计算该模型下观测序列 O O O出现的概率 P ( O ∣ λ ) P(O|\lambda) P(O∣λ)
(2) 学习问题(Baum-Welch算法)
已知序列 O = ( O 1 , O 2 . . . O n ) O={(O_1,O_2...O_n)} O=(O1,O2...On),估计模型 λ \lambda λ的参数,使得该模型下观测序列 P ( O ∣ λ ) P(O|\lambda) P(O∣λ)最大。若训练数据包括观测序列和状态序列,则HMM的学习非常简单,采用最大似然估计即可,属于监督学习,若只有观测数据,需要采用EM算法,属于非监督学习
(3) 预测问题(Viterbi算法)
已知 λ \lambda λ和 O = ( O 1 , O 2 . . . O n ) O={(O_1,O_2...O_n)} O=(O1,O2...On),求给定观测序列条件概率 P ( I ∣ O , λ ) P(I|O,\lambda) P(I∣O,λ)的最大序列 I I I
相关问题
本来想自己总结的,但是发现了一个很牛逼的博客BAT机器学习面试1000题系列,身下篇幅就不在这里再总结了